EM算法(2):GMM训练算法
目录
EM算法(2):GMM训练算法
1. 简介
GMM模型全称为Gaussian Mixture Model,即高斯混合模型。其主要是针对普通的单个高斯模型提出来的。我们知道,普通高斯模型对实际数据拟合效果还不错,但是其有一个致命的缺陷,就是其为单峰函数,如果数据的真实分布为复杂的多峰分布,那么单峰高斯的拟合效果就不够好了。
与单峰高斯模型不同,GMM模型是多个高斯模型的加权和,具体一点就是:
$p(\mathbf{x})\ =\ \sum_k\pi_k\mathcal{N}(\mathbf{x}|\mu_k,\Sigma_k)$
这是一个多峰分布,理论上,只要k足够大,GMM模型能拟合任何分布。
2. 困难
GMM模型比普通高斯模型拟合能力更强了,但是对其训练的难度也增加了。回忆一下,在训练普通高斯模型时,我们是对其分布函数去ln进行求导,具体一点就是:
$\frac{\partial lnp(\mathbf{x})}{\partial \mathbf{\theta}}\ =\ 0$
那么对于普通高斯函数来说,$lnp(\mathbf{x}) = C - \frac{1}{2}(\mathbf{x}-\mu)^T\Sigma^{-1}(\mathbf{x}-\mu)$,可以看到,ln将分布函数中的指数形式消除了,那么对其求导很容易得到闭式解。但是对于GMM模型来说就不是这么简单了。我们可以计算一下,其概率函数取ln形式为:
$lnp(\mathbf{x}) = ln\{ \sum_k\pi_k\mathcal{N}(\mathbf{x}|\mu_k,\Sigma_k)\}$
我们可以看到,因为在ln里面还有加法,所以其无法消除其中的指数形式,导致其最优化问题没有闭式解。所以想要用calculus的方式来解决GMM模型训练的问题是不行的。
3. Inspiration from k-means algorithm
没有什么事情是一步解决不了的,如果有,那就用两步。
--沃 · 兹基硕德
我们重新来看看GMM模型的表达式,其由多个高斯函数相加而成,你可以想想一个空间中有很多高斯函数,它们分别在各自中心点所在的位置。一个一维的三个高斯混合的模型示意如下:
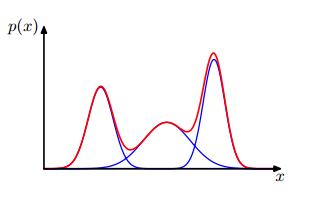
那么对于任何一个点,都有其最靠近的一个峰。比如在中间峰处的点,其概率几乎全是来自于第二个高斯分布。那么我们就可以这样想,是不是每个点都有其更加偏向的高斯峰呢?等等,这个想法好像在哪里见过?k-means算法中的第一步不就是干的这事吗?将每个点都分配给最近的一个类。但是,我们这里怎么去度量距离呢?继续使用点到中心的距离?这样好像把每个高斯的方差忽略掉了。那么既然是概率模型,最好的方法就是用概率来比较。对于一个点$\mathbf{x}$,第k个高斯对其的贡献为$\pi_k\mathcal{N}(\mathbf{x}|\mu_k,\Sigma_k)$,那么把$\mathbf{x}$分配给贡献最大的一个,这样看起来把各个因素考虑进去,似乎很合理了。
但是,我们发现,如果一个点处于两个峰之间呢,这样把其归为任何一个峰都不太好吧?当然,k-means也没有解决这个问题,但是我们这里是概率模型,我们有更好的描述方法,我们可以计算一个点$\mathbf{x}$属于每个高斯的概率。这样的考虑就比较全面了。那么点$\mathbf{x}$属于每个高斯的概率自然就取这个高斯对其的贡献$\pi_k\mathcal{N}(\mathbf{x}|\mu_k,\Sigma_k)$。为了使其成为一个概率,我们还需要对其归一化,所以得到第n个数据点属于第k个高斯的概率:
$\gamma_{nk}=\frac{\pi_k\mathcal{N}(\mathbf{x}_n|\mu_k,\Sigma_k)}{\sum_j\pi_j\mathcal{N}(\mathbf{x}_n|\mu_j,\Sigma_j)}$
按照k-means算法,第二步就是把$\gamma_{nk}$当做已知去做最优化。这里既然是要拟合分布,那么就使用最大似然的方法,最大化$lnp(\mathbf{X})$。那么这里就有一个问题了:在k-means算法中,目标函数是有$r_{nk}$这一项的,然而$lnp(\mathbf{X})$中并没有$\gamma_{nk}$这一项呀,我怎么把其当做已知的呢?这里我们不急,暂时不去管这个,我们先计算$\frac{\partial lnp(\mathbf{X})}{\partial \mu_k}$:
$\frac{\partial lnp(\mathbf{X})}{\partial \mu_k}\ =\ -\ \sum_n\frac{\pi_k\mathcal{N}(\mathbf{x}_n|\mu_k,\Sigma_k)}{\sum_j\pi_j\mathcal{N}(\mathbf{x}_n|\mu_j,\Sigma_k)}\Sigma_k(\mathbf{x}_n\ -\ \mu_k) $ (1)
我们的$\gamma_{nk}$是不是已经出现了,那么上式可以简写为:
$\ -\ \sum_n\gamma_{nk}\Sigma_k(\mathbf{x}_n\ -\ \mu_k)$
令其等于0,可以得到:
$\mu_k\ =\ \frac{\sum_n\gamma_{nk}\mathbf{x}_n}{\sum_n\gamma_{nk}}$ (2)
可以看到,其与k-means算法第二步中心点的计算方法$\mu_k=\frac{\sum_nr_{nk}\mathbf{x}_n}{\sum_nr_{nk}}$非常相似。
类似的,对$\Sigma_k$求导,可以得到:
$\Sigma_k\ =\ \frac{\sum_n\gamma_{nk}(\mathbf{x}_n-\mu_k)(\mathbf{x}_n-\mu_k)^T}{\sum_n\gamma_{nk}}$ (3)
对$\pi_k$求导,可以得到:
$\pi_k\ =\ \frac{\sum_n\gamma_{nk}}{\sum_k\sum_n\gamma_{nk}}$ (4)
自此,GMM训练方法就得到了,第一步,使用式(1)计算所有点的属于各个高斯的概率;第二步,利用式(2),(3),(4)更新均值、方差和权值。重复这两步直到收敛。
4. 与EM算法的关系
这里我们是从k-means算法出发得到的GMM训练算法,那么其与EM算法的关系与k-means算法和EM算法的关系类似。同样,我们后面可以看到,利用EM算法可以推导出GMM训练算法。
EM算法(2):GMM训练算法的更多相关文章
- 传统神经网络ANN训练算法总结
传统神经网络ANN训练算法总结 学习/训练算法分类 神经网络类型的不同,对应了不同类型的训练/学习算法.因而根据神经网络的分类,总结起来,传统神经网络的学习算法也可以主要分为以下三类: 1)前馈型神经 ...
- MATLAB中“fitgmdist”的用法及其GMM聚类算法
MATLAB中“fitgmdist”的用法及其GMM聚类算法 作者:凯鲁嘎吉 - 博客园http://www.cnblogs.com/kailugaji/ 高斯混合模型的基本原理:聚类——GMM,MA ...
- EM(期望最大化)算法初步认识
不多说,直接上干货! 机器学习十大算法之一:EM算法(即期望最大化算法).能评得上十大之一,让人听起来觉得挺NB的.什么是NB啊,我们一般说某个人很NB,是因为他能解决一些别人解决不了的问题.神为什么 ...
- 受限玻尔兹曼机(RBM)学习笔记(七)RBM 训练算法
去年 6 月份写的博文<Yusuke Sugomori 的 C 语言 Deep Learning 程序解读>是囫囵吞枣地读完一个关于 DBN 算法的开源代码后的笔记,当时对其中涉及的算 ...
- 【原创】batch-GD, SGD, Mini-batch-GD, Stochastic GD, Online-GD -- 大数据背景下的梯度训练算法
机器学习中梯度下降(Gradient Descent, GD)算法只需要计算损失函数的一阶导数,计算代价小,非常适合训练数据非常大的应用. 梯度下降法的物理意义很好理解,就是沿着当前点的梯度方向进行线 ...
- 目标检测算法SSD之训练自己的数据集
目标检测算法SSD之训练自己的数据集 prerequesties 预备知识/前提条件 下载和配置了最新SSD代码 git clone https://github.com/weiliu89/caffe ...
- 物体检测算法 SSD 的训练和测试
物体检测算法 SSD 的训练和测试 GitHub:https://github.com/stoneyang/caffe_ssd Paper: https://arxiv.org/abs/1512.02 ...
- <转>与EM相关的两个算法-K-mean算法以及混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- EM(Expectation Maximization)算法
EM(Expectation Maximization)算法 参考资料: [1]. 从最大似然到EM算法浅解 [2]. 简单的EM算法例子 [3]. EM算法)The EM Algorithm(详尽 ...
随机推荐
- [转]编译安装libevent,memcache,以及php的memcached扩展
一 安装libevent 1.去官网http://libevent.org/ 下载最新源码,我用的是libevent-2.0.20-stable.tar.gz 2.解压到/usr/src目录 ,执行命 ...
- oracle如何写包
一:如何使用FOR循环二:如何使用拼接语句 EXECUTE IMMEDIATE v_sql INTO v_WORK_ORDERID;三:如何定义记录类型做为变量,用于存储及查询 CREATE OR R ...
- SQL:实现流水账的收入、支出、本期余额
有多组数据,分别是收入,支出,余额,它们的关系是:本期余额=上次余额+收入-支出 /* 测试数据: Create Table tbl([日期] smalldatetime,[收入] int ,[支出] ...
- 影响性能的关键部分-ceph的osd journal写
在前面一篇文章中,我们看到,当使用filestore时,osd会把磁盘分成data和journal两部分.这主要是为了支持object的transaction操作.我的想法是,ceph需要具有数据保护 ...
- MySQL服务 - MySQL 5.5编译安装
cmake介绍: MySQL 5.5之后,所有的编译操作都通过cmake进行,使用cmake最大的好处是其独立于源码(out-of-source)的编译功能,即编译工作可以在另一个指定的目录中而非源码 ...
- Bower 自定义组件文件夹名称
默认情况下, bower 会自动把文件安装在文件夹 bower_components 下面,如果希望自定义这个文件夹的名称为 components ,可以创建一个名称为 ".bowerrc& ...
- 在vue1.0遇到vuex和v-model的坑
事情是这样的,在开发项目的过程中我使用了vuex并且在store中定义了一个保存用户信息的对象 userInfo : { 'nickName' : '', // 昵称 'password' :'', ...
- 一行代码解决各种IE兼容问题,IE6,IE7,IE8,IE9,IE10 http://www.jb51.net/css/383986.html
在网站开发中不免因为各种兼容问题苦恼,针对兼容问题,其实IE给出了解决方案Google也给出了解决方案百度也应用了这种方案去解决IE的兼容问题 百度源代码如下 复制代码 代码如下: <!Do ...
- PHP取整函数:ceil,floor,round,intval的区别详细解析
floor -- 舍去法取整说明float floor ( float value ) 返回不大于 value 的下一个整数,将 value 的小数部分舍去取整.floor() 返回的类型仍然是 fl ...
- jQuery的编码标准和最佳实践
不知道在哪里看到了这篇关于jQuery编码的文章,挺实用的,恰好最近在研究jQuery的基础知识,今天打开收藏夹来翻译一下,原文的英语不难,但是内容很实用,可能有大神已经翻译过了,大家看精华就行了. ...