Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
一.传统方式
这种方式就是常用的TableInputFormat和TableOutputFormat来读写hbase,如下代码所示
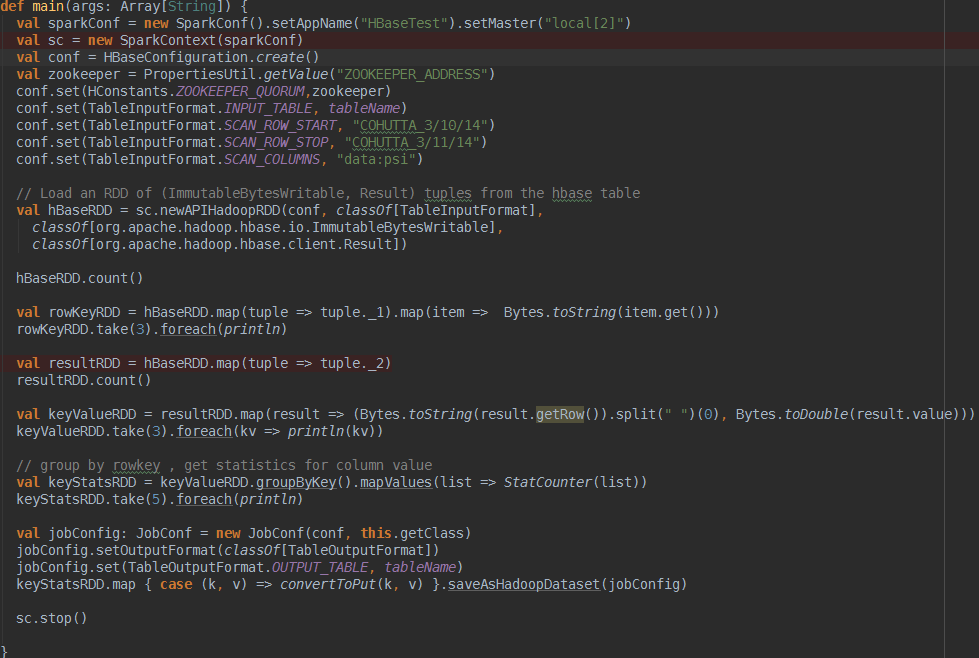
简单解释下,用sc.newAPIHadoopRDD根据conf中配置好的scan来从Hbase的数据列族中读取包含(ImmutableBytesWritable, Result)的RDD,
随后取出rowkey和value的键值对儿利用StatCounter进行一些最大最小值的计算最终写入hbase的统计列族.
二.SparkOnHbase方式
重点介绍第二种方式,这种方式其实是利用Cloudera-labs开源的一个HbaseContext的工具类来支持spark用RDD的方式批量读写hbase,先给个传送门大家感受下
https://issues.apache.org/jira/browse/HBASE-13992
https://issues.apache.org/jira/browse/HBASE-14160
虽然这个hbase-spark的module在Hbase上的集成任务很早就完成了,但是已知发布的任何版本我还没找到该模块,不知道什么情况,再等等吧
那么问题来了,这种方式的优势在哪儿呢,官方的解释我翻译如下
1>无缝的使用Hbase connection
2>和Kerberos无缝集成
3>通过get或者scan直接生成rdd
4>利用RDD支持hbase的任何组合操作
5>为通用操作提供简单的方法,同时通过API允许不受限制的未知高级操作
6>支持java和scala
7>为spark和 spark streaming提供相似的API
ok,由于hbaseContext是一个只依赖hadoop,hbase,spark的jar包的工具类,因此可以拿过来直接用
废话不说,直接用我调试过的代码来感受下
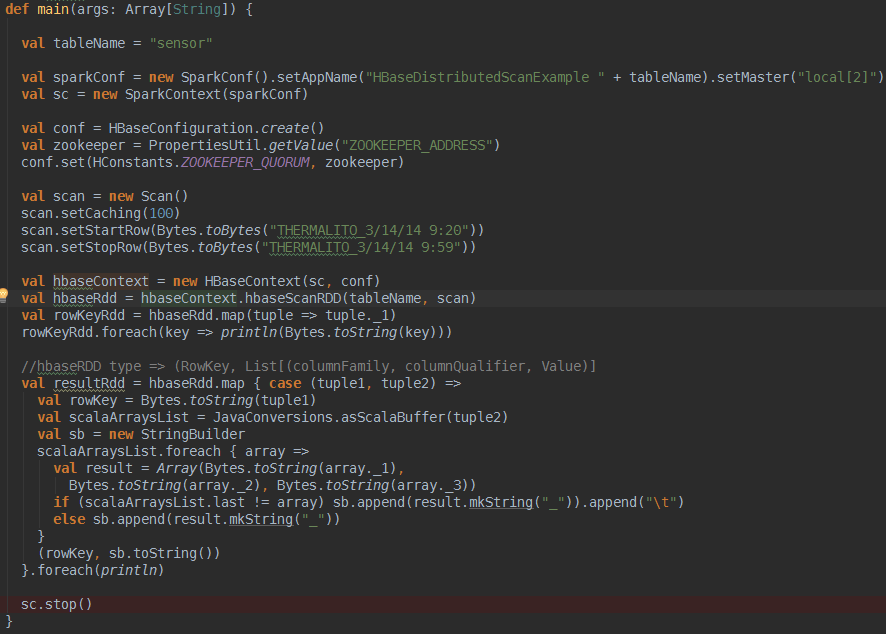
想用HbaseContext很简单,如上面代码所示,需要说明的是hbaseContext的hbaseScanRDD方法,这个方法返回的是一个
(RowKey, List[(columnFamily, columnQualifier, Value)]类型的RDD,如下
刚开始用的挺不习惯的.还得循环取出来rowkey对应的这么多列,这里你如果对它的RDD返回类型不爽,官方很贴心的提供了另外一个方法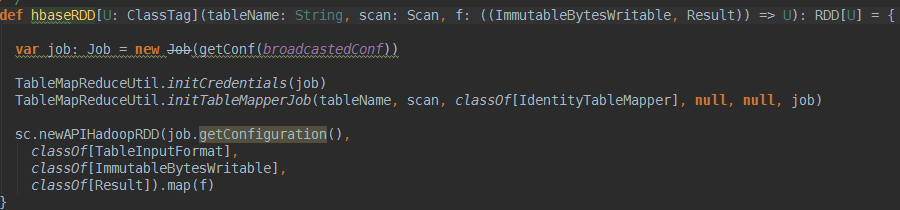
怎么样,是不是看着很眼熟了?你可以自定义第三个参数(ImmutableBytesWritable, Result),对函数f进行自定义来返回你自己喜欢的RDD格式,
程序运行结果如下,过滤出了9:20到9:58所有的rowkey以及对应的列

当然HbaseContext还有其他bulkGet,bulkPut,bulkDelete等,都是可以直接将hbase的操作转换成RDD,只要转成RDD了,那么rdd的这么多transform和action就可以玩的很happy了.
参考资料
https://github.com/cloudera-labs/SparkOnHBase
http://blog.cloudera.com/blog/2015/03/how-edmunds-com-used-spark-streaming-to-build-a-near-real-time-dashboard/
https://blog.cloudera.com/blog/2014/12/new-in-cloudera-labs-sparkonhbase/
Spark读写Hbase的二种方式对比的更多相关文章
- Spark入Hbase的四种方式效率对比
一.方式介绍 本次测试一种采用了四种方式进行了对比,分别是:1.在RDD内部调用java API.2.调用saveAsNewAPIHadoopDataset()接口.3.saveAsHadoopDat ...
- Spark:DataFrame批量导入Hbase的两种方式(HFile、Hive)
Spark处理后的结果数据resultDataFrame可以有多种存储介质,比较常见是存储为文件.关系型数据库,非关系行数据库. 各种方式有各自的特点,对于海量数据而言,如果想要达到实时查询的目的,使 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- Linux上删除大量文件几种方式对比
目录 Linux上删除大量文件几种方式对比 1. rm删除:因为文件数量太多,rm无法删除(报错) 2. find查找删除:-exec 3. find查找删除:xargs 4. find调用-dele ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- Android自动化测试中AccessibilityService获取控件信息(2)-三种方式对比
Android自动化测试中AccessibilityService获取控件信息(2)-三种方式对比 上一篇文章: Android自动化测试中AccessibilityService获取控件信息(1 ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Python读写文件的几种方式
一.pandas pandas模块是数据分析的大杀器,它使得对于文件相关的操作变得简单. 看一下它的简单使用 import pandas as pd # 读取 df = pd.read_csv('al ...
- spark DataFrame的创建几种方式和存储
一. 从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换.处理等功能.Sp ...
随机推荐
- wepack+sass+vue 入门教程(三)
十一.安装sass文件转换为css需要的相关依赖包 npm install --save-dev sass-loader style-loader css-loader loader的作用是辅助web ...
- [C#] 软硬结合第二篇——酷我音乐盒的逆天玩法
1.灵感来源: LZ是纯宅男,一天从早上8:00起一直要呆在电脑旁到晚上12:00左右吧~平时也没人来闲聊几句,刷空间暑假也没啥动态,听音乐吧...~有些确实不好听,于是就不得不打断手头的工作去点击下 ...
- nodejs之get/post请求的几种方式
最近一段时间在学习前端向服务器发送数据和请求数据,下面总结了一下向服务器发送请求用get和post的几种不同请求方式: 1.用form表单的方法:(1)get方法 前端代码: <form act ...
- 在Linux虚拟机下配置tomcat
1.到Apache官网下载tomcat http://tomcat.apache.org/download-80.cgi 博主我下载的是tomcat8 博主的jdk是1.8 如果你们的jdk是1.7或 ...
- LeetCode 7. Reverse Integer
Reverse digits of an integer. Example1: x = 123, return 321 Example2: x = -123, return -321 Have you ...
- 代码的坏味道(19)——狎昵关系(Inappropriate Intimacy)
坏味道--狎昵关系(Inappropriate Intimacy) 特征 一个类大量使用另一个类的内部字段和方法. 问题原因 类和类之间应该尽量少的感知彼此(减少耦合).这样的类更容易维护和复用. 解 ...
- ASP.NET MVC——模型绑定
这篇文章我们来讲讲模型绑定(Model Binding),其实在初步了解ASP.NET MVC之后,大家可能都会产生一个疑问,为什么URL片段最后会转换为例如int型或者其他类型的参数呢?这里就不得不 ...
- Linux命令【第二篇】
1.如何过滤出已知当前目录下oldboy中的所有一级目录(提示:不包含oldboy目录下面目录的子目录及隐藏目录,即只能是一级目录). ^:以什么开头,例如^olboy表示以oldboy开头. ls: ...
- 最近在玩linux时 yum 遇到了问题
主要是软件源出现了问题 我做的方式可能比较粗暴 ls -l /etc/yum.repos.d/ /*查看软件源*/ rm -rf /etc/yum.repos.d/ /*全删了*/ m ...
- [转]nopCommerce Widgets and How to Create One
本文转自:https://dzone.com/articles/what-are-nopcommerce-widgets-and-how-to-create-one A widget is a sta ...