CAS 无锁式同步机制
计算机系统中,CPU 和内存之间是通过总线进行通信的,当某个线程占有 CPU 执行指令的时候,会尽可能的将一些需要从内存中访问的变量缓存在自己的高速缓存区中,而修改也不会立即映射到内存。
而此时,其他线程将看不到内存中该变量的任何改动,这就是我们说的内存可见性问题。连续的文章中,我们总共提出了两种解决办法。
其一是使用关键字 volatile 修饰共享的全局变量,而 volatile 的实现原理大致分两个步骤,任何对于该变量的修改操作都会由虚拟机追加一条指令立马将该变量所在缓存区中的值回写内存,接着将失效该变量在其他 CPU 缓存区的引用。也就意味着,其他 CPU 如果再想要使用该变量,缓存中是没有的,进而逼迫去访问内存拿最新的数据。
其二是使用关键字 synchronized 并借助对象内置锁实现数据一致性,主要思路是,如果一个线程因为竞争某个锁失败而被阻塞了,那么它就认为别的线程正在工作,很可能会改了某些共享变量的数据,进而在获得锁后第一时间重新刷内存中的数据,同时一个线程走出同步代码块之前会同步数据到内存。
其实我们也很少会使用第二种方法来解决内存可见性问题,着实有点大材小用的感觉,使用 volatile 关键字算是一个比较常用的方式。但是 volatile 是有特定的适用场景的,也具有它的局限性,我们一起来看。
volatile 的局限性
废话不多说,先看一段代码:
public class MainTest {
private static volatile int count;
@Test
public void testVolatile() throws InterruptedException {
Thread1[] thread1s = new Thread1[100];
for (int i = 0; i < 100; i++){
thread1s[i] = new Thread1();
thread1s[i].start();
}
for (int j = 0; j < 100; j++){
thread1s[j].join();
}
System.out.println(count);
}
//每个线程随机自增 count
private class Thread1 extends Thread{
@Override
public void run(){
try {
Thread.sleep((long) (Math.random() * 500));
} catch (InterruptedException e) {
e.printStackTrace();
}
count++;
}
}
}
我们将变量 count 使用 volatile 进行修饰,然后创建一百个线程并启动,按照我们之前的理解,变量 count 的值一旦被修改就可以被其他线程立马看到,不会缓存在自己的工作内存。但是结果却不是这样。
多次运行,结果不尽相同
94
96
98
....
其实原因很简单,我们只说过 volatile 会在变量值被修改后回写内存并失效其他 CPU 缓存中该变量的引用迫使其他线程从主存中重新去获取该变量的值。
但是 count++ 这个操作并不是原子操作,之前我们说过这一点,这个操作会使得 CPU 做以下几件事情:
- 从 CPU 缓存读出变量的值放入寄存器 A 中
- 为 count 加一并将值保存在另一个寄存器 B 中
- 将寄存器 B 中的数据写到缓存并通过缓存锁回写内存
而如果第一步刚执行结束,或第二步刚执行结束,但没有执行第三步的时候,其他的某个线程更改了该变量的值并失效了当前 CPU 中缓存中该变量的引用,那么第三步会由于缓存失效而先去内存中读一个值过来,然后用寄存器 B 中的值覆盖缓存并刷到内存中。
这就意味着,在此之前其他线程的修改被覆盖,进而我们得不到我们预期的结果。结论就是,volatile 关键字具有可见性而不具有原子性。
原子类型变量
JDK1.5 以后由 Doug Lea 大神设计的 java.util.concurrent.atomic 包中包含了原子类型相关的所有类。
其中,
- AtomicBoolean:对应的 Boolean 类型的原子类型
- AtomicInteger:对应的 Integer 类型的原子类型
- AtomicLong:类似
- AtomicIntegerArray:对应的数组类型
- AtomicLongArray:类似
- AtomicReference:对应的引用类型的原子类型
- AtomicIntegerFieldUpdater:字段更新类型
剩余的几个类的作用,我们稍后再详细介绍。
针对基本类型所对应的原子类型,我们以 AtomicInteger 这个类为例,看看它的源码实现情况。
AtomicInteger 相关实现
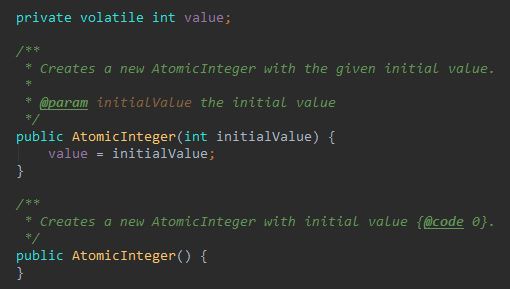
内部定义了一个 int 类型的变量 value,并且 value 修饰为 volatile,表示 value 这个字段值的任何修改都对其他线程立即可见。
而构造函数允许你传入一个初始的 value 数值,不传的话就会导致 value 的值为零。
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
这个方法就是原子的「i++」操作,我们跟进去看:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
几个参数简单说一下,var1 是我们的 AtomicInteger 实例引用,var2 是一个字段偏移量,通过它我们可以定位到其中的 value 字段。var4 这里固定为一。
代码的逻辑也是简单的,取出内部 value 字段的值并暂存在变量 value5 中,然后再次判断,如果 value 字段的值依然等于 value5,那么将原子操作式将 value 修改为 value4 + value5,本质上就是加一。
否则,说明在当前线程上次访问后,又有其他线程修改了这个 value 字段的值,于是我们重新获取这个字段的值,直到没有人修改为止并自增它。
这个 compareAndSwapInt 方法我们一般把它叫做『CAS』,底层有系统指令做支撑,是一个比较并修改的原子指令,如果值等于 A 则将它修改为 B,否则返回。
AtomicInteger 中的其余方法大致类似,都是依赖这个『CAS』方法实现的。
- int getAndAdd(int delta):自增 delta 并获取修改之前的值
- int incrementAndGet():自增并获取修改后的值
- int decrementAndGet():自减并获取修改后的值
- int addAndGet(int delta):自增 delta 并获取修改后的值
基于这一点,我们重构上述的线程不安全的 demo:
//构建一个原子类型变量 aCount
private static volatile AtomicInteger aCount = new AtomicInteger(0);
@Test
public void testAtomic() throws InterruptedException {
Thread2[] threads = new Thread2[100];
for (int i = 0; i < 100; i++){
threads[i] = new Thread2();
threads[i].start();
}
for (int i = 0; i < 100; i++){
threads[i].join();
}
System.out.println(aCount.get());
}
private class Thread2 extends Thread{
@Override
public void run(){
try {
Thread.sleep((long) (500 * Math.random()));
} catch (InterruptedException e) {
e.printStackTrace();
}
//原子自增
aCount.getAndIncrement();
}
}
修改后的代码无论运行多少次,总会得到结果 100 。有关 AtomicLong、AtomicReference 的相关内容大致类似,都是依赖我们这个『CAS』方法,这里不再赘述。
FieldUpdater 是基于反射来原子修改变量的值,这里不多说了,下面我们看看『CAS』的一些问题。
CAS 的局限性
ABA 问题
CAS 有一个典型问题就是「ABA 问题」,我们知道 CAS 工作的基本原理是,先读取目标变量的值,然后调用原子指令判断该值是否等于我们期望的值,如果等于就认为没有被别人改过,否则视作数据脏了,重新去读变量的值。
但是问题是,如果变量 a 的值为 100,我们的 CAS 方法也读到了 100,接着来了一个线程将这个变量改为 999,之后又来一个线程再改了一下,改成 100 。而轮到我们的主线程发现 a 的值依然是 100,它视作没有人和它竞争修改 a 变量,于是修改 a 的值。
这种情况,虽然 CAS 会更新成功,但是会存在潜在的问题,中途加入的线程的操作对于后一个线程根本是不可见的。而一般的解决办法是为每一次操作加上加时间戳,CAS 不仅关注变量的原始值,还关注上一次修改时间。
循环时间长开销大
我们的 CAS 方法一般都定义在一个循环里面,直到修改成功才会退出循环,如果在某些并发量较大的情况下,变量的值始终被别的线程修改,本线程始终在循环里做判断比较旧值,效率低下。
所以说,CAS 适用于并发量不是很高的情况下,效率远远高于锁机制。
只能保证一个变量的原子操作
CAS 只能对一个变量进行原子性操作,而锁机制则不同,获得锁之后,就可以对所有的共享变量进行修改而不会发生任何问题,因为别人没有锁不能修改这些共享变量。
总结一下,锁其实是一种悲观的思想,「我认为所有人都会和我来竞争某些资源的使用,所以我得到资源之后把它锁上,用完再释放掉锁」,而 CAS 则是一种乐观的思想,「我以为只有我一个人在使用这些资源,假如有人也在使用,那我再次尝试即可」。
CAS 是以后的各种并发容器的实现基石,是一种乐观的、非阻塞式的算法,将有助于提升我们的并发性能。
文章中的所有代码、图片、文件都云存储在我的 GitHub 上:
(https://github.com/SingleYam/overview_java)
欢迎关注微信公众号:OneJavaCoder,所有文章都将同步在公众号上。

CAS 无锁式同步机制的更多相关文章
- CAS无锁机制原理
原子类 java.util.concurrent.atomic包:原子类的小工具包,支持在单个变量上解除锁的线程安全编程 原子变量类相当于一种泛化的 volatile 变量,能够支持原子的和有条件的读 ...
- java并发:AtomicInteger 以及CAS无锁算法【转载】
1 AtomicInteger解析 众所周知,在多线程并发的情况下,对于成员变量,可能是线程不安全的: 一个很简单的例子,假设我存在两个线程,让一个整数自增1000次,那么最终的值应该是1000:但是 ...
- CAS无锁算法与ConcurrentLinkedQueue
CAS:Compare and Swap 比较并交换 java.util.concurrent包完全建立在CAS之上的,没有CAS就没有并发包.并发包借助了CAS无锁算法实现了区别于synchroni ...
- (转载)java高并发:CAS无锁原理及广泛应用
java高并发:CAS无锁原理及广泛应用 版权声明:本文为博主原创文章,未经博主允许不得转载,转载请注明出处. 博主博客地址是 http://blog.csdn.net/liubenlong007 ...
- 无锁的同步策略——CAS操作详解
目录 1. 从乐观锁和悲观锁谈起 2. CAS详解 2.1 CAS指令 2.3 Java中的CAS指令 2.4 CAS结合失败重试机制进行并发控制 3. CAS操作的优势和劣势 3.1 CAS相比独占 ...
- CAS无锁技术
前言:关于同步,很多人都知道synchronized,Reentrantlock等加锁技术,这种方式也很好理解,是在线程访问的临界区资源上建立一个阻塞机制,需要线程等待 其它线程释放了锁,它才能运行. ...
- CAS无锁实现原理以及ABA问题
CAS(比较与交换,Compare and swap) 是一种有名的无锁算法.无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(N ...
- 探索CAS无锁技术
前言:关于同步,很多人都知道synchronized,Reentrantlock等加锁技术,这种方式也很好理解,是在线程访问的临界区资源上建立一个阻塞机制,需要线程等待 其它线程释放了锁,它才能运行. ...
- [数据库锁机制] 深入理解乐观锁、悲观锁以及CAS乐观锁的实现机制原理分析
前言: 在并发访问情况下,可能会出现脏读.不可重复读和幻读等读现象,为了应对这些问题,主流数据库都提供了锁机制,并引入了事务隔离级别的概念.数据库管理系统(DBMS)中的并发控制的任务是确保在多个事务 ...
随机推荐
- 将preg_replace()改写为preg_replace_callback()
preg_replace()函数使用/e修饰符可能带来安全隐患,PHP5.5之后,该用法被抛弃使用,升级为preg_replace_callback().在新版本下运行老版本的代码,会出现错误,如: ...
- poj 3159
差分约束 我也忘了谁说的了,反正我记得有人说过,只要是差分约束问题都可以转换成图 至少目前看来都是这样的 我一开始spfa+queue超时 看别人博客才知道要用spfa+stack,感觉智商又下降了一 ...
- [ 10.4 ]CF每日一题系列—— 486C
Description: 给你一个指针,可以左右移动,指向的小写字母可以,改变,但都是有花费的a - b 和 a - z花费1,指针移动也要花费,一个单位花费1,问你把当前字符串变成回文串的最小化费是 ...
- JS canvas 画板 撤销
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content ...
- Maven4-仓库
坐标和构建是一个构件在Maven世界中的逻辑表示方式,而其物理表示方式是文件.Maven通过仓库来统一管理这些文件 什么是Maven仓库? 在Maven世界中,任何一个依赖,插件或者项目构建的输出,都 ...
- 【转载】ARCHIVE_LAG_TARGET参数的作用(定时切换redo)
(一) 设置archive_lag_target参数1. 一旦设置了archive_lag_target初始化参数,数据库将会周期性的检查实例的当前重做日志.如果遇到下列情况,实例将会切换 ...
- Eclipse 使用前常用设置
1.常用设置的位置 Eclipse中一般的设置都是在这个位置进行设置的: 2.设置字体类型和大小 一般可以设置成这样代码比较清晰:Consolas + 常规 + 小四 3.设置各种编码 设置工作空间的 ...
- HTML一些有趣的东西
1.<head>标签里: <meta http-equiv="Refresh" content="3"/><!--三秒自动刷新-- ...
- 阿里启动新项目:Nacos,比 Eureka 更强!
什么是 Nacos? Nacos 是阿里巴巴推出来的一个新开源项目,这是一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平台. Nacos 致力于帮助您发现.配置和管理微服务.Nacos 提 ...
- python列表(list)的简单学习
列表是由一系列按特定顺序排列的元素组成, 是 Python 中使用最频繁的数据类型.列表可以完成大多数集合类的数据结构实现.列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表.字典(即嵌套 ...