Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
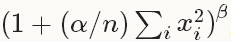 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
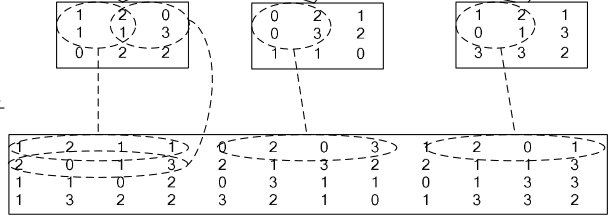
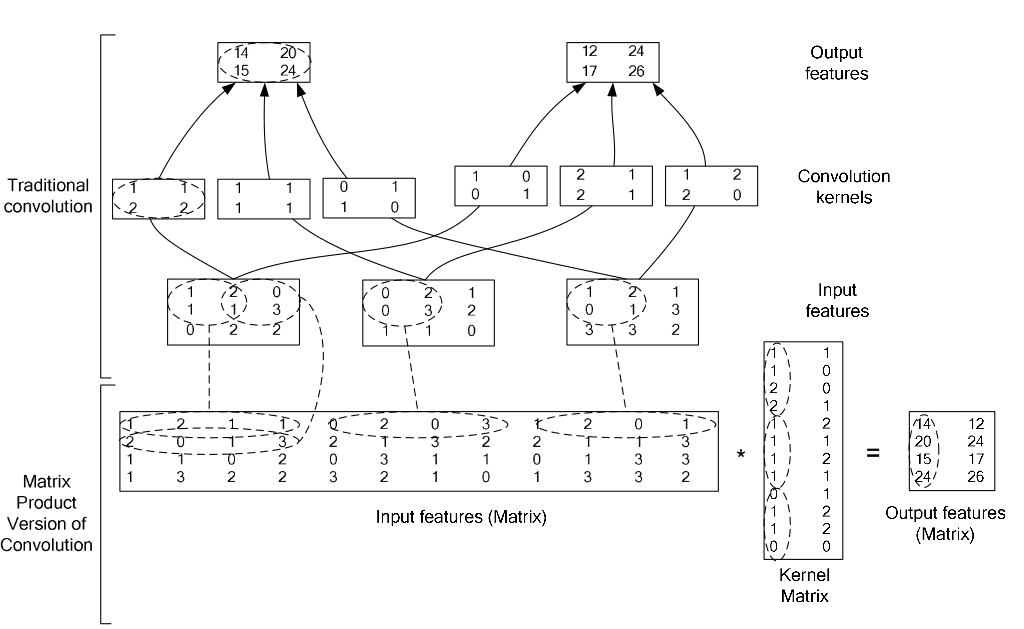
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
Caffe学习系列(3):视觉层(Vision Layers)及参数的更多相关文章
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- 【开源项目SugarSite】ASP.NET MVC+ Layui+ SqlSugar+RestSharp项目讲解
SugarSite一个前端支持移动端的企业网站,目前只支持了简单功能,后续还会加上论坛等. 源码GIT地址: https://github.com/sunkaixuan/SugarSite 技术介绍 ...
- MySQL 数据库双向镜像、循环镜像(复制)
在MySQL数据库镜像的贴子中,主数据库A 的数据镜像到从数据库B,是单向的,Zen Cart网店的数据读写都必须在数据库A进行,结果会自动镜像到数据库B中.但是对数据库B的直接操作,不会影响数据库A ...
- 自定义可视化调试工具(Microsoft.VisualStudio.DebuggerVisualizers)vs.net开发工具
背景: 话说:使用CYQ.Data时,会经常断点MDataTable的对象,为了查看表格的数据内容,在监视里会常ToDataTable(),然后借可DataTable的可视化方式查看表格. 近日:心中 ...
- Java中静态类型检查是如何进行的
以下内容来自维基百科,关于静态类型检查和动态类型检查的解释: 静态类型检查:基于程序的源代码来验证类型安全的过程: 动态类型检查:在程序运行期间验证类型安全的过程: Java使用静态类型检查在编译期间 ...
- PMBOK(第五版)学习笔记二-十大知识领域(P87)
五大项目管理过程组:启动.规划.执行.监控.收尾过程组 十大知识领域是:项目整合管理.项目范围管理.项目时间管理.项目成本管理.项目质量管理.项目人力资源管理.项目沟通管理.项目风险管理.项目采购管理 ...
- SQL Server 2000:提示“未与信任SQL SERVER连接相关连”错误
在使用“用户模式”登陆SQL Server 2000时提示“未与信任SQL SERVER连接相关连”错误,因为在安装SQL Server时选择“仅Windows”模式,所以所有用户都不可以登陆. 解决 ...
- SQLServer修改字段类型
Alter table [表名] Alter column [列名] [列类型]
- net-snmp添加自定义MIB
我所知道的添加自定义MIB的方法有三种 1.静态加载,将生成的.c和.h文件加入到相应的位置,重新编译snmp库,优点是不需要修改配置文件,缺点是每次添加都得重新编译: 2.动态加载,将生成的.c ...
- VIM使用技巧总结
一.vim使用的基本配置 1: set nu //设置行号 2: set ts=4 //设置tab为4个空格大小 3: set expandtab //设置用空格代替tab 4: set ai //设 ...
- 命令行向php传入参数的两种方法
##$argv or $argc $argv 包含当运行于命令行下时传递给当前脚本的参数的数组. $argv[0] 就是脚本文件名. $argc 包含当运行于命令行下时传递给当前脚本的参数的数目 ...