hadoop1.2.1的安装
前提:1.机器最好都做ssh免密登录,最后在启动hadoop的时候会简单很多 免密登录看免密登录
2.集群中的虚拟机最好都关闭防火墙,否则很麻烦
3集群中的虚拟机中必须安装jdk.
具体安装步骤如下:
1.将 文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
文件拷贝到linux系统中(可以拷贝到所以的虚拟机,也可以拷贝到一台虚拟机,最后进行复制)
2.解压到/usr/local/hadoop ,看你需要安装到哪个目录就解压到哪个目录,解压命令 tar -zxvf ~/hadoop-1.2.1-bin.tar.gz -C /usr/local/hadoop ,解压完成就安装完了
接下来就应该修改配置文件
3.配置namenode和数据存储的位置,修改安装后hadoop-1.1.2下的conf文件夹下的core.site.xml文件
添加如下信息:(配置的namenode的ip和hadoop临时文件的地址)
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node05:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-1.2</value>
</property>
</configuration>
core-site.xml
4.配置节点数(datanode) 编辑slaves文件
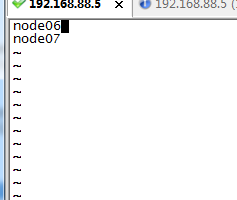
5.配置SecondaryNameNode,编辑masters文件,配置如下:
我一共用了三台虚拟机,node05是我的namenode节点.,node06,node07是我的datanode节点.同时node06也是我的SecondaryNameNode节点

6.配置数据的副本数 编辑hdfs-site.xml文件(副本数应该小于等于datanode的数量)
具体配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
hdfs-site.xml
7.将我们安装的hadoop复制到其余几台虚拟机中,注意配置文件保持一致,否则会失败
8.格式化namenode,到hadoop安装后的bin目录下执行 ./hadoop namenode -format命令
如果出现Error:JAVA_HOME.....错误 请在hadoop 的conf目录下的hadoop-env.sh文件中配置如下:

9.接下来就可以启动hadoop了
启动的时候,到bin目录下执行 ./start-dfs.sh命令,(因为我这里没有安装hdfs所以执行的这个命令)
10:测试是否成功,在每台虚拟机中输入jps测试是否启动成功
node05:namenode:
node06(是datanode也是SecondaryNameNode)
node07 datanode: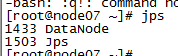
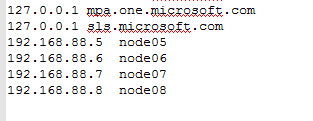
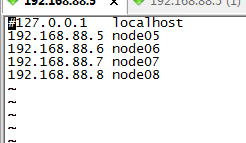
11,在物理机中,修改hosts文件,将我们的集群的ip和域名添加进去:
访问我们的namenode查看hadoop集群信息
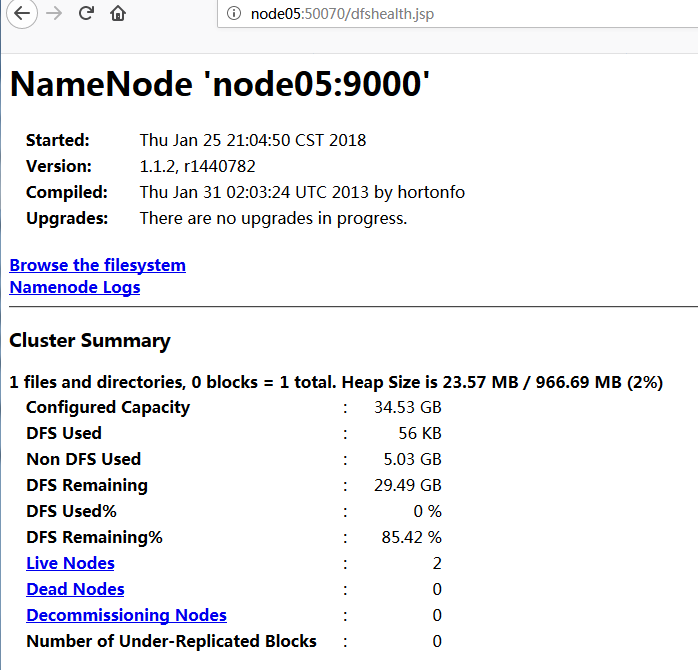
Live Nodes的节点数正确为2
如果Live Nodes的值为0
启动过程中动态查看hadoop的日志文件tail -f /usr/local/hadoop/hadoop-1.1.2/logs/hadoop-root-namenode-node05.log 查看有哪些错误,
如过提示
2018-01-25 20:54:09,903 INFO org.apache.hadoop.hdfs.server.namenode.DecommissionManager: Interrupted Monitor
java.lang.InterruptedException: sleep interrupted
修改/etc/hosts文件
hadoop1.2.1的安装的更多相关文章
- hbase-0.94.16 在hadoop-1.2.1的安装配置
1. ZooKeeper的安装: ZooKeeper是一个分布式的服务框架.可用于处理分布式的一些数据管理问题,如统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理等. 步骤如下: a. 准 ...
- Hadoop1.x集群安装部署(VMware)
一.hadoop版本介绍 不收费的Hadoop版本主要有三个(均是国外厂商),分别是:Apache(最原始的版本,所有发行版均基于这个版本进行改进).Cloudera版本(Cloudera’s Dis ...
- 安装hadoop集群服务器(hadoop1.2.1)
摘要:hadoop,一个分布式系统基础架构,可以充分利用集群的威力进行高速运算和存储.本文主要介绍hadoop的安装与集群服务器的配置. 准备文件: ▪ VMware11.0.0 ▪ Cen ...
- Hadoop1.0.3安装部署
0x00 大数据平台相关链接 官网:http://hadoop.apache.org/ 主要参考教程:http://www.cnblogs.com/xia520pi/archive/2012/05/1 ...
- hadoop1.2.1+hbase0.94.11+nutch2.2.1+elasticsearch0.90.5安装配置攻略
一.背景 最近由于项目和论文的需要,需要搭建一个垂直搜索的环境,查阅了很多资料,决定使用Apache的一套解决方案hadoop+hbase+nutch+es.这几样神器的作用就不多作介绍了,自行参考各 ...
- Hadoop入门进阶课程1--Hadoop1.X伪分布式安装
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,博主为石山园,博客地址为 http://www.cnblogs.com/shishanyuan ...
- 面向生产环境的大集群模式安装Hadoop
一.实验说明 1.本实验将使用DNS而不是hosts文件解析主机名: 2.使用NFS共享密钥文件,而不是逐个手工拷贝添加密钥: 3.复制Hadoop时使用批量拷贝脚本而不是逐台复制. 测试环境: Ho ...
- Hadoop安装(Ubuntu Kylin 14.04)
安装环境:ubuntu kylin 14.04 haoop-1.2.1 hadoop下载地址:http://apache.mesi.com.ar/hadoop/common/hadoop-1. ...
- hadoop 1.2.1 安装步骤 伪分布式
最近在系统的学习hadoop 课程第一步是安装hadoop1.x,具体安装步骤如下: 一.系统安装 本文使用centos6.5安装,具体安装步骤省略 二.jdk安装 下载jdk1.7.0_51解压,在 ...
随机推荐
- django rest framework mixins
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAXQAAAEZCAIAAAAIa0mAAAAU/0lEQVR4nO2d247cxoGG5y3yKH6AAf
- scrapy 选择器
1.lxml(转自简书) from lxml import etree2 import requests3 45 url = " "6 html = requests.get(ur ...
- Python3 与 C# 扩展之~基础衍生
本文适应人群:C# or Python3 基础巩固 代码裤子: https://github.com/lotapp/BaseCode 在线编程: https://mybinder.org/v2/g ...
- JSP、EL、JSTL
JSP(Java Server Pages) 什么是JSP Java Server Pages(Java服务器端的页面) 使用JSP:SP = HTML + Java代码 + JSP自身的东西.执行J ...
- 百度地图API,展示地图和添加控件
1.申请百度账号和AK 点我申请 2.准备页面 根据HTML标准,每一份HTML文档都应该声明正确的文档类型,我们建议您使用最新的符合HTML5规范的文档声明: <!DOCTYPE html&g ...
- P1886 P2216 单调队列模板
何为单调队列? 单调队列是一个队列(废话) 而且必须同时满足下标单调和值单调两个单调特性. 跟优先队列不同,优先队列直接使用堆(heap)来实现,如何删去特定下标元素?不明. 本人喜欢用单调队列存下标 ...
- 线性筛prime/phi/miu/求逆元模板
这绿题贼水...... 原理我不讲了,随便拿张草稿纸推一下就明白了. #include <cstdio> using namespace std; ; int su[N],ans,top; ...
- Python中pandas dataframe删除一行或一列:drop函数
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 参数说明:labels 就是要删除的行列的 ...
- POJ-1077 HDU 1043 HDU 3567 Eight (BFS预处理+康拓展开)
思路: 这三个题是一个比一个令人纠结呀. POJ-1077 爆搜可以过,94ms,注意不能用map就是了. #include<iostream> #include<stack> ...
- (栈)leetcode 946. Validate Stack Sequences
Given two sequences pushed and popped with distinct values, return true if and only if this could ha ...