我要进大厂之大数据ZooKeeper知识点(2)

01 我们一起学大数据
接下来是大数据ZooKeeper的比较偏架构的部分,会有一点难度,老刘也花了好长时间理解和背下来,希望对想学大数据的同学有帮助,也特别希望能够得到大佬的批评和指点。
02 知识点
第10点:说一说ZooKeeper集群架构
首先呢,ZooKeeper集群是一个主从架构,在ZooKeeper集群中有三个角色:leader,follower,observer。那知道了这三个东西,必须要了解它们的概念。
leader,领导者,为客户端提供读写服务,维护集群状态。
follower,跟随者,为客户端提供读写服务,向leader汇报自己的状态信息,同时也要参与“过半写成功”和leader选举。
observer,观察者,它是特殊的follower,为客户端提供读写服务,向leader汇报自己的状态信息,但不参与“过半写成功”和leader选举。
那客户端是如何和ZooKeeper集群进行读操作的?
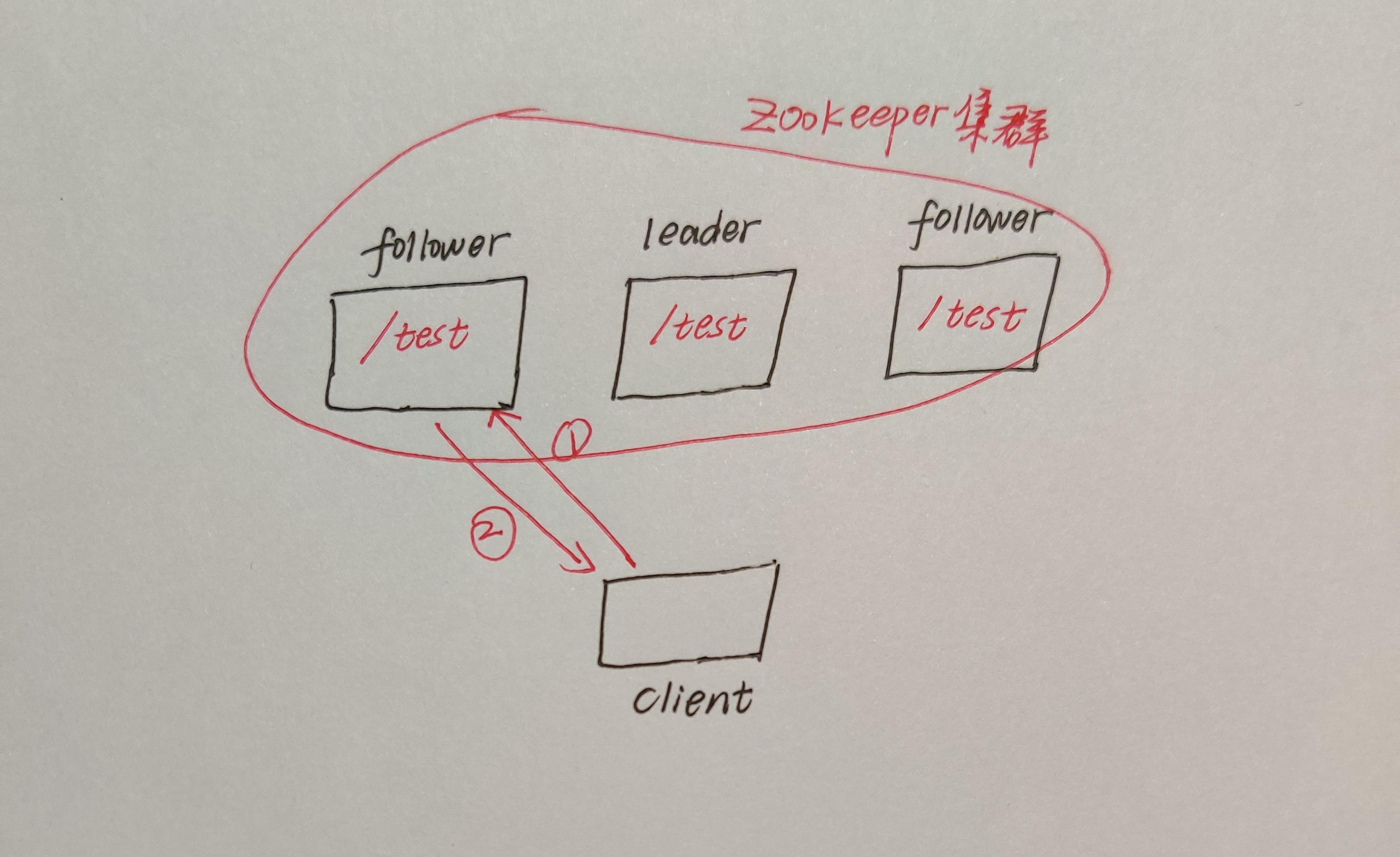
看到这张图,就会感觉到ZK的读操作很简单,
就是客户端先和ZK集群中的某个服务器建立session,然后直接从这个ZK服务器读取数据,读完后返回到客户端,最后关闭session。就是这么简单!
那客户端是如何和ZK集群进行写操作的呢?
有没有人觉得也会很简单,老刘当初就是这样想的,当看完之后就发现自己还是太肤浅了,ZK的写操作比ZK的读操作要复杂好多好多。
先分享出自己看到的一个特别好的例子,这个例子在老刘看来真的非常形象的表达出了ZK写操作的过程。
1、就是有一个富豪来到银行,对一个柜台小姐姐说我昨天在这里存钱,你们少给我存了1000万,现在需要你们给我加进去。
2、那这么大的金额,这个柜台小姐姐肯定是没有权限进行操作的,她就会汇报给经理,那经理也不能随便加,他为了让自己的操作服众,他就会征求自己所有下属的意见。
3、如果大多数人都同意加,经理就会做出决定,同意此事。并且会告知所有下属,让他们记下这件事。
4、那么最开始的柜台小姐姐就会通知富豪操作成功,加了1000万。
看完这个例子,大家接下里再看ZK写操作,就会发现几乎一模一样。

① 客户端向ZK集群写入数据,例如create /test;与集群中的最左边的follower建立session会话。
② follower就会将写请求转发给leader。
③ leader收到消息后,就会发出proposal提案创建/test,然后通知每个follower先记下要创建/test。
④ 现在就开始进行投票,是否允许创建/test这个写操作。如果在这个集群中,有个超过半数(quorum)的人同意,也同意的人包括leader自己,这个部分会在后面详细介绍,那么leader就会commit提案,leader就会在本地创建ZNode节点/test。
⑤ 之后leader就会通知所有follower,也commit提案,在各自的本地创建ZNode节点/test。
⑥ 结束上述所有操作后,最左边的follower就会响应客户端。
怎么样,怎么样,是不是和举的例子非常相似,哈哈哈!
第11点:ZK集群中leader选举
leader选举分为两种选举,一种是全新选举,另一种是非全新选举。这里老刘就仔细讲讲全新选举,非全新选举和全新选举大致相同,大家可以去自行搜索。
在leader选举中,有个非常重要的原则,就是超过半数(quorum)Server启动后,才能选举leader。这个半数如何计算呢?举个例子,在3台机器组成的ZK集群中,半数等于3/2+1=2,就是集群服务器的个数除以2,再加上1。
在选举过程中,每个服务器都会投票,投票信息是这种结构(sid, zxid),在全新leader选举中,每个服务器的初始投票信息为server1-(1, 0),server2-(2, 0),server3-(3, 0)。
那究竟如何判断选举得到leader呢?就是server1投票(sid1, zxid1),server2投票(sid2, zxid2),就会进行比较,先比较zxid,谁大谁是leader;如果zxid相等,就会比较sid,sid谁大谁是leader。
上述基本讲完了leader选举中的知识点,接下里就让老刘详细说一遍leader选举步骤,还是在3台机器组成的ZK集群中讲这个选举。
先假设按照ZK1、ZK2、ZK3的顺序依次启动,那么半数就为2了。
1、启动ZK1后,投票给自己,vote信息(1,0),没有过半数,不能进行选举。
2、再启动ZK2;ZK1和ZK2票投给自己及其他服务器;ZK1的投票为(1, 0),ZK2的投票为(2, 0)。
3、现在集群个数达到2,就可以进行选举了,先开始处理投票。ZK1会把投给自己的票(1,0)与ZK2传过来的票(2,0)比较;利用leader选举公式,因为zxid都为0,相等;所以判断sid最大值;2>1;所以ZK1更新自己的投票为(2, 0)。同样的道理,ZK2也进行同样的逻辑,ZK2更新自己的投票为(2,0)。
4、处理完投票后,再次发起投票选举。现在ZK1、ZK2上的投票都是(2,0),那么ZK2就会被选为leader,接着就会更改服务器状态,更改ZK2为Leader;更改ZK1状态为Follower。
5、最后当K3启动时,它发现集群中已经有了Leader,就不会进行选举,直接变为follower。
第12点:仲裁qurorum知识点总结
老刘在这先说一句,ZAB算法,老刘以后再讲,现在还没搞清楚。
什么是仲裁?
发起proposal时,只要大多数派同意,就能够生效。
为什么要仲裁?
就是不需要所有的服务器都响应,proposal就能生效,提高了集群的响应速度,也比较合理。
quorum数如何选择?
在3台机器组成的ZK集群中,半数等于3/2+1=2,就是集群服务器的个数除以2,再加上1。
第13点:ZooKeeper工作原理
读写操作已经在第10点讲述,现在开始讲讲ZooKeeper状态同步。在完成leader选举之后,ZK就会进入ZooKeeper之间的状态同步。
那究竟是如何进行状态同步的呢?让老刘先把脑子里记得的东西写出来,不急!
1、leader会构建一个NEWLEADER封包,在这个NEWLEADER封包中包含着这个leader的最大zxid,然后广播给其他follower。
2、follower接收到后,就会用自己的最大的zxid进行比较,如果自己的最大zxid小于leader的,那就说明自己的数据不是最新的,需要和leader状态进行同步;否则不需要。
3、如果需要同步,那leader就会给需要同步的每个follower创建LearnerHandler线程,这个线程就会负责数据同步的请求。
4、leader主线程就会等待LearnHandler线程处理完结果。只有大多数follower完成同步时,leader才开始对外响应写的请求。
5、上述是大致的状态同步过程,但是在第4步仅仅简单描述了一下LearnerHandler线程,接下里就详细说一下在LearnerHandler线程的流程:
① 首先会接收follower的封包FOLLOWERINFO,包含这个follower的最大zxid。
② follower的最大zxid与leader最大zxid比较,若相等,说明当前follower是最新的;
③ 在判断期间,还要判断有没有新提交的proposal。如果有,就会发送DIFF封包将有差异的数据同步过去。同时将follower中没有的数据逐个发送COMMIT封包给follower保存下来;如果没有,但follower数据id更大,那么会发送TRUNC封包告知截除多余数据;如果follower的最大zxid比leader最大zxid小,就会直接发送SNAP封包将快照同步发送给follower。
④ 以上消息完毕之后,就会发送UPTODATE封包告知follower当前数据就是最新的了,就差不多了。
第14点:ZooKeeper实例之HDFS HA
讲了那么多ZooKeeper的原理,现在开始讲讲ZooKeeper的实例,免得面试官问ZooKeeper相关的实例,自己没有准备。这次主要讲讲HDFS HA,HDFS HA实现高可用主要就是依赖于ZooKeeper,它主要包括两部分:一个是元数据同步,一个是主备切换。
先讲讲元数据同步,主要是下图中的画红圈部分。

下面讲讲元数据同步的流程,在同一个HDFS集群中,运行两个NameNode节点。一个是主Namenode节点,处于Active状态,一个是从NameNode节点,处于Standby状态。其中只有Active NameNode能对外提供读写服务,Standby NameNode会根据Active NameNode的状态变化,在主节点出现异常的时候,就会切换成Active的状态。
但是在主备切换过程中,新的Active NameNode必须确保与原来的Active NamNode元数据同步完成,才能够对外提供服务。
那如何做到元数据同步呢?
这里就会用到JournalNode集群作为共享存储系统,当客户端对HDFS进行操作的时候,会在Active NameNode中edits.log文件中作日志记录,同时日志记录也会写入JournalNode集群,它负责存储HDFS新产生的元数据。当有新数据写入JournalNode集群时,Standby NameNode就能监听到这种情况,将新数据同步过来,那么Active NameNode和Standby NameNode就实现了元数据同步。另外,所有的datanode也会向两个主备namenode做block report。
现在就到了主备切换,好好讲讲!先画出流程图:

根据这个流程图,好好体会体会这个过程。
1、每个NameNode节点上都会有一个ZKFC进程,ZKFC进程它负责控制NameNode的主备切换。
2、ZKFC在启动时,同时会初始化HealthMonitor和ActiveStandbyElector服务,ZKFC同时也会向HealthMonitor和ActiveStandbyElector注册相应的回调方法,HealthMonitor监控NameNode的健康状态,ActiveStandbyElector会接收ZKFC的选举请求,创建一个临时节点ActiveStandbyElectorLock。
3、接下来,两个ZKFC就会通过各自ActiveStandbyElector会尝试在Zookeeper创建临时节点ActiveStandbyElectorLock,但由于Zookeeper的写一致性,就会导致最终只会有一个ActiveStandbyElector创建成功。
4、创建成功的 ActiveStandbyElector回调ZKFC的回调方法,将对应的NameNode切换为Active NameNode状态,而创建失败的ActiveStandbyElector回调ZKFC的回调方法,将对应的NameNode切换为Standby NameNode状态。
5、但是呢!不管是否选举成功,所有ActiveStandbyElector都会在临时节点ActiveStandbyElectorLock上注册一个Watcher监听器,来监听这个节点的状态变化情况。
6、如果Active NameNode对应的HealthMonitor检测到NameNode状态异常,就会通知对应的ZKFC。ZKFC会调用 ActiveStandbyElector 方法,删除在Zookeeper上创建的临时节点ActiveStandbyElectorLock。此时,Standby NameNode的ActiveStandbyElector注册的Watcher就会监听到这个删除事件。
7、收到这个事件后,此ActiveStandbyElector发起主备选举,成功创建临时节点ActiveStandbyElectorLock,如果创建成功,则Standby NameNode被选举为Active NameNode。
第15点:脑裂
什么是脑裂?
在分布式系统中出现两个leader的现象,就是脑裂。产生的原因有很多,例如网络有延迟之类的,这种情况的出现是非常可怕的,必须通过自带的隔离(Fencing)机制来避免这种现象。
那隔离到底是怎么做到隔离的呢?
1、ActiveStandbyElector成功创建ActiveStandbyElectorLock临时节点后,会创建另一个ActiveBreadCrumb持久节点,这个持久节点保存了Active NameNode的地址信息。
2、当Active NameNode在正常的状态下断开Session,会同时删除临时节点ActiveStandbyElectorLock、持久节点ActiveBreadCrumb。
3、但是如果ActiveStandbyElector在异常的状态下关闭Session,那么持久节点ActiveBreadCrumb会保留下来。
4、当另一个NameNode要由standy变成active状态时,就会发现上一个Active NameNode遗留下来的ActiveBreadCrumb节点,那么会回调ZKFC对旧的Active NameNode进行fencing。
03 总结
好啦,终于结束了!老刘关于大数据ZooKeeper知识点一共总结了15点,每一点在老刘看来都非常重要,老刘对他们进行了熟记,记在了脑子里,希望对想学大数据的你们有帮助,也希望能够得到大佬的批评和指点。
最后,有事,就公众号:努力的老刘,进行联系,没事就和老刘一起加油,进大厂。
我要进大厂之大数据ZooKeeper知识点(2)的更多相关文章
- 我要进大厂之大数据ZooKeeper知识点(1)
01 让我们一起学大数据 老刘又回来啦!在实验室师兄师姐都找完工作之后,在结束各种科研工作之后,老刘现在也要为找工作而努力了,要开始大数据各个知识点的复习总结了.老刘会分享出自己的知识点总结,一是希望 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
- 我要进大厂之大数据Hadoop HDFS知识点(2)
01 我们一起学大数据 老刘继续分享出Hadoop中的HDFS模块的一些高级知识点,也算是对今天复习的HDFS内容进行一次总结,希望能够给想学大数据的同学一点帮助,也希望能够得到大佬们的批评和指点! ...
- 大数据核心知识点:Hbase、Spark、Hive、MapReduce概念理解,特点及机制
今天,上海尚学堂大数据培训班毕业的一位学生去参加易普软件公司面试,应聘的职位是大数据开发.面试官问了他10个问题,主要集中在Hbase.Spark.Hive和MapReduce上,基础概念.特点.应用 ...
- 大白话详解大数据hive知识点,老刘真的很用心(2)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(2) 第12点:hive分桶表 hive知识点主要偏实践, ...
- 大白话详解大数据hive知识点,老刘真的很用心(3)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(3) 从这篇文章开始决定进行一些改变,老刘在博客上主要分享 ...
- 大数据 - Zookeeper
Zookeeper 1. Zookeeper概念简介: Zookeeper是一个分布式协调服务:就是为用户的分布式应用程序提供协调服务 A.zookeeper是为别的分布式程序服务的 B.Zooke ...
随机推荐
- Mac下面 matplotlib 中文无法显示解决
一.环境描述 python 3.7 mac 10.14.5 二.问题描述 如下图所示,当使用matplotlib绘制图片的时候,所有的中文字符无法正常显示. 三.解决方法 1.下载字体ttf文件 链接 ...
- 在windows2003上安装itunes
本人使用windows server 2003系统 安装itunes时提示 AppleMobileDeviceSupport 只能按照在xp系统上或以上版本,你可以忽略这个错误.继续安装吧. 这样除了 ...
- 通过命令行上传ipa到appstore
搞持续集成自动化打包上传到appstore遇到这个问题,记录一下. 其实主要就一条到命令: xcrun altool --upload-app -f xxxx.ipa -u "yanqizh ...
- Python基础知识,新手入门看过来
1 下载和安装Python 在开始编程之前,你需要安装Python解析器软件(这里你可能需要找人帮忙).解析器是一个可以理解你用Python语言写的指令的程序.如果没有解析器,你的计算机不会理解这些指 ...
- pyqt5屏幕坐标系
我们直接用代码去理解屏幕坐标系 import sys from PyQt5.QtWidgets import QHBoxLayout,QMainWindow,QApplication,QPushBut ...
- puk1251 最小生成树
Description The Head Elder of the tropical island of Lagrishan has a problem. A burst of foreign aid ...
- eclipse之SSH配置spring【二】
第一篇中配置struts完成(http://www.cnblogs.com/dev2007/p/6475074.html),在此基础上,继续配置spring. web.xml中增加listener,依 ...
- STM32入门系列-STM32时钟系统,时钟使能配置函数
之前的推文中说到,当使用一个外设时,必须先使能它的时钟.怎么通过库函数使能时钟呢?如需了解寄存器配置时钟,可以参考<STM32F10x中文参考手册>"复位和时钟控制(RCC)&q ...
- NB-IoT应用分类与技术特点分析
NB-Iot作为一种窄带物联网技术在各大行业脱颖而出,其应用涵盖多个领域.此文计讯小编将讲解NB-IoT的主要应用分类及相关特点. 一.NB-IoT是什么 NB-IoT是指窄带物联网(Na ...
- Java中的常见数学运算
1.舍掉小数取整:Math.floor(3.5)=3 2.四舍五入取整:Math.rint(3.5)=4 3.进位取整:Math.ceil(3.1)=4 4.取绝对值:Math.abs(-3.5)=3 ...