Andrew Ng机器学习公开课笔记 -- 朴素贝叶斯算法
网易公开课,第5,6课
notes,http://cs229.stanford.edu/notes/cs229-notes2.pdf
前面讨论了高斯判别分析,是一种生成学习算法,其中x是连续值
这里要介绍第二种生成学习算法,Naive Bayes算法,其中x是离散值的向量
这种算法常用于文本分类,比如分类垃圾邮件
首先,如何表示一个文本,即x?
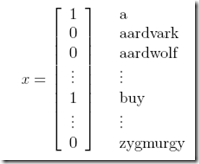
以上面这种向量来表示,字典中的词是否在该文本中出现
其中每个词,可以看作是一个特征,对于特征的选取,可以过滤到stop word,或只选取出现多次的值。。。
那么训练集,就是一系列(x向量,y),其中y为0或1表示non-spam,spam
其次,如何建模?
我们可以考虑直接对P(y|x)进行建模,但是x中的feature数一般是比较多的,讲义中假设为50000,那么可以想象x的取值可能性为 ,所以如果要找出每一种x的可能性来建模,基本不可能
,所以如果要找出每一种x的可能性来建模,基本不可能
所以这种case,需要使用生成学习算法,通过对P(x|y)进行建模,来间接计算出P(y|x)
因为y的取值只有0,1,看似容易一些
但这里x的取值是,为一个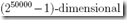 参数向量的多项分布,仍然过于复杂
参数向量的多项分布,仍然过于复杂
所以最终,提出Naive Bayes (NB) assumption,用于近似和简单对P(x|y)进行建模
这个假设非常简单,即每个词或feature都是独立出现的 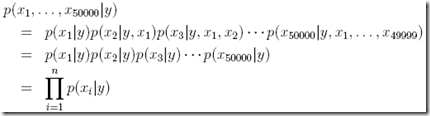
所以上面推导的第二行可以简化为第三行的形式
虽然这个假设在现实中不可能为真,但是实际的效果挺好
接着写出joint likelihood,用于建模 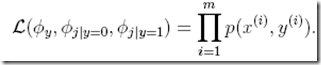
其中, 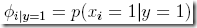
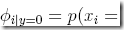
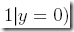
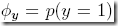
省去推导过程,得到 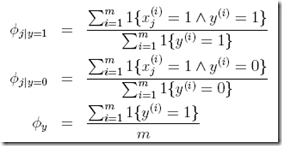
其实这里得到这些结果,就算不用最大似然去推导,单纯从概率角度去思考,也会得到这个结果。比如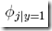 ,想当然应该是,所有y=1的文本中包含第j个单词的比例
,想当然应该是,所有y=1的文本中包含第j个单词的比例
所以这里使用最大似然推导是一个流程,显得更严谨
其实可以更直观的得到上面的结果
最后,如果对一个新的x进行预测?
比较简单,用上面的公式计算出每一部分,就可以得到最终的结果
对于生成算法,分别计算出P(y=1|x)和P(y=0|x) 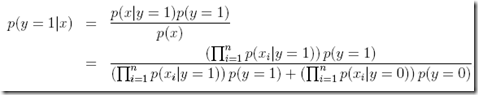
Laplace smoothing
上面给出的Naive Bayes有个问题是,当给出的x中出现一个训练集从未出现过的词的时候,这时候根据训练集去计算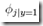 和
和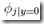 都会得到0
都会得到0
于是会得到这个结果,
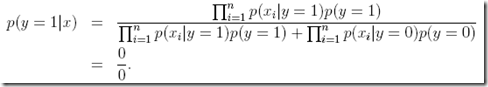
这明显是不合理的,这种不合理是由于你的训练集是非常有限的导致的,所以这里需要使用Laplace smoothing来避免这种情况
z取值{1, . . . , k},
那么给定m个z的观察值,
现在要根据观察值,来判断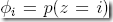
根据上面的最大似然结论,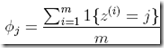
这里问题就在于,如果j在m个观察值中没有出现,那么通过这个公式算出的为0
这明显不合理,因为在训练集中没有看到的现象,你不能说他出现的概率为0,只不过是因为训练集有限,没有出现罢了
Laplace用于描述明天太阳升起的概率,虽然你天天看到太阳升起,但明天太阳依然会升起的概率一定不是1
所以利用Laplace smoothing,变化为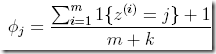
分子加1,很容易理解,没有就至少算出现一次
分母之所以要加k,是为了保证
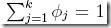
回到我们的问题,经过Laplace smoothing的Naive Bayes分类器变为, 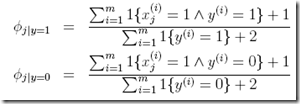
Naive Bayes的扩展
1. x取值的扩展
基本的算法中,x取值为{0,1}
可以扩展成x的取值为{1, 2, . . . , k},
区别就是 ,由Bernoulli分布变为多项分布
,由Bernoulli分布变为多项分布
这种扩张常用于使用GDA对连续x进行分类效果不好时,
将连续的x离散化,比如下面把房屋的面积进行离散化 
然后使用Naive Bayes进行分类往往会得到比较好的效果
2. multi-variate Bernoulli event model
这种扩展往往也是用于文本分类,因为普通的bayes方法只是考虑这个词是否存在,而没有考虑这个词的出现频率
事件模型就是对这个的一种改进,
首先表示一个文本或email的方式变了
普通bayes中,x长度取决于字典的大小,因为xi表示字典中第i个词是否出现
而这里,x长度取决于文本长短,xi表示在文本中i位置上的词中字典中的索引,如下例
For instance, if an email starts with “A NIPS . . . ,”then x1 = 1 (“a” is the first word in the dictionary), and x2 = 35000 (if“nips” is the 35000th word in the dictionary).
然后是建模,设  ,
,
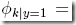
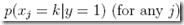
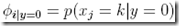
joint似然函数为,m是训练集的大小,n是每个文本中的词的个数 
可以得到,同样省去推导过程 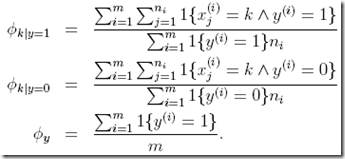
可以看到,这里在考虑字典中索引为k的词时,会把在文本中出现的次数相加
所以这里不仅仅考虑是否出现,还考虑到到次数
Andrew Ng机器学习公开课笔记 -- 朴素贝叶斯算法的更多相关文章
- Andrew Ng机器学习公开课笔记 -- 支持向量机
网易公开课,第6,7,8课 notes,http://cs229.stanford.edu/notes/cs229-notes3.pdf SVM-支持向量机算法概述, 这篇讲的挺好,可以参考 先继 ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Andrew Ng机器学习公开课笔记–Principal Components Analysis (PCA)
网易公开课,第14, 15课 notes,10 之前谈到的factor analysis,用EM算法找到潜在的因子变量,以达到降维的目的 这里介绍的是另外一种降维的方法,Principal Compo ...
- Andrew Ng机器学习公开课笔记 -- 学习理论
网易公开课,第9,10课 notes,http://cs229.stanford.edu/notes/cs229-notes4.pdf 这章要讨论的问题是,如何去评价和选择学习算法 Bias/va ...
- Andrew Ng机器学习公开课笔记–Reinforcement Learning and Control
网易公开课,第16课 notes,12 前面的supervised learning,对于一个指定的x可以明确告诉你,正确的y是什么 但某些sequential decision making问题,比 ...
- Andrew Ng机器学习公开课笔记 – Factor Analysis
网易公开课,第13,14课 notes,9 本质上因子分析是一种降维算法 参考,http://www.douban.com/note/225942377/,浅谈主成分分析和因子分析 把大量的原始变量, ...
- Andrew Ng机器学习公开课笔记–Independent Components Analysis
网易公开课,第15课 notes,11 参考, PCA本质是旋转找到新的基(basis),即坐标轴,并且新的基的维数大大降低 ICA也是找到新的基,但是目的是完全不一样的,而且ICA是不会降维的 对于 ...
- Andrew Ng机器学习公开课笔记 -- Mixtures of Gaussians and the EM algorithm
网易公开课,第12,13课 notes,7a, 7b,8 从这章开始,介绍无监督的算法 对于无监督,当然首先想到k means, 最典型也最简单,有需要直接看7a的讲义 Mixtures of G ...
- Andrew Ng机器学习公开课笔记 -- Online Learning
网易公开课,第11课 notes,http://cs229.stanford.edu/notes/cs229-notes6.pdf 和之前看到的batch learning算法不一样,batch ...
随机推荐
- 配置OpenGL的开发环境
OpenGL库资源下载 http://pan.baidu.com/s/1ntVsReL 环境搭建 将下载好的文件进行解压,可以得到后缀为.h..lib..dll三类文件,对这三类文件作如下处理: 将所 ...
- 查看 SharePoint 2013 部署到GAC的自定义dll
在SharePoint 2007和2010中,自定义dll存放在“C:\Windows\assembly\”文件夹中,在Windows资源管理器中可以看到. 但在Sharepoint 2013中,却无 ...
- js焦点轮播图
汇集网上焦点轮播图的实现方式,自己试了下,不过鼠标悬浮停止动画和鼠标离开动画播放好像没生效,不太明白,最后两行代码中,为什么可以直接写stop和play.不用加括号调用函数么?求懂的大神指点! 所用知 ...
- EasyTouch5初步用法和其中的一个Bug
(一)配置部分:一.将预设体拖入场景中,我用的是下图这个预设体,因为既有摇杆又有按钮嘛,两个正好都能学习到 二.改变摇杆和按钮的外观,如下图所示,可以看出这个插件是用UGUI写的,改图片只需要改Ima ...
- 怎样用MathType创建竖式算法
在使用MathType编辑公式时,有时将最简单的表达式变成Word文档也会出现一些问题.比如MathType竖式.下面介绍MathType竖式的一些编辑方法. 步骤如下: 步骤一:在MathType底 ...
- js正则表达式的基本语法
1.正则表达式基本语法 创建正则表达式 var re = new RegExp();//RegExp是一个对象,和Aarray一样 //但这样没有任何效果,需要将正则表达式的内容作为字符串传递进去 r ...
- js正则表达式的应用
JavaScript表单验证email,判断一个输入量是否为邮箱email,通过正则表达式实现. //检查email邮箱 function isEmail(str){ var reg = /^([a- ...
- 自定向下分析Binder 之 Binder Model(1)
Java层的Binder对象模型: IBinder IBinder是Binder通信机制中的核心部分(Base interface for a remotable object, the core p ...
- ios开发之--pop到指定页面
1 推出到根视图控制器 [self.navigationController popToRootViewControllerAnimated:YES]; 2 推出到指定的视图控制器 for (UIVi ...
- ArcGIS Javascript 图层事件绑定
1.使用Dojo---Connect Style Event dojo.connect(XXXGraphicsLayer, "onClick", function(evt) { / ...