HDFS Namenode&Datanode
HDFS Namenode&Datanode
HDFS 机制粗略示意图
客户端写入文件流程:
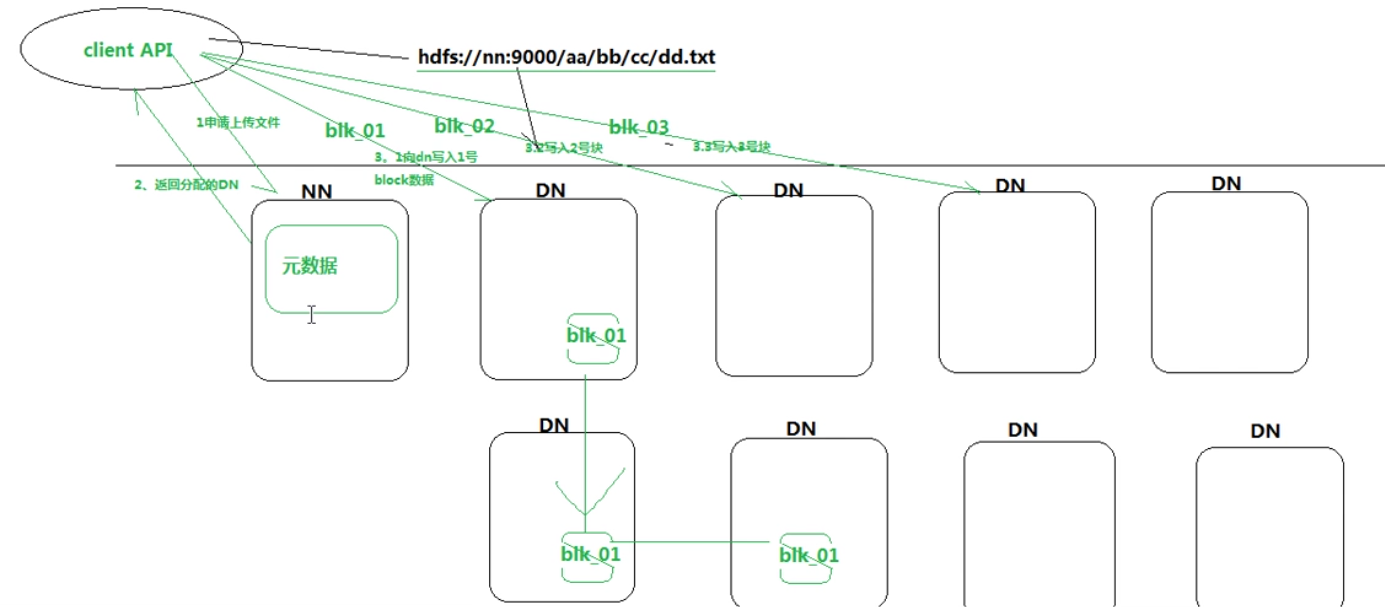
NN && DN
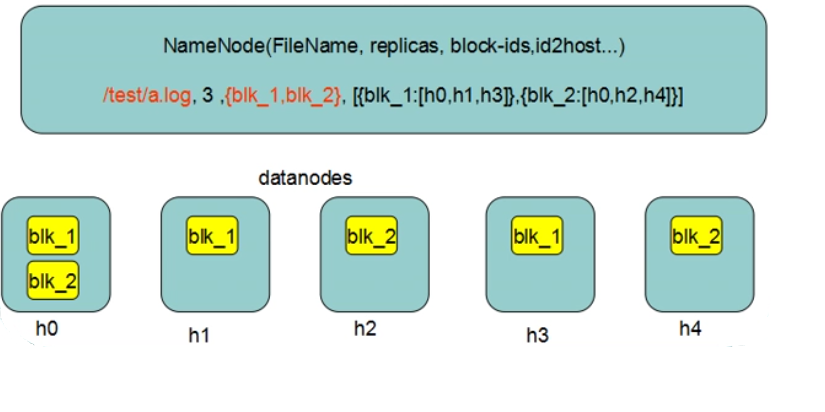
Namenode(NN)工作机制
NN是整个文件系统的管理节点。维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表(管理元数据)。接收用户的操作请求。
fsimage:元数据镜像文件。存储某一时段NN内存元数据信息
edits:操作日志文件
fstime:保存最近一次checkpoint的时间
(以上文件保存在linux文件系统中)
主流程
- 客户端上传文件时,NN首先往edits log文件中记录元数据操作日志
- 客户端开始上传文件,完成后返回成功信息给NN。NN就在内存中写入这次上传操作而新产生的元数据信息。既实现了客户端可以从内存中查询(读写速度比从磁盘快),又保证了可靠性(若断电内存中的信息丢失,则可以从edits log文件中找回)。
- 每当edits log写满时,由secondary namenode将这部分新的元数据合并到fsimage文件中(checkpoint操作)。
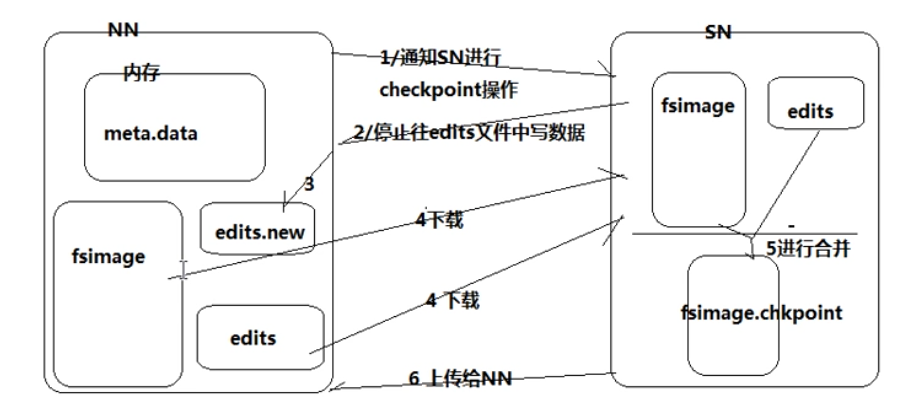
secondary namenode 的 checkpoint 操作
工作流程
- secondary通知namenode切换edits文件(改为写到edits.new)
- secondary从namenode获得fsimage和edits(通过http)
- secondary将fsimage载入内存,然后开始合并edits,产生新的fsimage
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage,并将edits.new重命名为edits
进行checkpoint的时间
- fs.checkpoint.period 指定两次checkpoint的间隔(默认3600秒)
- fs.chekpoint.size 规定edits文件的最大值,一旦超过则强制checkpoint,不管是否达到时间间隔(默认64M)
(以上可在hdfs-site.xml中设置)
Datanode(DN)工作原理
DN提供真实文件数据的存储服务。
文件块(block):最基本的存储单位。对于文件而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小顺序对文件进行划分并编号,划分好的每一块称一个block。
block的默认大小是128M,可以修改dfs.block.size参数进行更改
上传一个文件看看分块情况
上传 hadoop fs -put xxx(随便一个稍大一些的文件) /
打开datanode的数据文件夹 cd /app/hadoop-3.0.0/data/dfs/data/current/BP-1998331996-192.168.216.100-1521773499028/current/finalized/subdir0/subdir0
查看 du -sh *
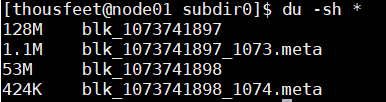
能看到被分作了两个block,其中一个正是128M。(.mate是校验和文件不是一个block)
HDFS Namenode&Datanode的更多相关文章
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- 【Hadoop】hdfs的秘密,namenode,datanode,yarn,安全模式,fsimage,edits...
1.bin/hdfs namenode -format ** 注意事项 1.在配置好了配置文件之后,首次启动之前,做初始化操作 2.在后续启动的时候,不需要再初始化 3.初始化的一些影响 一.初始化操 ...
- Hadoop(五)—— HDFS NameNode、DataNode工作机制
一.NN与2NN工作机制 NameNode(NN) 1.当HDFS启动时,会加载日志(edits)和镜像文件(fsImage)到内存中. 2-4.当元数据的增删改查请求进来时,NameNode会先将操 ...
- HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- NameNode & DataNode
NameNode类位于org.apache.hadoop.hdfs.server.namenode包下. NameNode serves as both directory namespace man ...
- 后端分布式系列:分布式存储-HDFS NameNode 设计实现解析
接前文 分布式存储-HDFS 架构解析,我们总体分析了 HDFS 架构的主要构成组件包括:NameNode.DataNode 和 Client.本文首先进一步解析 HDFS NameNode 的设计和 ...
- Hadoop:HDFS NameNode内存全景
原文转自:https://tech.meituan.com/namenode.html 感谢原作者 一.概述 从整个HDFS系统架构上看,NameNode是其中最重要.最复杂也是最容易出现问题的地方, ...
- Hadoop HDFS NameNode工作机制
Secondary namenode 首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低.因此,元数据需要存放在内存中.但如果只存在内存中 ...
- 启动HDFS时datanode无法启动的坑
启动HDFS 启动hdfs,进入sbin目录,也可以执行./start-all.sh - $cd /app/hadoop/hadoop-2.2.0/sbin - $./start-dfs.sh 在此之 ...
随机推荐
- Oracle 12c pdb自动启动
PDB Pluggable Database是12c中扛鼎的一个新特性, 但是对于CDB中的PDB,默认启动CDB时不会将所有的PDB带起来,这样我们就需要手动alter pluggable data ...
- 747_Largest-Number-At-Least-Twice-of-Others
目录 747_Largest-Number-At-Least-Twice-of-Others Description Solution Java solution Python solution 74 ...
- vue之生命周期的一点总结
vue的生命周期的过程提供了我们执行自定义逻辑的机会,好好理解它的生命周期,对我们很有帮助. 一.vue实例的生命周期(vue2.0) 二.生命周期描述:(参考截图) 三.例子 window.vm = ...
- 微信小程序 c#后台支付结果回调
又为大家带来简单的c#后台支付结果回调方法,首先还是要去微信官网下载模板(WxPayAPI),将模板(WxPayAPI)添加到服务器上,然后在打开WxPayAPI项目中的example文件下的 Nat ...
- 如何构建ASP.NET MVC4&JQuery&AJax&JSon示例
背景: 博客中将构建一个小示例,用于演示在ASP.NET MVC4项目中,如何使用JQuery Ajax. 步骤: 1,添加控制器(HomeController)和动作方法(Index),并为Inde ...
- NET 知识体系结构
以下是我根据自身的情况来总结的ASP.NET 知识体系 ASP.NET 知识体系 1.语言C#——C#-知识梳理 2.ASP.NET 3.WinForm 4.ASP.NET MVC 5.EF
- 二、socket编写简单BIO的HTTP服务器
一.目标 诸如tomcat等web服务器中间件简化了我们web的开发成本,但有时候我们或许并不需要这么一个完备的服务器,只是希望做一个简单地处理或者做特殊用途的服务器. 本文将提供一个HTTP的服务器 ...
- http_proxy_module 模块(proxy_pass 指令)
1. proxy_pass 指令介绍 该指令属于 http_proxy_module, http_proxy_module 模块可以将请求转发到另一台服务器. 在 nginx 反向代理是,会通过 lo ...
- HDU-2046 骨牌铺方格【递推】
http://acm.hdu.edu.cn/showproblem.php?pid=2046 和前面的一样,a[i] = a[i-1] + a[i-2] #include<iostream> ...
- K:逆波兰算法
相关介绍: 一种求解字符串形式的表达式的结果的算法,该算法在求解时,需要先将我们平日里习惯上使用的中序表达式的模式转化为等价的后序(后缀)表达式的模式,之后再通过求解出该后序(后缀)表达式的结果而得 ...