用Python爬取"王者农药"英雄皮肤

0.引言
作为一款现象级游戏,王者荣耀,想必大家都玩过或听过,游戏里中各式各样的英雄,每款皮肤都非常精美,用做电脑壁纸再合适不过了。本篇就来教大家如何使用Python来爬取这些精美的英雄皮肤。
1.环境
操作系统:Windows / Linux
Python版本:3.7.2
2.需求分析
我们打开《王者荣耀》官网,找定位到英雄列表的页面
可直接点此链接:
https://pvp.qq.com/web201605/herolist.shtml 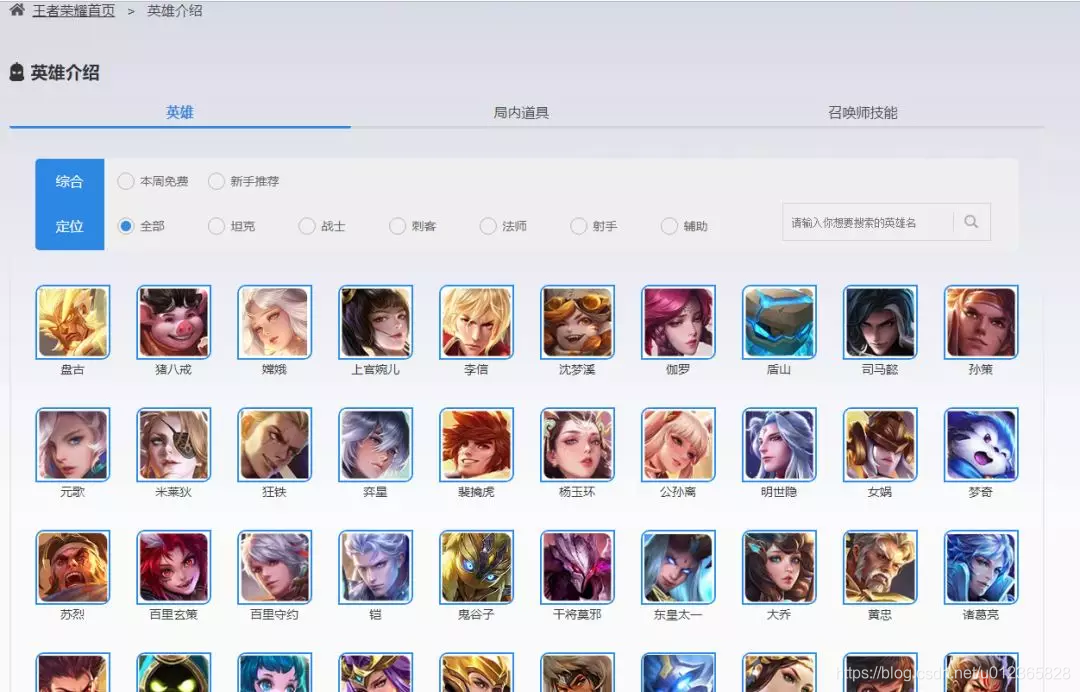
在这个网页中包含了所有的英雄,头像及英雄名称。点击其中一个英雄的头像,如“嫦娥”,进去后如下图:
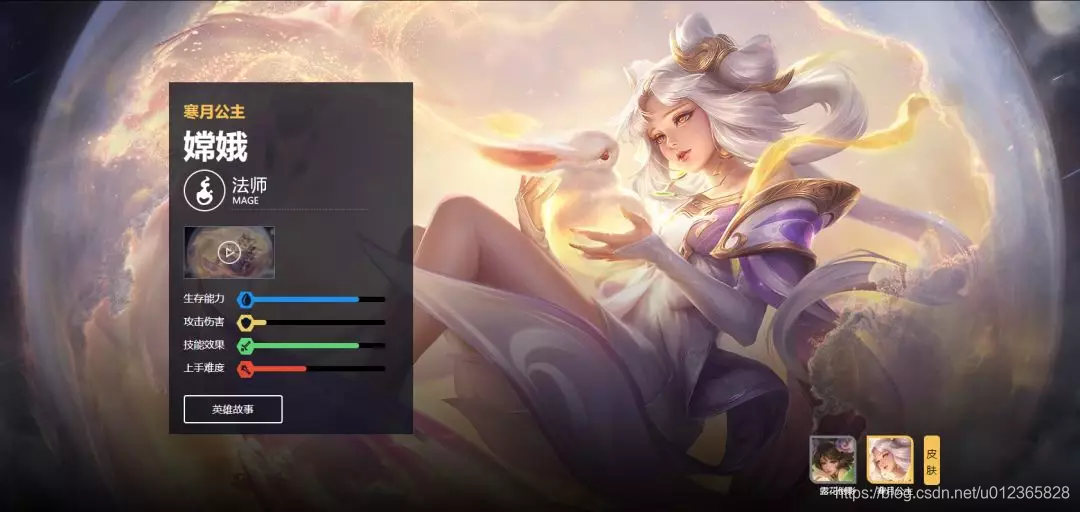
我们记下此时的网址
https://pvp.qq.com/web201605/herodetail/515.shtml
再后退到英雄列表页面,点“甄姬”进去查看:
https://pvp.qq.com/web201605/herodetail/127.shtml
可以看到这些网址几乎是固定不变的,变化的只是515、127这些数字,这些其实就是代表的英雄数字编号。
那么第一个关键点就来了,怎么找出各个英雄所对应的数字编号呢?
我们回到最初的英雄列表页面,打开浏览器的开发者工具,刷新页面、仔细观察,你会找到一个herolist.json的文件,如图所示:
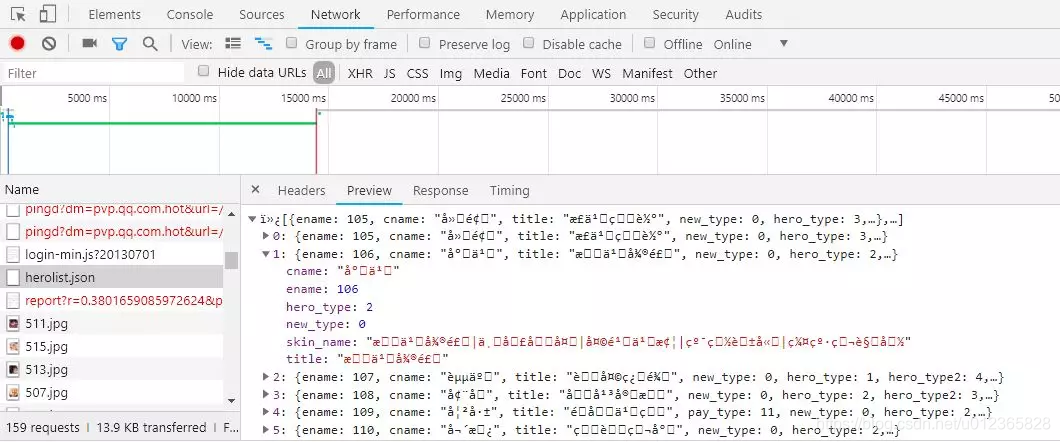
这里记录了各个英雄的信息,其中就包含了每个英雄对应的数字编号了,请忽略这里截图中的乱码显示。我们切到herolist.json中的Headers,就可以拿到该请求的URL地址,进而就可以把英雄及其对应的数字,编号都提取出来了。
有了英雄编号的对应关系,再找寻下英雄皮肤的链接规律。
现在重新进入一个英雄的网址,打开浏览器的开发者工具,刷新页面,在Network下刷新并找到英雄的皮肤图片,如图所示:
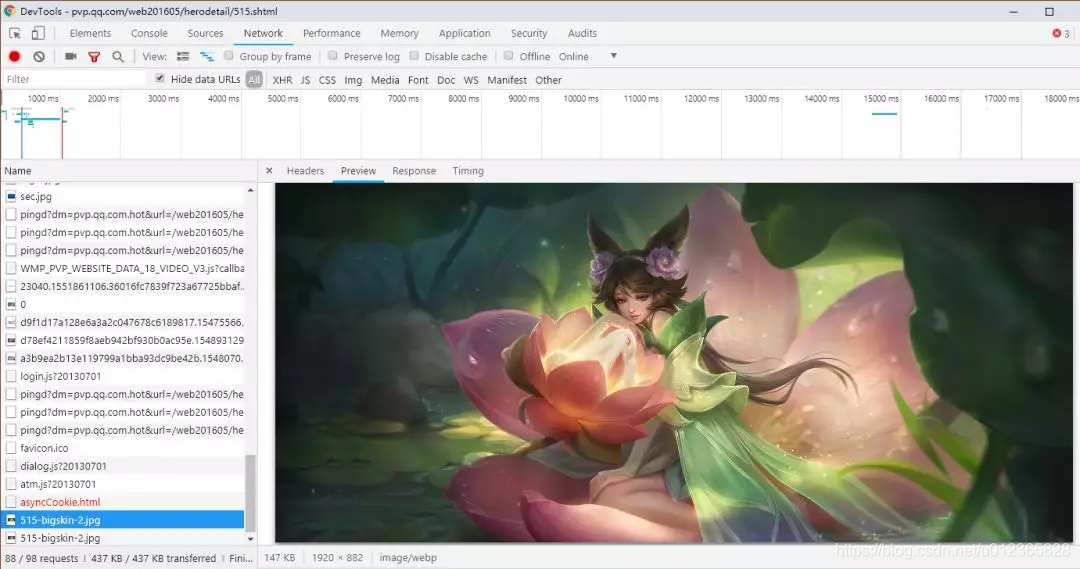
在Headers中查看该图片的网址,查看即Request URL处的链接:
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/515/515-bigskin-1.jpg
{kind=link}
找寻一个看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/529/529-bigskin-1.jpg
{kind=link}
继续寻一个看看
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/127/127-bigskin-4.jpg
{kind=link}
仔细分析如上三个链接,我们可以把英雄皮肤的URL拆分开来看。它是由一个固定前缀(我们可以记为base_url),再加上英雄数字编号、"bigskin"、皮肤编号、".jpg"组合而成,如下:
base_url / hero_num / hero_num - bigskin - heroskin_num .jpg
拿到了各个英雄皮肤的URL地址后,我们就可以进行图片的下载并保存在本地了。
3.代码演示
首先导入我们所用到的模块
import requests
import os
注:requests是非内置模块,若环境中没有,需自行安装:
pip install requests
3.1 提取英雄名字及数字
使用herolist.json拿到herolist,并提取出我们关心的内容
# 英雄的名字json
url = 'http://pvp.qq.com/web201605/js/herolist.json'
head = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'}
response = requests.get(url, headers=head)
hero_list = response.json()
# 提取英雄名字和数字
hero_name=list(map(lambda x:x['cname'], hero_list))
hero_number=list(map(lambda x:x['ename'], hero_list))
3.2 构造英雄皮肤的URL
首先准备好我们的BASE_URL,即英雄皮肤的固定前缀。
h_l='http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/'
接下来构造好英雄皮肤的URL,同时我们需要对每一个英雄的所有皮肤进行遍历,如下:
# 逐一遍历英雄
for i in hero_number:
# 逐一遍历皮肤,此处假定一个英雄最多有15个皮肤
for sk_num in range(15):
hsl = h_l + str(i)+'/'+str(i)+'-bigskin-'+str(sk_num)+'.jpg'
hl = requests.get(hsl)
3.3 存储图片
最后我们就只需将获取到的图片保存在本地即可。
# 将图片保存下来,并以"英雄名称_皮肤序号"方式命名
with open(hero_name[num] + str(sk_num) + '.jpg', 'wb') as f:
f.write(hl.content)
4.效果展示
最终的爬取效果如下图所示。
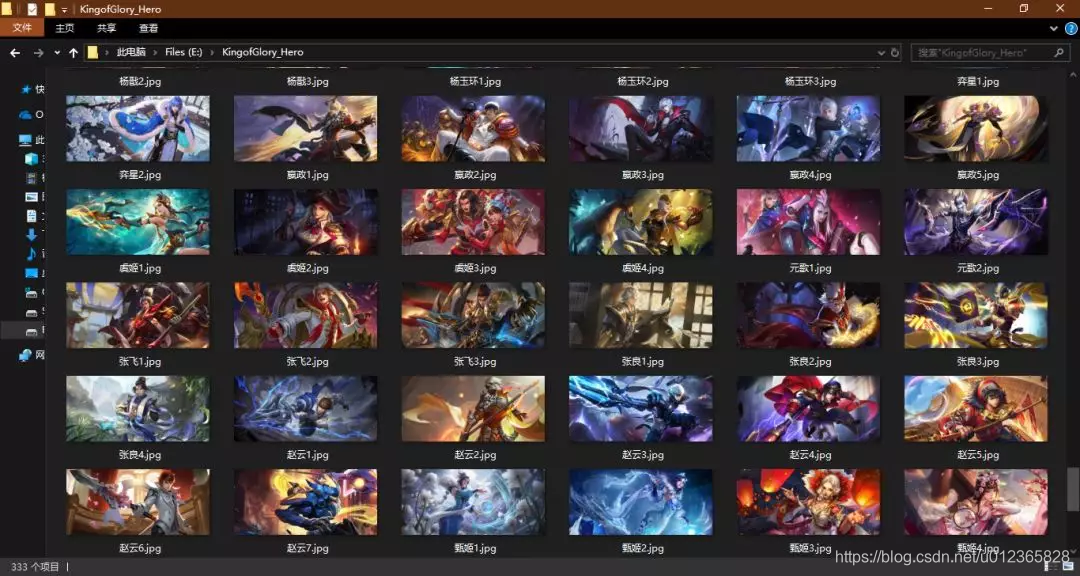
5.总结
短短几十行代码就可以把心爱英雄的精美皮肤保存下来,赶快实操起来吧!
关注公众号「Python专栏」,后台回复「zsxq04」,获取本文全套源码!

用Python爬取"王者农药"英雄皮肤的更多相关文章
- 用Python爬取"王者农药"英雄皮肤 原
padding: 10px; border-bottom: 1px solid #d3d3d3; background-color: #2e8b57; } .second-menu-item { pa ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- python 爬取王者荣耀英雄皮肤代码
import os, time, requests, json, re, sys from retrying import retry from urllib import parse "& ...
- 利用python爬取王者荣耀英雄皮肤图片
前两天看到同学用python爬下来LOL的皮肤图片,感觉挺有趣的,我也想试试,于是决定来爬一爬王者荣耀的英雄和皮肤图片. 首先,我们找到王者的官网http://pvp.qq.com/web201605 ...
- python学习--第二天 爬取王者荣耀英雄皮肤
今天目的是爬取所有英雄皮肤 在爬取所有之前,先完成一张皮肤的爬取 打开anacond调出编译器Jupyter Notebook 打开王者荣耀官网 下拉找到位于网页右边的英雄/皮肤 点击[+更多] 进入 ...
- Python 爬取 "王者荣耀.英雄壁纸" 过程中的矛和盾
1. 前言 学习爬虫,最好的方式就是自己编写爬虫程序. 爬取目标网站上的数据,理论上讲是简单的,无非就是分析页面中的资源链接.然后下载.最后保存. 但是在实施过程却会遇到一些阻碍. 很多网站为了阻止爬 ...
- python爬取王者荣耀全英雄皮肤
import os import requests url = 'https://pvp.qq.com/web201605/js/herolist.json' herolist = requests. ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
随机推荐
- 关于四种语言中substring()方法参数值的解析
1.关于substring(a,b)Js var str="bdqn"; var result=str.substring(1,2); alert(result); 第一个参数:开 ...
- vue项目运行
共分为以下六步: 1.安装node.js2.安装cnpm3.安装vue-cli脚手架构建工具4.用vue-cli构建项目5.安装项目所需的依赖6.运行项目 第1步:从node.js官网下载node.j ...
- n2n网络环境搭建
目的: 实现家中nas,在任何环境ssh访问 方案:n2n v1 (原因稳定&兼容macbook) 开源地址: https://svn.ntop.org/svn/ntop/trunk/n2 ...
- 详解js跨域
什么是跨域? 概念:只要协议.域名.端口有任何一个不同,都被当作是不同的域. 对于端口和协议的不同,只能通过后台来解决.URL 说明 是否允许通信 http://www.a.com/a.js http ...
- 获取window.location.href中传的值,并且转换成json数据使用
做个记录保存一下,以免以后再次用到忘记了. function locVal(){ var url=window.location.href; if (url.indexOf('?')==-1)retu ...
- eclipse新建servers时选中tomcat版本后next是灰色的解决
有时在编辑器里删除server后就不能重新new了,因为不能点next. 试了下面的方法,可以用. 1.退出2.到[工程目录下]/.metadata/.plugins/org.eclipse.core ...
- Effective C++ 笔记:条款 34 实现继承和接口继承
Differentiate between inheritance of interface and inheritance of implementation. 行为含义 声明一个pure virt ...
- 20175316 盛茂淞 2018-2019-2 《Java程序设计》实验二 面向对象程序设计 实验报告
20175316 盛茂淞 2018-2019-2 <Java程序设计>实验二 面向对象程序设计 实验报告 (一)单元测试 在 IDEA中我们把产品代码放在src目录中,把测试代码放在tes ...
- WEB服务器搭建(Apache+Tomcat+eclipse)
1.下载xampp安装,选择Apache+MySQL+Tomcat 官方下载链接:https://www.apachefriends.org/zh_cn/download.html 2.下载安装jav ...
- html图片上传阅览并且点击放大
关闭 qq_31540195的博客 目录视图 摘要视图 订阅 异步赠书:9月重磅新书升级,本本经典 程序员9月书讯 每周荐书: ...