前后端分离djangorestframework——分页组件
Pagination
为什么要分页也不用多说了,大家都懂,DRF也自带了分页组件
这次用 前后端分离djangorestframework——序列化与反序列化数据 文章里用到的数据,数据库用的mysql,因为django自带的sqlite对于日期类型的数据会自动转成时间戳,导致数据再序列化时无法正常序列化成日期类型而出错
分页组件还是跟前面的认证组件,权限组件,频率组件很类似的
PageNumberPagination
在根目录创建一个utils文件夹,在该文件夹里创建一个pagination文件,在其内定义一个分页组件类,继承自DRF里自带的PageNumberPagination类:
DRF的分页组件PageNumberPagination源码

且注意这两个方法,paginate_queryset和get_paginated_response,后面视图类里会用到
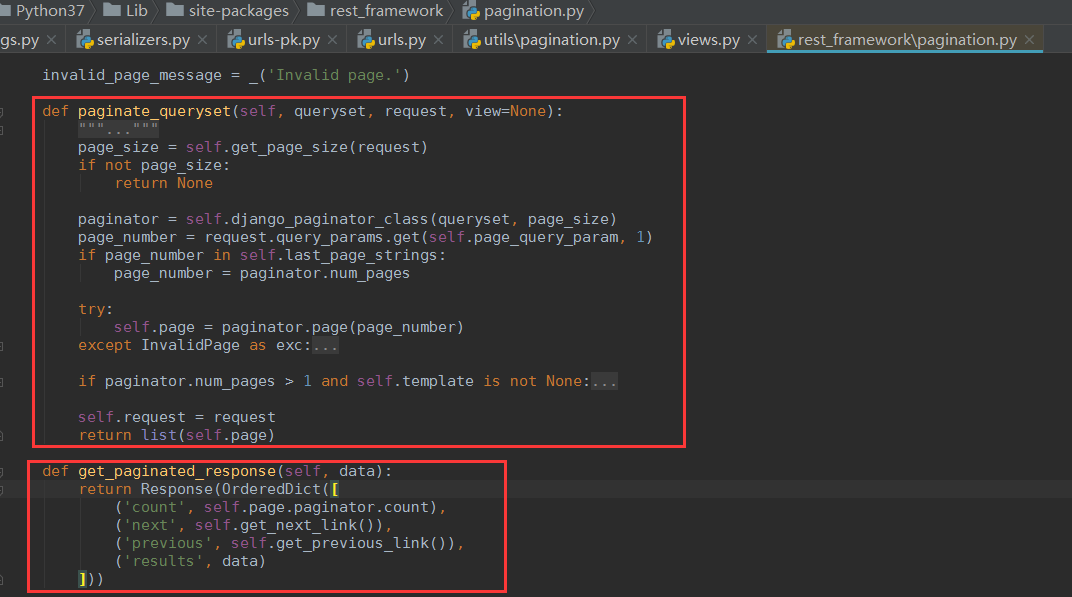
读django的源码,可知我们可以自定义一些属性或方法:
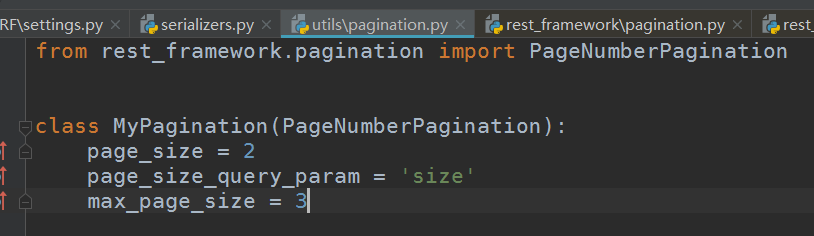
pagination:
url:
view:

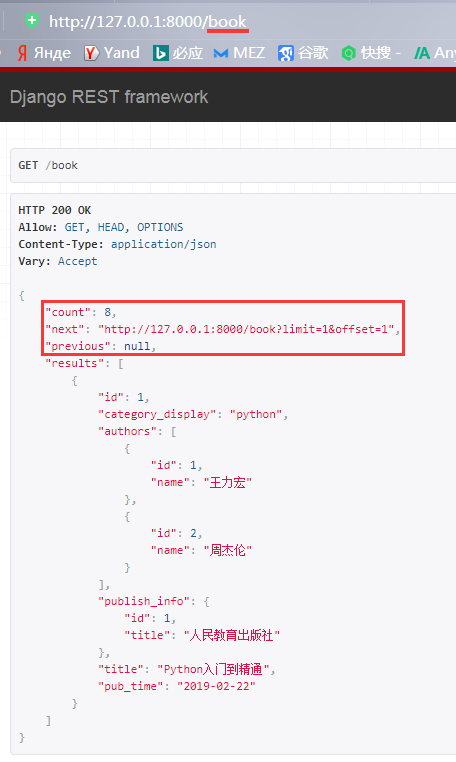
访问测试,显示一共8个数据,有上一页下一页,当前显示两个数据,这是刚才自定义分页组件时定义的

并且这个上一页下一页是可以直接点击的
相关代码:
pagination
from rest_framework.pagination import PageNumberPagination
class MyPagination(PageNumberPagination):
page_size = 2
page_size_query_param = 'size'
max_page_size = 3
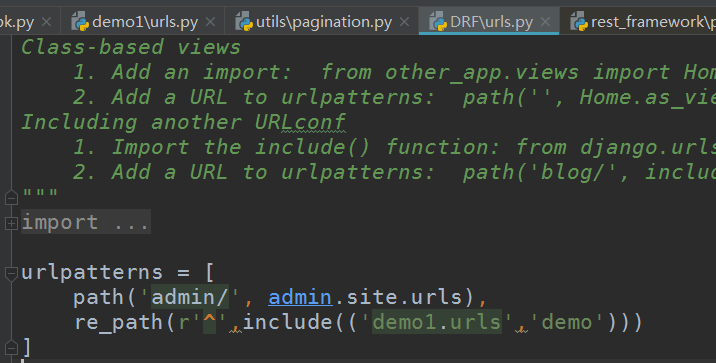
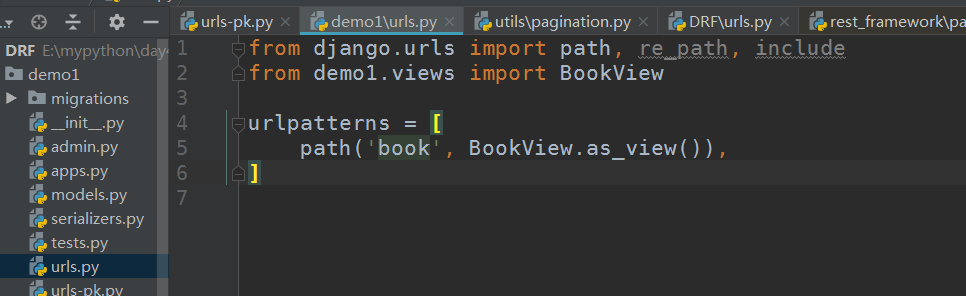
url:
from django.urls import path, re_path, include
from demo1.views import BookView
urlpatterns = [
path('book', BookView.as_view()),
]
view:
from demo1.serializers import BookSerializer
from rest_framework.views import APIView
from demo1.models import Book
from utils.pagination import MyPagination
class BookView(APIView):
def get(self, request):
queryset = Book.objects.all()
# 1,实例化分页器对象
page_obj = MyPagination()
# 2,调用分页方法去分页queryset
page_queryset = page_obj.paginate_queryset(queryset, request, view=self)
# 3,把分页好的数据序列化
ser_obj = BookSerializer(page_queryset, many=True)
# 4, 带着上一页下一页连接的响应
return page_obj.get_paginated_response(ser_obj.data)
serializer:
class BookSerializer(serializers.ModelSerializer):
category_display = serializers.SerializerMethodField(read_only=True)
authors = serializers.SerializerMethodField(read_only=True)
publish_info = serializers.SerializerMethodField(read_only=True)
def get_category_display(self, obj):
return obj.get_category_display()
def get_publish_info(self, obj):
publish_obj = obj.publisher
return {"id": publish_obj.id, 'title': publish_obj.title}
def get_authors(self, obj):
# obj是Book对象
author_list = obj.author.all()
return [{"id": author_obj.id, "name": author_obj.name} for author_obj in author_list]
class Meta:
model = models.Book
fields = '__all__'
# depth = 1 # 表示外键查找层级
extra_kwargs = {
"category": {"write_only": True}, "publisher": {"write_only": True},
"author": {"write_only": True},
}
LimitOffsetPagination
同样的自定义分页组件,并继承此类即可:
pagination,其中的两个属性是看LimitOffsetPagination的源码所得:

其他不用改,重启项目访问测试,一页只有一个数据,有上一页下一页的链接
并且上一页和下一页可以直接点击: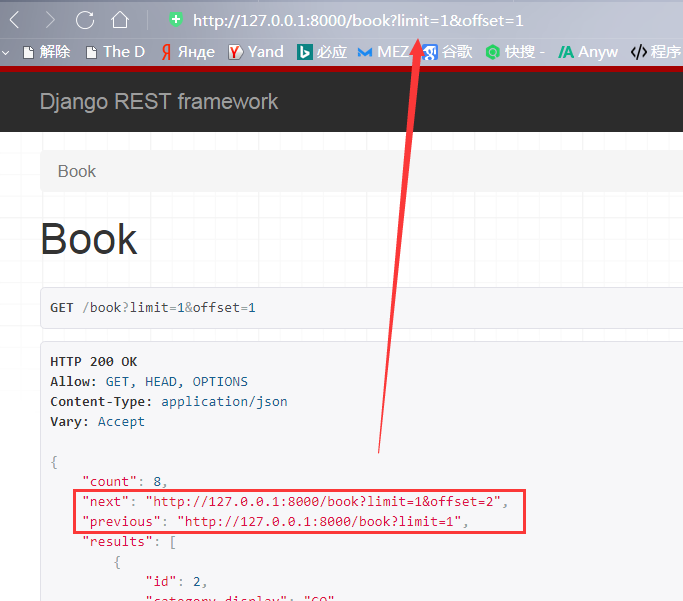
看起来好像和前面的PageNumberPagination差距不大对吧?LimitOffsetPagination,其参数offset是从第几个开始向后找,limit是只一次显示多少条数据的
当然你可以手动修改url的条件参数,从第一个开始找,每次显示8,这样就把我们本来就只有8个数据一起显示了
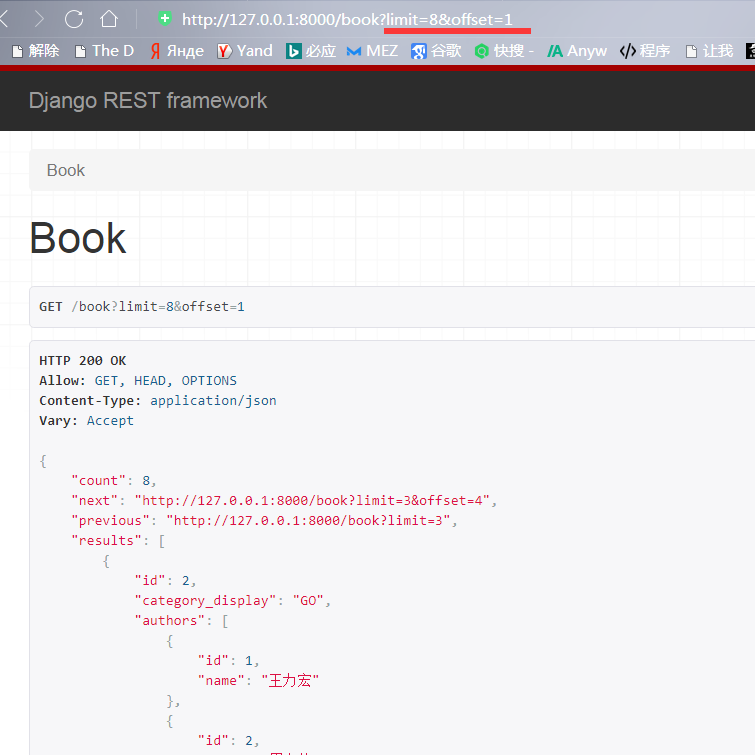
说到这,顺便说下,之前我们研究的Python爬虫, 有时候在爬数据时是发现网页没有刷新,但是是ajax异步请求,每次请求只显示一定数量的,就是因为有这个limit参数在,当时我们是怎么解决呢?就是直接在url后面修改limit参数,一次请求几百条数据或者多少都行,这样我们只请求了一次,但是这一下就拿到了多条数据,前面我们用的频率组件可以限制次数,到这我们一次请求拿几百或者几千这种的,就不好判断了
相关代码:
pagination:
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination
class MyPagination(LimitOffsetPagination):
default_limit = 1
max_limit = 3
view和url,serializers其实都没做任何更改:
from demo1.serializers import BookSerializer
from rest_framework.views import APIView
from demo1.models import Book
from utils.pagination import MyPagination
class BookView(APIView):
def get(self, request):
queryset = Book.objects.all()
# 1,实例化分页器对象
page_obj = MyPagination()
# 2,调用分页方法去分页queryset
page_queryset = page_obj.paginate_queryset(queryset, request, view=self)
# 3,把分页好的数据序列化
ser_obj = BookSerializer(page_queryset, many=True)
# 4, 带着上一页下一页连接的响应
return page_obj.get_paginated_response(ser_obj.data)
View
from django.urls import path, re_path, include
from demo1.views import BookView
urlpatterns = [
path('book', BookView.as_view()),
]
url
from rest_framework import serializers
from demo1 import models
class PublishSerializer(serializers.Serializer):
id = serializers.IntegerField()
title = serializers.CharField(max_length=32)
class AuthorSerializer(serializers.Serializer):
id = serializers.IntegerField()
name = serializers.CharField(max_length=32)
class BookSerializer(serializers.ModelSerializer):
category_display = serializers.SerializerMethodField(read_only=True)
authors = serializers.SerializerMethodField(read_only=True)
publish_info = serializers.SerializerMethodField(read_only=True)
def get_category_display(self, obj):
return obj.get_category_display()
def get_publish_info(self, obj):
publish_obj = obj.publisher
return {"id": publish_obj.id, 'title': publish_obj.title}
def get_authors(self, obj):
# obj是Book对象
author_list = obj.author.all()
return [{"id": author_obj.id, "name": author_obj.name} for author_obj in author_list]
class Meta:
model = models.Book
fields = '__all__'
# depth = 1 # 表示外键查找层级
extra_kwargs = {
"category": {"write_only": True}, "publisher": {"write_only": True},
"author": {"write_only": True},
}
serializers
CursorPagination
这个游标分页,可以对访问的url的条件参数隐藏,防止被人根据url的条件参数猜出我们的数据量,可能有潜在的隐患
pagination:

访问测试,按id为11(11为数据库里的最后一个数据)开始倒序排序
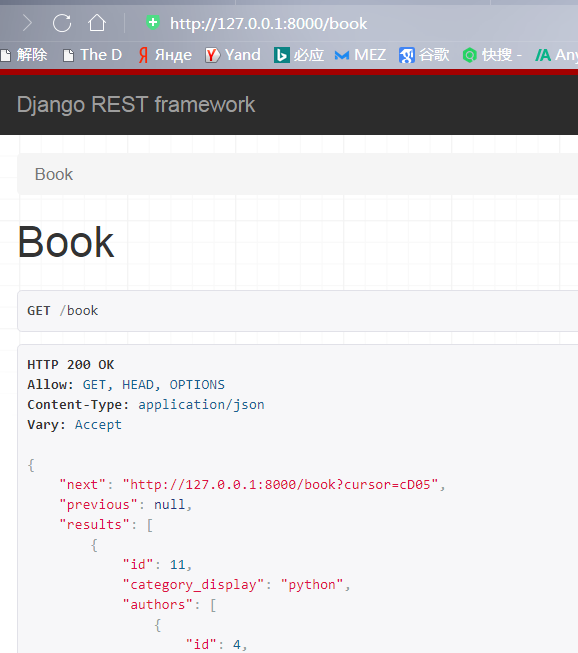
打开数据库,确实是倒序的
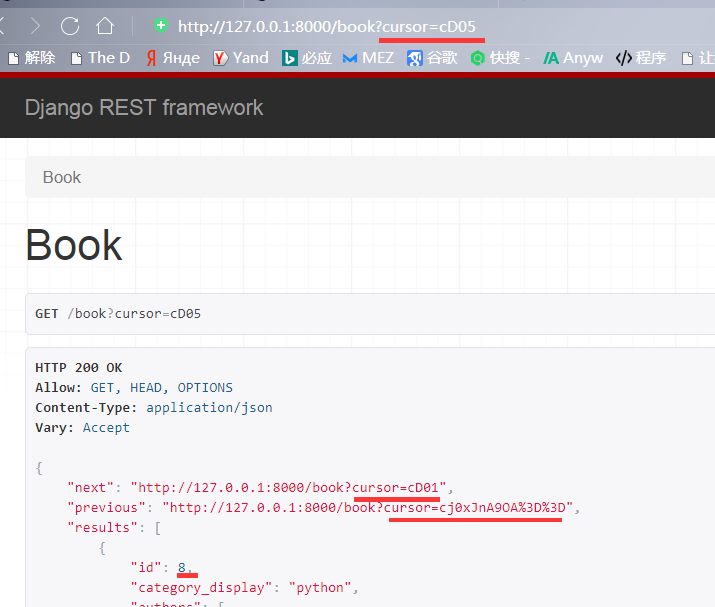
再点击上一页下一页,发现其参数是加密了的,根本无法通过这个条件参数猜解出我们的数据量
相关代码:
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
class MyPagination(CursorPagination):
page_size = 2
ordering = '-id' # 表示从哪个字段开始排序
pagination
其他没有做任何更改,不再贴出浪费篇幅了
当然,这个还是可以使用之前的Modelserializer来优化代码,

# coding:utf-8
from rest_framework.generics import GenericAPIView
from rest_framework.mixins import ListModelMixin
from demo1.serializers import BookSerializer
from demo1.models import Book
from utils.pagination import MyPagination
class BookView(GenericAPIView,ListModelMixin):
queryset = Book.objects.all()
serializer_class = BookSerializer
pagination_class = MyPagination
def get(self, request):
return self.list(request)
其他不用作任何更改,访问测试:
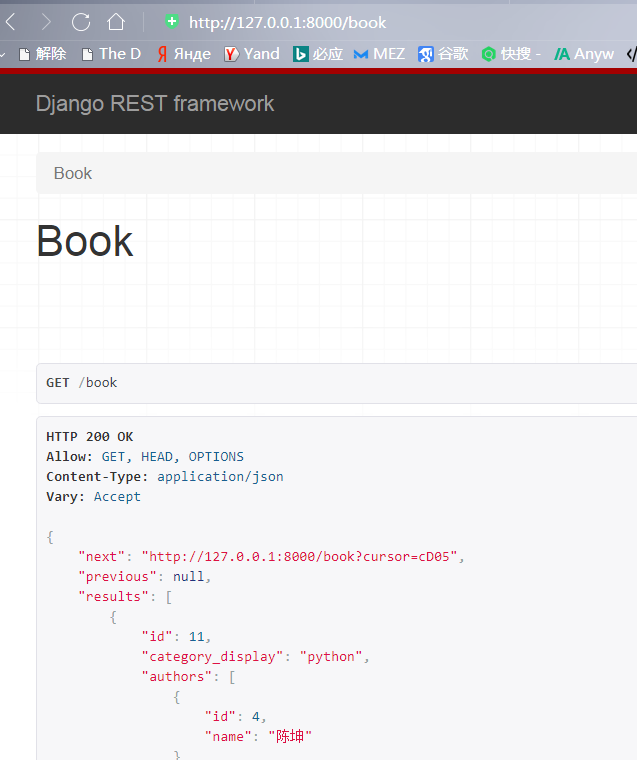
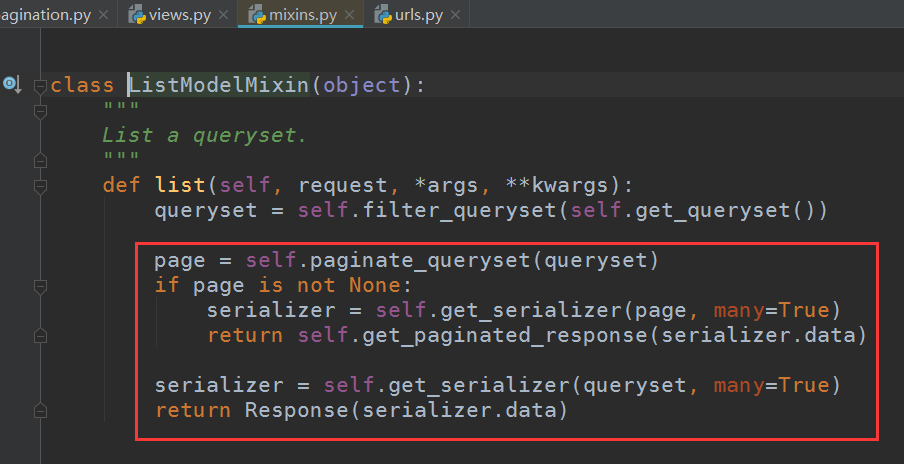
为什么这么方便,因为ListModelMixin中做了处理,假如有分页组件,那么就获取了分页的参数再返回:
总结:
多看源码,根据需求选用源码的分页组件类,设定相关的参数
前后端分离djangorestframework——分页组件的更多相关文章
- 前后端分离djangorestframework——路由组件
在文章前后端分离djangorestframework——视图组件 中,见识了DRF的视图组件强大,其实里面那个url也是可以自动生成的,就是这么屌 DefaultRouter urls文件作如下调整 ...
- 前后端分离djangorestframework——视图组件
CBV与FBV CBV之前说过就是在view.py里写视图类,在序列化时用过,FBV就是常用的视图函数,两者的功能都可以实现功能,但是在restful规范方面的话,CBV更方便,FBV还要用reque ...
- 前后端分离djangorestframework——认证组件
authentication 认证是干嘛的已经不需要多说.而前后端未分离的认证基本是用cookie或者session,前后端分离的一般用token 全局认证 先创建一个django项目,项目名为drf ...
- 前后端分离djangorestframework——ContentType组件表
ContentType ContentType其实django自带的,但是平时的话很少会用到,所以还是放在Djangorestframework这个部分 作用: 在实际的开发中,由于数据库量级大,所以 ...
- 前后端分离djangorestframework——权限组件
权限permissions 权限验证必须要在认证之后验证 权限组件也不用多说,读了源码你就很清楚了,跟认证组件很类似 具体的源码就不展示,自己去读吧,都在这里: 局部权限 设置model表,其中的ty ...
- 前后端分离djangorestframework—— 在线视频平台接入第三方加密防盗录视频
加密视频 在以后的开发项目中,很可能有做在线视频的,而在线视频就有个问题,因为在线播放,就很有可能视频数据被抓包,如果这个在线视频平台有付费视频的话,这样就会有人做点倒卖视频的生意了,针对这个问题,目 ...
- 前后端分离djangorestframework—— 接入第三方的验证码平台
关于验证码部分,在我这篇文章里说的挺详细的了:Python高级应用(3)—— 为你的项目添加验证码 这里还是再给一个前后端分离的实例,因为极验官网给的是用session作为验证的,而我们做前后端分离的 ...
- 前后端分离djangorestframework——序列化与反序列化数据
我们写好后端的代码,要把数据交给前端的展示的,这个数据以什么类型给前端呢?学到这里,我们已经知道这个数据最好是json字符串才行,因为网络间的传输,只认字符串或者二进制,字符串就是我们的数据,二进制就 ...
- 前后端分离djangorestframework——restful规范
restful现在非常流行,所以很有必要提一下 web服务交互 在浏览器中能看到的每个网站,都是一个web服务.那么我们在提供每个web服务的时候,都需要前后端交互,前后端交互就一定有一些实现方案,我 ...
随机推荐
- Chapter 4 Invitations——10
"Mr. Cullen?" the teacher called, seeking the answer to a question that I hadn't heard. “C ...
- eclipse连接github,链接不上 cannot open git-upload-pack(git-receive-pack)
2018年2月8日后禁止通过TLSv1.1协议连接https://github.com 和 https://api.github.com. 原文地址为https://githubengineering ...
- 【API知识】RestTemplate的使用
前言 在某种情况下,后台服务可能需要访问另一台服务器的REST接口.以前估计不少人用的都是HttpRequest类来着,结合Paser解析JSON格式的Body.现在Spring Boot的Web S ...
- 手把手使用Docker搭建SpringBoot微服务镜像
一.环境准备 1.安装好Docker环境的Linux机器(安装教程) 2.准备好SpringBoot项目打包好的可运行jar包 二.编写Dockerfile 1.首先将SpringBoot打包好的ja ...
- Jenkins结合.net平台工具之Opencover
首先先介绍一下Opencover是什么,Opencover是.net平台下用于生成单元测试覆盖率报告的一款软件,是.net平台下为数不多的一款免费覆盖率报告工具,类似的工具还有Jetbrains的do ...
- MySQL的binlog恢复(Windows下)
前言 在最近的工作中,由于自己粗(zuo)心(si)误update操作导致几百行的数据出现错误,在心急如焚的同时(那时候我竟然不知道除了备份之后还有binlog日志恢复)立马查资料学习binlog的恢 ...
- OJ:自己实现一个简单的 priority_queue
Description 补足程序,使得下面程序输出结果是: 1.8 2.4 3.8 4.9 8.8 #include <iostream> #include <algorithm&g ...
- 杭电ACM2002--计算球体积
计算球体积 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...
- JDBC&Hibernate
当数据库有大量用户来访问要采取什么技术解决 可以采用连接池: 什么是ORM 对象关系映射(Object Relational Mapping 简称ORM)是一种为了解决面向对象与面向关系数据库存在的互 ...
- tomcat开启自启动
linux方式 #!/bin/bash #chkconfig: #description: Starts and Stops the Tomcat daemon. #by benjamin ##### ...