利用HtmlAgilityPack库进行HTML数据抓取
主要介绍基于XPATH的文本分析方式的实现,代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; using HtmlAgilityPack;
namespace MyIdea.Spider
{
class Program
{
static void Main(string[] args)
{
GetDataFromFile();
GetDataFromUrl();
Console.ReadKey();
} static void GetDataFromFile()
{
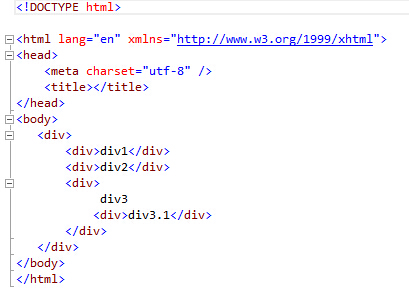
HtmlDocument doc = new HtmlDocument();
doc.Load(AppDomain.CurrentDomain.BaseDirectory.Replace(@"bin\Debug","") + "/test.html");
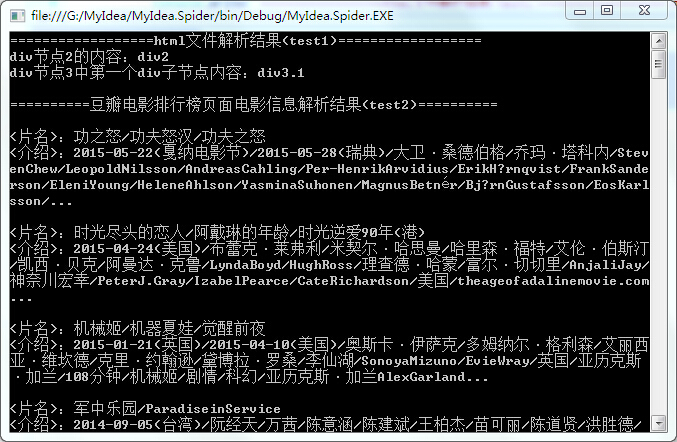
Console.Write("==================html文件解析结果(test1)==================\n");
Console.Write(string.Format("div节点2的内容:{0}\n", doc.DocumentNode.SelectNodes("/html/body/div/div")[].InnerText));
Console.Write(string.Format("div节点3中第一个div子节点内容:{0}\n\n", doc.DocumentNode.SelectNodes("/html/body/div/div/div")[].InnerText));
} static void GetDataFromUrl()
{
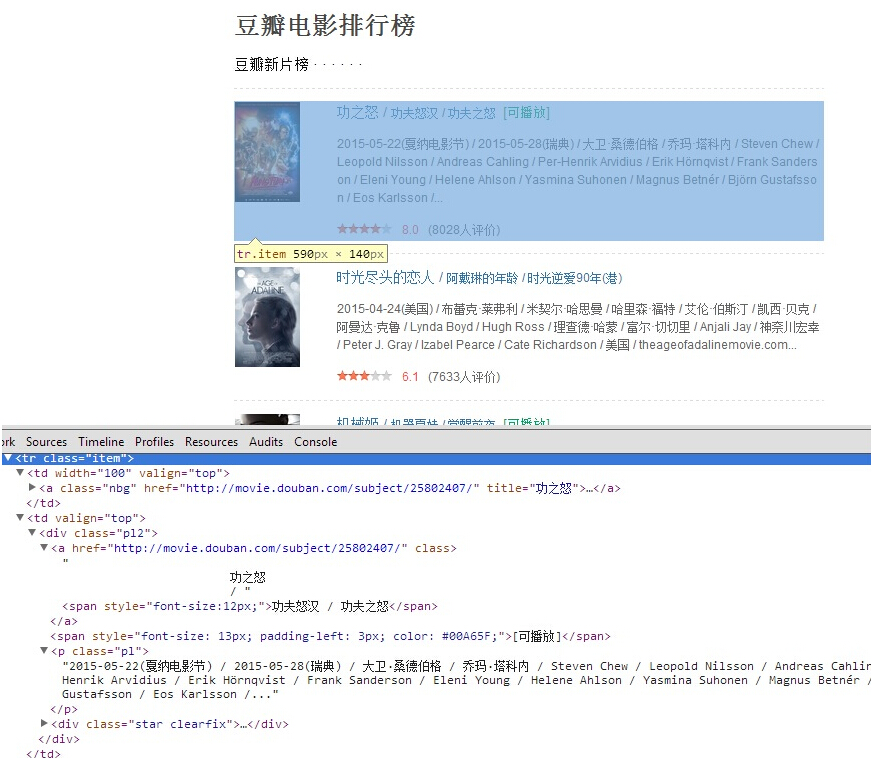
string url = "http://movie.douban.com/chart";
string movieXpath = "/html/body/div[3]/div[1]/div/div[1]/div/div/table/tr/td[2]/div";
HtmlWeb request = new HtmlWeb();
HtmlDocument doc = request.Load(url); HtmlNodeCollection movieItems = doc.DocumentNode.SelectNodes(movieXpath);
Console.Write("==========豆瓣电影排行榜页面电影信息解析结果(test2)==========\n");
foreach (HtmlNode item in movieItems)
{
string title = item.Descendants("a").First().InnerText.Replace(" ","").Replace("\n","");
string introduce = item.Descendants("p").First().InnerText.Replace(" ", "").Replace("\n", "");
Console.WriteLine("\n<片名>:"+title);
Console.WriteLine("<介绍>:" + introduce);
}
}
}
}
解析结果
利用HtmlAgilityPack库进行HTML数据抓取的更多相关文章
- 利用HtmlAgilityPack插件写的一个抓取指定网页的图片 第一次写 很乱 随便看看就行
public partial class Form1 : Form { /// <summary> /// 存放图片地址 /// </summary> List<stri ...
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- 利用python脚本(xpath)抓取数据
有人会问re和xpath是什么关系?如果你了解js与jquery,那么这个就很好理解了. 上一篇:利用python脚本(re)抓取美空mm图片 # -*- coding:utf-8 -*- from ...
- Python数据抓取_BeautifulSoup模块的使用
在数据抓取的过程中,我们往往都需要对数据进行处理 本篇文章我们主要来介绍python的HTML和XML的分析库 BeautifulSoup 的官方文档网站如下 https://www.crummy.c ...
- 大数据抓取采集框架(摘抄至http://blog.jobbole.com/46673/)
摘抄至http://blog.jobbole.com/46673/ 随着BIG DATA大数据概念逐渐升温,如何搭建一个能够采集海量数据的架构体系摆在大家眼前.如何能够做到所见即所得的无阻拦式采集.如 ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- 数据抓取的艺术(三):抓取Google数据之心得
本来是想把这部分内容放到前一篇<数据抓取的艺术(二):数据抓取程序优化>之中.但是随着任务的完成,我越来越感觉到其中深深的趣味,现总结如下: (1)时间 时间是一个与抓取规模相形而 ...
随机推荐
- get_object_vars($var) vs array($var)
get_object_vars(\(var) vs array(\)var) test case class Test { public function actionGetObjectVarsVsA ...
- tomcat集群实例重复执行
http://www.cnblogs.com/interdrp/p/3458882.html
- C#方法中三个重要的参数:out、ref、params
备注:适用于初学者,自学于传智播客. 1.out参数. 概念:如果在一个方法中,返回多个相同类型值的时候,可以考虑返回一数组.但是返回多个不同类型值的时候,返回数组显然不能解决问题,这时就引入out参 ...
- python脚本执行Scapy出现IPv6警告WARNING解决办法
安装完scapy,写了脚本执行后执行: WARNING: No route found for IPv6 destination :: (no default route?) 原因是用 from sc ...
- 《Photon》
搭建客户端: using UnityEngine;using System.Collections;using ExitGames.Client.Photon; public class GameCl ...
- 【洛谷P3385】模板-负环
这道题普通的bfs spfa或者ballen ford会T 所以我们使用dfs spfa 原因在于,bfs sfpa中每个节点的入队次数不定,退出操作不及时,而dfs则不会 既然,我们需要找负环,那么 ...
- RestSharp简单扩展
using RestSharp; using RestSharp.Deserializers; using RestSharp.Serializers; using System; using Sys ...
- Java程序,求学员的平均成绩
第一步,系统提示输入学员的人数. 第二步,逐一获取学员的分数,并累计. 第三步,求平均成绩,并输出. import java.util.Scanner; public class chengji { ...
- 【Android UI】Android Layout XML属性
Layout对于迅速的搭建界面和提高界面在不同分辨率的屏幕上的适应性具有很大的作用.这里简要介绍Android的Layout和研究一下它的实现. Android有Layout:FrameLayout, ...
- 轻松创建R语言函数包
讲真,用R这么几年,始终未尝试过写自己的包,看来这就是我与真正程序员的差距了——编程习惯等于没有. 昨天一个偶然的机会想开始写自己的工具包,发现了前期教程的有一些过时.于是,写一个**windows* ...