[转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
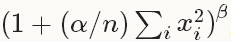 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
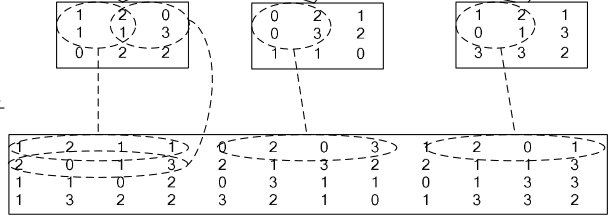
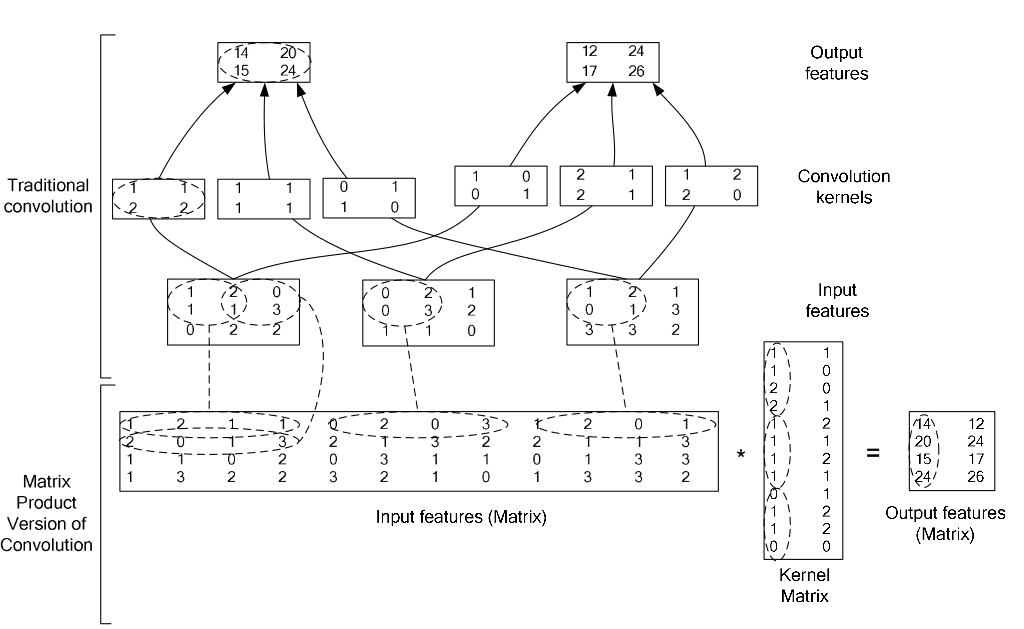
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
原文:http://www.cnblogs.com/denny402/p/5071126.html
[转] caffe视觉层Vision Layers 及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 【转】Caffe初试(五)视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. ...
- caffe(3) 视觉层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN)局部相应归一化, im2 ...
- caffe学习系列(4):视觉层介绍
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 这里介绍下conv层. layer { name: & ...
- 1、Caffe数据层及参数
要运行Caffe,需要先创建一个模型(model),每个模型由许多个层(layer)组成,每个层又都有自己的参数, 而网络模型和参数配置的文件分别是:caffe.prototxt,caffe.solv ...
- caffe 每层结构
如何在Caffe中配置每一个层的结构 最近刚在电脑上装好Caffe,由于神经网络中有不同的层结构,不同类型的层又有不同的参数,所有就根据Caffe官网的说明文档做了一个简单的总结. 1. Vision ...
- Caffe 激励层(Activation)分析
Caffe_Activation 一般来说,激励层的输入输出尺寸一致,为非线性函数,完成非线性映射,从而能够拟合更为复杂的函数表达式激励层都派生于NeuronLayer: class XXXlayer ...
- Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的.从bottom得到一个blob数据输入,运算后,从top输入一个blob数据.在运算过程中,没有改变数据的大小,即输入 ...
随机推荐
- CentOS7 安装redis 并且设置成服务自动启动
通过 博客园 https://www.cnblogs.com/zuidongfeng/p/8032505.html 学习以及记录 1. 下载redis 现在最新的stable版本是 4.0.10 wg ...
- css文本垂直居中
1,一般flexca 2,行高 3,行高加边框或者透明边框
- 原理分析dubbo分布式应用中使用zipkin做链路追踪
zipkin是什么 Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开 ...
- springMVC的接受参数三种样例
- poj2991 Crane(线段树)
Description ACM has bought a new crane (crane -- jeřáb) . The crane consists of n segments of variou ...
- 使用System.getProperty方法,如何配置JVM系统属性
原创文章,欢迎转载,转载请注明出处! 很多时候我们需要在项目中读取外部属性文件,用到了System.getProperty("")方法.这个方法需要配置JVM系统属性,那么如何配置 ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- 【转】四款经典3.7v锂电池充电电路图详解
3.7v锂电池充电电路图(一) 1.锂电池的充电: 根据锂电池的结构特性,最高充电终止电压应为4.2V,不能过充,否则会因正极的锂离子拿走太多,而使电池报废.其充放电要求较高,可采用专用的恒流.恒压充 ...
- 洛谷 P2245 星际导航 解题报告
P2245 星际导航 题目描述 sideman做好了回到Gliese 星球的硬件准备,但是sideman的导航系统还没有完全设计好.为了方便起见,我们可以认为宇宙是一张有N 个顶点和M 条边的带权无向 ...
- 【uoj3】 NOI2014—魔法森林
http://uoj.ac/problem/3 (题目链接) 题意 给出一张带权图,每条边有两个权值A和B,一条路径的花费为路径中的最大的A和最大的B之和.求从1走到n的最小花费. Solution ...