用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序
抓取豆瓣电影(http://movie.douban.com/nowplaying/chengdu/)中的正在热映前12部电影,并按照评分排序,保存至txt文件
#coding=utf-8
from selenium import webdriver
import unittest
from time import sleep class DoubanMovie(unittest.TestCase): def setUp(self):
self.dr = webdriver.Chrome()
self.top_movie_list = self.get_douban_movies_top12()
self.movie = self.get_movie_top12_file() def get_douban_movies_top12(self):
'''获取豆瓣电影成都地区正在上映的前12部电影名字及评分'''
self.dr.get("https://movie.douban.com/nowplaying/chengdu/")
sleep(3)
movie_list = []#定义空list为后面存放电影名字和电影评分作准备
i = 0
while i < 60: #12*5=60
movie_name = self.dr.find_elements_by_css_selector('.lists li')[i].get_attribute('data-title')#定位电影名字
movie_grand = self.dr.find_elements_by_css_selector('.lists li')[i].get_attribute('data-score')#定位电影评分
movie_list.append([movie_name,movie_grand])#向空list追加插入获取的电影名字和电影评分
i += 5 #每个电影的li标签间隔为5个
movie_list.sort(key=lambda x:x[1], reverse=True)#利用sort中key方法来根据电影评分高到低对所获取的电影进行排序(movie_list = sorted(movie_list, key=lambda movie: movic[1], reverse=True) # sort by movie_grand 倒序)
return movie_list def get_movie_top12_file(self):
self.file_title = '豆瓣电影成都地区正在上映的前12部电影'
self.file = open(self.file_title + '.txt', 'wb')
for item in self.top_movie_list:
self.file.write(('电影名字:' + item[0] + ' ' + '电影评分:' + item[1] + '\n').encode('utf-8'))
self.file.close() def test_movie(self):
pass
print("获取完毕") def tearDown(self):
self.dr.quit() if __name__ == '__main__':
unittest.main()

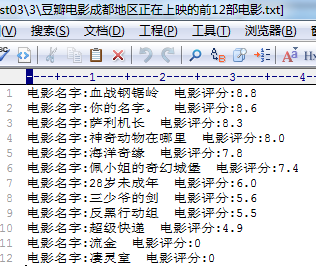
注:电影中暂无评分记为0分。
用python+selenium抓取豆瓣电影中的正在热映前12部电影并按评分排序的更多相关文章
- 用python+selenium抓取豆瓣读书中最受关注图书并按评分排序
抓取豆瓣读书中的(http://book.douban.com/)最受关注图书,按照评分排序,并保存至txt文件中,需要抓取书籍的名称,作者,评分,体裁和一句话评 方法一: #coding=utf-8 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- 用python+selenium抓取微博24小时热门话题的前15个并保存到txt中
抓取微博24小时热门话题的前15个,抓取的内容请保存至txt文件中,需要抓取排行.话题和阅读数 #coding=utf-8 from selenium import webdriver import ...
- python爬虫抓取豆瓣电影
抓取电影名称以及评分,并排序(代码丑炸) import urllib import re from bs4 import BeautifulSoup def get(p): t=0 k=1 n=1 b ...
- 用python+selenium抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答并保存至html文件
抓取知乎今日最热和本月最热的前三个问题及每个问题的首个回答,保存至html文件,该html文件的文件名应该是20160228_zhihu_today_hot.html,也就是日期+zhihu_toda ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
随机推荐
- 作业调度框架 Quartz 学习笔记(三) -- Cron表达式 (转载)
前面两篇说的是简单的触发器(SimpleTrigger) , SimpleTrigger 只能处理简单的事件出发,如果想灵活的进行任务的触发,就要请出 CronTrigger 这个重要人物了. Cro ...
- 荣品四核4412开发板的USB摄像头问题
RP4412开发板是荣品电子研发的一款三星四核Exynos4412评估板开发板,支持WIFI+LAN上网.蓝牙4.0.4G上网.500万自动对焦摄像头.GPS.网卡.音频,1080P HDMI音视频同 ...
- [转载]什么是FCKeditor?功能强大的HTML编辑器!
天天在用FCKeditor写博客,但一直不清楚FCKeditor到底是什么,今天终于找到了一些相关的资料,大家一起来分享下. FCKeditor文本编辑程序(共享软件)为用户提供在线的文档编辑服务,其 ...
- 4种必须知道的Android屏幕自适应解决方案
文章来源:http://blog.csdn.net/shimiso/article/details/19166167 demo下载:http://www.eoeandroid.com/forum.ph ...
- CSS-position详解
position属性 position属性可以调整DOM元素在浏览器中的位置,能够很好的体现HTML普通流这个特征.重点在于应用了不同的position值之后是否有脱离普通流和改变Display属性这 ...
- jquery mobile 输入框无边框
现在移动开发为主流的时代,少不了使用jquery mobile.但是偶然应项目要求需要把input输入框做成无边框的,不是特别容易的事,网上找了很多都没有一种靠谱的解决方案,只能自食其力了. < ...
- HTML5和CSS3的一些新特性
html5有哪些新特性.移除了那些元素?如何处理HTML5新标签的浏览器兼容问题?如何区分 HTML 和 HTML5? 新特性: 1. 拖拽释放(Drag and drop) 2. 语义化更好的内容标 ...
- Command Pattern
当(客户)对象访问(服务)请求服务时,最直接的方法就是方法调用.
- PHP 语法
不过在 PHP 中,所有变量都对大小写敏感. 在下面的例子中,只有第一条语句会显示 $color 变量的值(这是因为 $color.$COLOR 以及 $coLOR 被视作三个不同的变量): 实例 & ...
- Mac上安装与更新Ruby,Rails运行环境
Mac安装后就安装Xcode是个好主意,它将帮你安装好Unix环境需要的开发包,也可以独立安装command_line_tools_for_xcode 1.安装RVM RVM:Ruby Version ...