Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
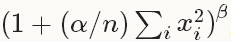 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
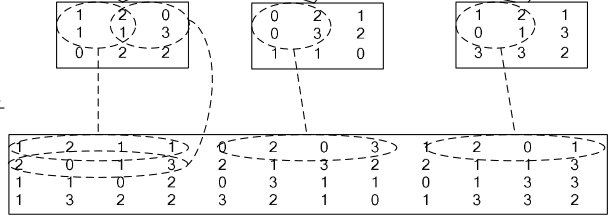
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
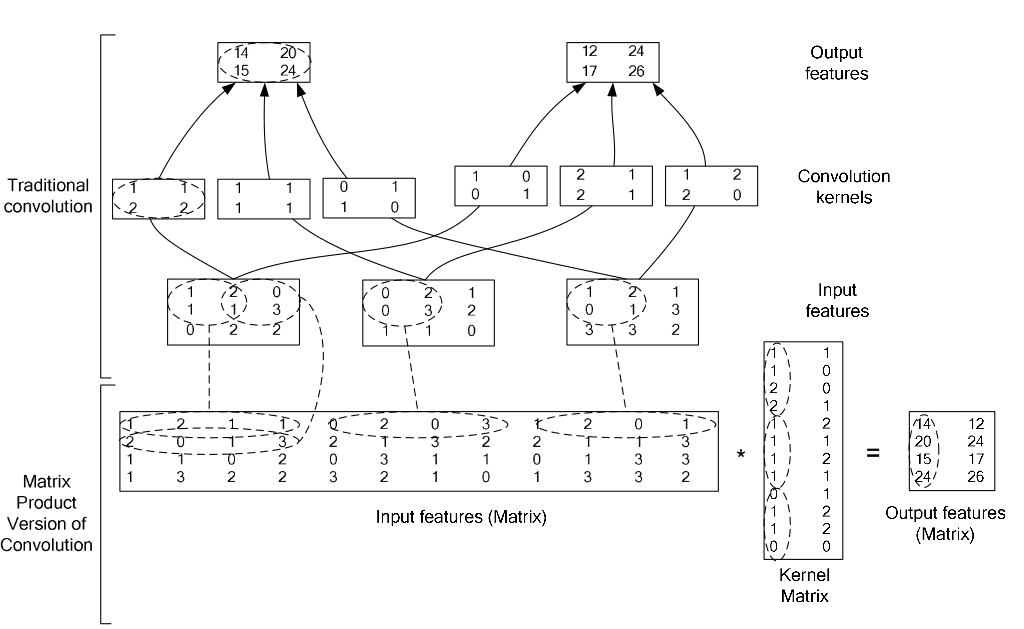
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
Caffe学习系列(3):视觉层(Vision Layers)及参数的更多相关文章
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- 使用Gradle构建构建一个Java Web工程及持续集成环境Jenkins配置
安装Eclipse插件——Buildship 什么是Buildship? Buildship能方便我们通过Eclipse IDE创建和导入Gradle工程,同时还能执行Gradle任务. Eclips ...
- java中实现定时功能
网上资料: 我们可以使用Timer和TimerTask类在java中实现定时任务,详细说明如下: 1.基础知识java.util.Timer一种线程设施,用于安排以后在后台线程中执行的任务.可安排任务 ...
- Linux 系统中用户切换
1. Linux系统中用户切换的命令为su,语法为: su [-fmp] [-c command] [-s shell] [--help] [--version] [-] [USER [ARG]] 参 ...
- ORACLE手工删除数据库
很多人习惯用ORACLE的DBCA工具创建.删除数据库,这里总结一下手工删除数据库实验的步骤,文中大量参考了乐沙弥的手动删除ORACLE数据库这篇博客的内容,当然还有Oracle官方相关文档.此处实验 ...
- 解猜数字(XAXB)
我的想法是:把所有备选答案当做正确答案和猜的数字对比,如果得出XAXB和给出的XAXB相同则保留 代码 ; ; List<string> number = new List<stri ...
- 【Oracle XE系列之一】Windows10_X64环境 安装Oracle XE11gR2 X64数据库
一.安装 1.去Oracle官网下载XE版的安装包[下载路径](Oracle Database Express Edition 11g Release 2 for Windows x64),解压. 2 ...
- Hadoop 基准测试与example
#pi值示例 hadoop jar /app/cdh23502/share/hadoop/mapreduce2/hadoop-mapreduce-examples--cdh5. #生成数据 第一个参数 ...
- C# RGB和HSB相互转换
背景 最近做的项目中有这样一个场景,设置任意一种颜色,得到这种颜色偏深和偏浅的两种颜色.也就是说取该颜色同色系的深浅两种颜色.首先想到的是调节透明度,但效果不理想.后来尝试调节颜色亮度,发现这才是正解 ...
- C++在字符串前加一个L作用:
在字符串前加一个L作用: 如 L"我的字符串" 表示将ANSI字符串转换成unicode的字符串,就是每个字符占用两个字节. strlen("asd" ...
- Hibernate中的inverse
inverse inverse的英文意思是反向的,倒转的 Hibernate配置文件中的inverse正是这一真实反映,inverse属性只在Hibernate配置文件的集合元素上(list,set, ...