BeautifulSoup解析页面
beautiful soup是一个解析包,专门用来解析html语法的,lxml是一个解析器,用来分析以及定位内容的
.是class #是id
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.zygx8.com/forum.php')
soup = BeautifulSoup(html.text,'lxml')
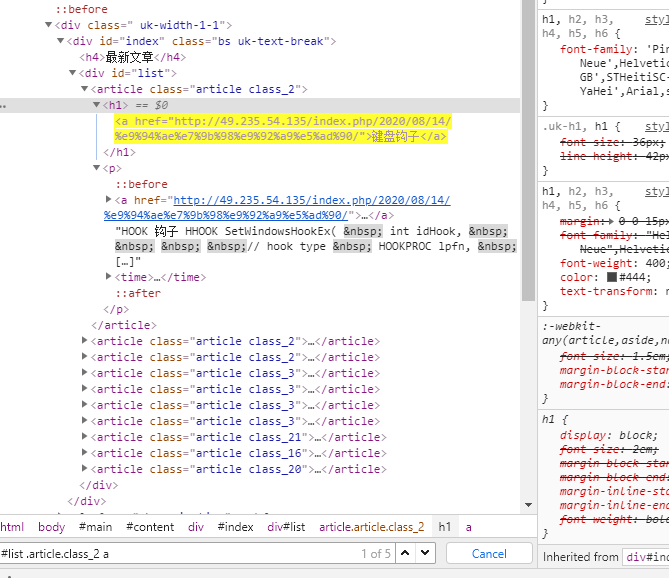
tbody = soup.select('a font b')
print(tbody)
输出

然后我们可以看到返回的都有个a标签,beautifulsoup其实有个自带的
for t in tbody:
print(t.text)
输出
键盘钩子
网络版cmd开发
Mycmd
这里选择器我们就用select,比如我们要获取title就直接soup.select('title'),通过tag逐层下找比如
soup.select('html head title')
soup.select('body a')
select_one只获取一个
这里我们来测试豆瓣
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
html = requests.get('https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4',headers=headers)
soup = BeautifulSoup(html.text,'lxml')
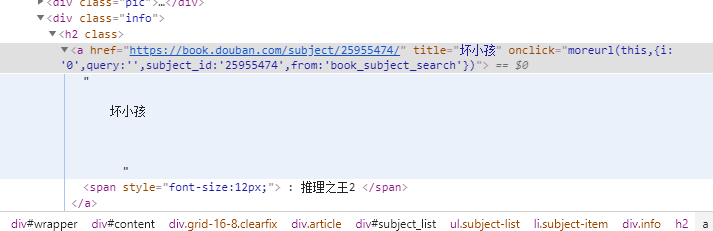
title = soup.select('.subject-list .subject-item .info h2 a')
for t in title:
print(t.text.strip().replace('\n',''))
输出
G:\python3.8\python.exe "F:/python post/code/zygx8.py"
坏小孩 : 推理之王2
活着
白夜行
小王子
解忧杂货店
红楼梦
追风筝的人
百年孤独
房思琪的初恋乐园
长夜难明 : 推理之王3
嫌疑人X的献身
平凡的世界(全三部)
1984
月亮与六便士
霍乱时期的爱情
围城
云边有个小卖部
杀死一只知更鸟
局外人
烧纸
Process finished with exit code 0
我们再清洗下
print(t.text.strip().replace('\n','').replace(' ',''))
输出
G:\python3.8\python.exe "F:/python post/code/zygx8.py"
坏小孩:推理之王2
活着
白夜行
小王子
解忧杂货店
红楼梦
追风筝的人
百年孤独
房思琪的初恋乐园
长夜难明:推理之王3
嫌疑人X的献身
平凡的世界(全三部)
1984
月亮与六便士
霍乱时期的爱情
围城
云边有个小卖部
杀死一只知更鸟
局外人
烧纸
BeautifulSoup解析页面的更多相关文章
- python爬虫主要就是五个模块:爬虫启动入口模块,URL管理器存放已经爬虫的URL和待爬虫URL列表,html下载器,html解析器,html输出器 同时可以掌握到urllib2的使用、bs4(BeautifulSoup)页面解析器、re正则表达式、urlparse、python基础知识回顾(set集合操作)等相关内容。
本次python爬虫百步百科,里面详细分析了爬虫的步骤,对每一步代码都有详细的注释说明,可通过本案例掌握python爬虫的特点: 1.爬虫调度入口(crawler_main.py) # coding: ...
- Python爬虫 | Beautifulsoup解析html页面
引入 大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据.因此,在聚焦爬虫中使用数据解析.所以,我们的数据爬取的流程为: 指定url 基于reque ...
- python爬虫解析页面数据的三种方式
re模块 re.S表示匹配单行 re.M表示匹配多行 使用re模块提取图片url,下载所有糗事百科中的图片 普通版 import requests import re import os if not ...
- beautifulsoup解析
beautifulsoup解析 python独有 优势:简单.便捷.高效 - 环境安装 需要将pip源设置为国内源 -需要安装:pip install bs4 bs4在使用时需要一个第三方库 pip ...
- python3+beautifulSoup4.6抓取某网站小说(三)网页分析,BeautifulSoup解析
本章学习内容:将网站上的小说都爬下来,存储到本地. 目标网站:www.cuiweijuxs.com 分析页面,发现一共4步:从主页进入分版打开分页列表.打开分页下所有链接.打开作品页面.打开单章内容. ...
- MiseringThread.java 解析页面线程
MiseringThread.java 解析页面线程 http://injavawetrust.iteye.com package com.iteye.injavawetrust.miner; imp ...
- MinerUrl.java 解析页面后存储URL类
MinerUrl.java 解析页面后存储URL类 package com.iteye.injavawetrust.miner; /** * 解析页面后存储URL类 * @author InJavaW ...
- BeautifulSoup解析器的选择
BeautifulSoup解析器 在我们使用BeautifulSoup的时候,选择怎样的解析器是至关重要的.使用不同的解析器有可能会出现不同的结果! 今天遇到一个坑,在解析某html的时候.使用htm ...
- Python3.x的BeautifulSoup解析html常用函数
Python3.x的BeautifulSoup解析html常用函数 1,初始化: soup = BeautifulSoup(html) # html为html源代码字符串,type(html) == ...
随机推荐
- hdfs-default.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="confi ...
- linux命令查询网站
http://linux.51yip.com/ http://man.linuxde.net/ Linux命令查询手册Linux终端下 esc + . 可以获取上次文件名
- Hadoop 2.6.1 集群安装配置教程
集群环境: 192.168.56.10 master 192.168.56.11 slave1 192.168.56.12 slave2 下载安装包/拷贝安装包 # 存放路径: cd /usr/loc ...
- vim缩写
vim缩写可以简化输入,如在Python调试中的logging.warning可以缩写为lgw,在使用时会提高效率. 一.设置缩写 在~/.vimrc增加: :abbreviate lgw loggi ...
- 图解JAVA容器核心类库
JAVA容器详解 类继承结构图 HashMap 1. 对象的HashCode是用来在散列存储结构中确定对象的存储地址的. 2. 如果两个对象的HashCode相同,即在数组中的地址相同.而数组的元 ...
- 模型层中QuerySet的学习
创建对象 使用关键字参数实例化模型实例来创建一个对象,然后调用save()把它保存到数据库中 pub_obj = models.Publisher(title='奥利给出版社') pub_obj.sa ...
- DataPicker 日期选择器
问题描述:DataPicker 日期选择器,如何选取时间段(本日,昨日,上周,上月,当月) 代码实现: <el-date-picker v-model="searchForm.data ...
- win10找不到wifi
禁用->启用 就能用了.
- Lct 动态链接树
通过树链剖分能了解轻重边 Acdreamer 的博客 http://blog.csdn.net/acdreamers/article/details/10591443 然后看杨哲大大的论文,能了解轻重 ...
- 故障:fork failed:Resource Temporarily Unavailable解决方案
故障:fork failed:Resource Temporarily Unavailable解决方案 AIX在一次crontab bkapp.txt导入N多定时任务时候,该用户无法执行任何命令,再s ...