用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件
#coding=utf-8
from selenium import webdriver
import unittest
from time import sleep class DoubanMovie(unittest.TestCase): def setUp(self):
self.dr = webdriver.Chrome()
self.top_movie_list = self.get_douban_movies_top12()
self.movie = self.get_movie_top12_file() def get_douban_movies_top12(self):
'''获取豆瓣电影成都地区正在上映的前12部电影名字及评分'''
self.dr.get("https://movie.douban.com/nowplaying/chengdu/")
sleep(3)
movie_list = []#定义空list为后面存放电影名字和电影评分作准备
i = 0
while i < 60: #12*5=60
movie_name = self.dr.find_elements_by_css_selector('.lists li')[i].get_attribute('data-title')#定位电影名字
movie_grand = self.dr.find_elements_by_css_selector('.lists li')[i].get_attribute('data-score')#定位电影评分
movie_list.append([movie_name,movie_grand])#向空list追加插入获取的电影名字和电影评分
i += 5 #每个电影的li标签间隔为5个
movie_list.sort(key=lambda x:x[1], reverse=True)#利用sort中key方法来根据电影评分高到低对所获取的电影进行排序(movie_list = sorted(movie_list, key=lambda movie: movic[1], reverse=True) # sort by movie_grand 倒序)
return movie_list def get_movie_top12_file(self):
self.file_title = '豆瓣电影成都地区正在上映的前12部电影'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.top_movie_list:
self.file.write(('电影名字:' + item[0] + ' ' + '电影评分:' + item[1] + '\n').encode('utf-8'))
self.file.close() def test_movie(self):
pass
print("获取完毕") def tearDown(self):
self.dr.quit() if __name__ == '__main__':
unittest.main()

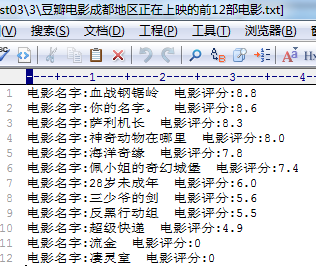
注:电影中暂无评分记为0分。
用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序的更多相关文章
- 用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评 方法一: #coding=utf-8 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- 用python+selenium抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答并保存至html文件
抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答,保存至html文件,该html文件的文件名应该是20160228_zhihu_today_hot.html,也就是日期+zhihu_toda ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- 前端工程师IE6兼容性问题随笔(未完待续)
1 height.在IE6下元素高度小于19px的时候,会被当做19px来处理.解决办法:用overflow:hidden;来处理.box{height:2px;background:red;over ...
- 使用AjaxPro实现无刷新更新数据
需求 在一个页面动态无刷新的更新后台得到的数据.要想无刷新的更新数据,需要使用Javascript能够获取后台返回的数据,然后通过第三方Javascript库(JQuery等)动态更新web页面DOM ...
- http调接口
private static String doGetResult(String urlStr, Map<String, String> params) throws Exception ...
- D2.Reactjs 操作事件、状态改变、路由
下面内容代码使用ES6语法 一.组件的操作事件: 1.先要在组件类定义内定义操作事件的方法,如同event handler.若我需要监听在组件内的Button的点击事件onClick,首先定义监听方法 ...
- C++小项目:directx11图形程序(四):d3dclass
主菜终于来了.这个d3dclass主要做的工作是dx11图形程序的初始化工作,它将创建显示表面交换链,d3d设备,d3d设备上下文,渲染目标表面,深度模板缓存:设置视口,生成投影矩阵. D3D设备:可 ...
- MicroERP数据初始化SQL脚本
--use MicroERP insert into tbUserGroup(GroupName,Remark) values('管理员组','具备所有权限')insert into tbUser(L ...
- Java特性-Collection和Map
创建博客的目的主要帮助自己记忆和复习日常学到和用到的知识:或有纰漏请大家斧正,非常感谢! 之前面试,被问过一个问题:List和Set的区别. 主要区别很明显了,两者都是数组形式存在的,继承了Colle ...
- Ajax读取txt并对txt内容进行分页显示
function TransferString(content) { var string = content; try{ string=string.replace(/\r\n/g,"&l ...
- 使用JavaScript实现复选框全选与取消的功能
实现效果: html代码: <body> <input type="checkbox" id="checkAll"/>全选<br& ...
- web.config设置和取值
博客园中有一篇文章对web.config的结构做了很详细的介绍,原文见 http://www.cnblogs.com/gaoweipeng/archive/2009/05/17/1458762.htm ...