vLLM框架:LLM推理的高效机制
vLLM框架:大语言模型推理的高效机制
vLLM(Virtual Large Language Model)是由加州大学伯克利分校团队开发的高性能大模型推理框架,通过创新的显存管理和调度策略,解决了传统推理框架在部署大模型时面临的显存利用率低、吞吐量不足、并发处理效率低等问题。vLLM的核心优势在于其独特的PagedAttention显存管理机制和连续批处理技术,这两项创新使显存利用率提升至接近100%,吞吐量可达传统框架的24倍[1],特别适合高并发、低延迟的实时推理场景。
vLLM采用分层架构设计,将系统分为控制面和执行面,类似于操作系统的设计理念。控制面负责请求调度、显存管理和资源分配,执行面则专注于模型计算和推理任务的执行。这种分离设计使得系统能够高效地处理多任务调度和资源优化问题。
在控制面,vLLM实现了基于token的调度器,能够动态调整batch大小,实时合并多个推理请求。执行面则包含Worker模块,负责模型计算(前向传播)、KV Cache的分页存储与访问、采样策略执行等核心任务。整个架构的核心设计理念是最大化GPU资源利用率,减少显存浪费,提升推理吞吐量,同时保持对主流模型和API的兼容性。
vLLM的推理流程分为两个主要阶段:prefill阶段和decode阶段。prefill阶段处理输入提示词,生成初始的KV Cache;decode阶段则逐个生成输出token,持续更新KV Cache。整个过程中,vLLM通过其PagedAttention机制和Continues Batching技术,实现了对显存资源的高效利用和对计算资源的充分调度。
1. PagedAttention显存管理机制
PagedAttention是vLLM最核心的创新技术,它借鉴了操作系统的虚拟内存分页机制,将注意力计算中的Key/Value缓存(KV Cache)划分为固定大小的"页",动态分配显存,显著减少内存碎片化,使显存利用率提升至96%以上[2]。
PagedAttention的思想来源于操作系统的内存分页(Paging)。内存分页将虚拟地址空间划分为固定大小的“页”,将物理内存划分为同样大小的页框(page frame),并按需把虚拟页映射到物理page frames。在管理与分配page frames时,通过将不活跃的内存page换出,实现高效的内存使用。PagedAttention将这一思想迁移到LLM Serving的场景,优化内存分配方式,减少了浪费。
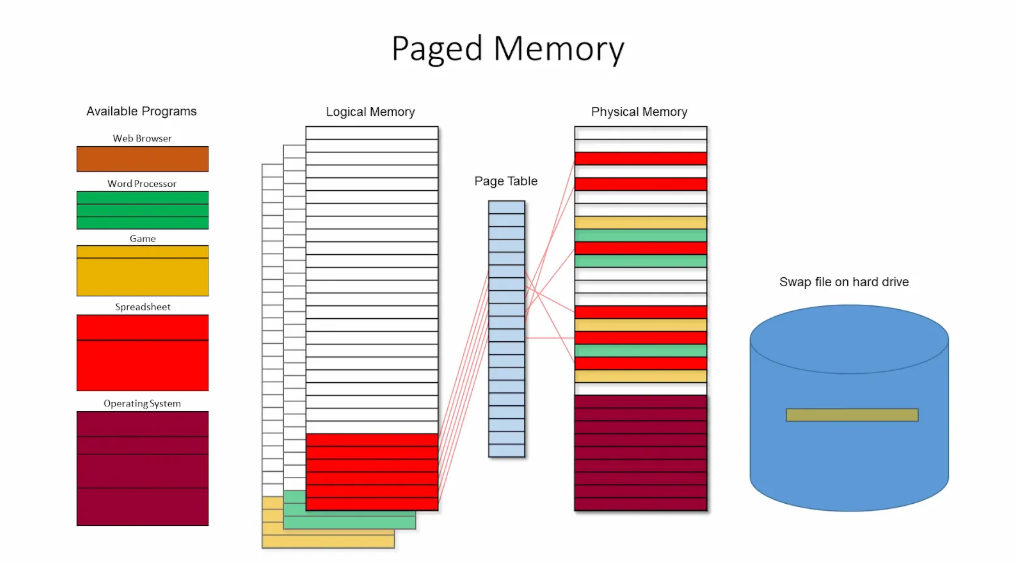
Paged Memory System[2]
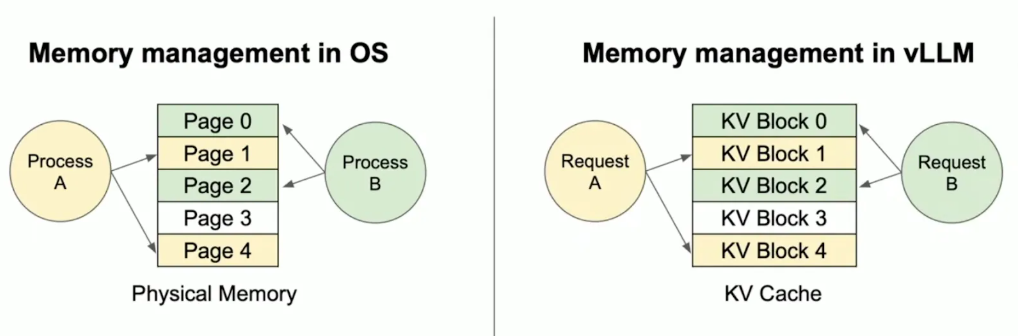
PagedAttention将KV Cache划分为固定大小的物理页,每个物理页存储一定数量token的KV向量(如4或3个token)。与传统框架需要为每个请求预留连续显存空间不同,vLLM允许不同请求的KV Cache分布在非连续的物理页中,通过逻辑块与物理块的映射表实现高效访问。
在prefill阶段,vLLM仅分配必要的物理页,而非预先为整个序列预留最大长度空间。例如,一个7 token的输入会被分配到两个物理页(前4 token和后3 token)。这种按需分配的策略避免了传统方法中大量未使用的预留空间,将显存浪费限制在单页内,显著提高了显存利用率。
在生成阶段(decode阶段),PagedAttention算法通过物理页索引计算当前token与所有历史token的注意力。虽然KV Cache分布在多个非连续物理页中,但通过页表映射,模型仍能访问完整的上下文信息。这种机制保证了自注意力的连续性,同时避免了显存碎片化问题。具体来说,当计算新token的注意力时,模型会遍历该请求所有逻辑块对应的物理页,获取所有历史token的KV向量。这种设计使得不同长度的序列可以共享显存页,提高了显存的利用率和灵活性。
当GPU显存不足时,vLLM会采用类似操作系统页面置换的机制,将部分KV Cache页交换到CPU内存中。这种Swap机制允许系统在显存紧张时,主动牺牲某些victim sequence的KV Cache,腾出空间供其他序列继续生成。当这些被交换的序列需要继续生成时,再将其KV Cache从CPU内存取回。对于这个场景,这篇文章[3]举了一个很好的例子进行参考。
这种分页机制的优势在于:
- 显存利用率接近100%,减少了60%-80%的显存浪费
- 支持长上下文(如128K或10M token)的高效处理
- 兼容INT4量化等技术,进一步降低显存占用
2. 请求调度与Continues Batching
Continues Batching是vLLM的另一项关键技术,它打破了传统框架"一次推理一个batch直到结束"的模式,以token为最小调度单位,动态合并多个请求的批处理任务,避免GPU空闲等待,提高利用率。
在介绍Continues batching之前,我们先了解一下vLLM服务器执行的一个基本步骤engine_step。vLLM的服务在处理请求时会调用一个叫EngineCoreProc的进程,这个进程会维护一个请求队列并处理请求。在处理请求部分,使用的是一个while循环,伪代码如下所示:
while True:
if not has_request_in_queue():
wait_for_new_request()
engine_step()
可以看到,如果请求队列里有请求的话,就执行engine_step。一个step有两种可能:prefill或decode(生成一个新token)。目前主流大模型基本是Decoder-Only的模型架构,所以在生成某个序列的下一个token时,必须要先计算出这个序列所有的顺序token(例如输入的prompt)的Key和Value,这个阶段就是prefill的阶段,这个阶段由于要连续计算多个token的Q、K、V向量(Query、Key和Value向量),所以是计算密集型的任务。在prefill阶段结束后,开始进行decode阶段,也就是生成序列的下一个token,此时需要之前所有token得Key和Value向量,计算下一个token的Q、K、V向量。目前推理引擎基本都会利用KV Cache的方式将前面的K、V向量进行缓存,避免重复计算,以此提升生成速度。所以在decode阶段主要是高GPU内存缓存需求(访存密集型)的场景,而非计算密集型场景。基于这个基础,目前LLM推理框架例如vLLM和SGLang都推出了对应的prefill-decode分离的功能,主要考虑到prefill和decode对硬件资源的诉求不同,因此将其分离在不同的设备上进行推理,以进一步提升系统的吞吐。
再回到engine_step的运行,在每一个engine_step开始的时候,scheduler组件会决定这个step做什么。V0版的Scheduler会遵循两个规则:
- 先到的Sequence先处理
- Victim Sequences > New Sequences > Running Sequences
Victim Sequences优先级最高比较好理解,因为由于显存紧张的缘故被置换到了CPU内存,所以在有空余显存时,优先将Victim Sequences加载回GPU内存并完成计算是一个最高优先级的事情。第二优先级是:如果有新的Sequences进来,就对其进行prefill。这样的好处是,在prefill后把它再加入到正在跑的其他sequences里,可以提高batch size,提升吞吐。
需要强调的是,上面介绍的是vLLM V0版本scheduler的策略。目前vLLM已经发布了V1版本,并对scheduler的策略进行了更新[4]。在新版本中,一个显著的区别是:取消了在调度时的传统prefill/decode阶段的区分,而是将用户给出的prompt tokens和模型生成的 output tokens统一对待,并用 {request_id:num_tokens} 这一字典统一描述了每次迭代要处理的token数。通过这种改造,使得vLLM天然支持了chunked-prefill(非一次性对整个sequence做prefill,而是可以分为多个chunk,分批次迭代来做)、prefix caching和speculative decoding。
在V1版本里,scheduler中维护两个队列(分别为waiting和running队列)。如下面的官方图展示的调度过程为例:
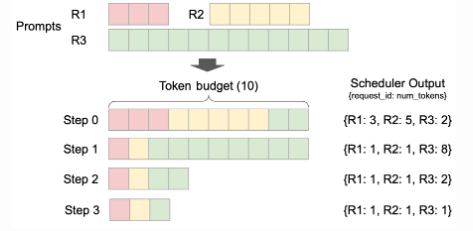
vLLM里会设置一个token_budget(通过scheduler_config.max_num_batched_tokens配置),用来决定每次调度中最多允许计算多少个token。图示里设置为10个token budget。
此时队列里有3个顺序prompts(请求)R1、R2和R3,长度分别为3、5、12。假设这3个请求均处于waiting队列中。vLLM仍然采用“先到的Sequence先处理”的方式,图示中可以看到后续4个step里scheduler的输出:
- Step 0:R1、R2所有的计算请求均可以直接在本轮调度运行,此时token_budget剩余为2,所以R3的请求中只有2个token可以加入本次调度。而后R1、R2、R3均从waiting队列转移到running队列
- Step 1:R1和R2完成了prefill,进入decode阶段,此轮以及后续每轮仅需要计算1个token。R3仍然在prefill阶段,基于剩余的token_budget,R3可以继续prefill 8个token
- 持续迭代这个过程,R3在Step 2完成prefill,并在Step 4时所有请求进入decode阶段。
在了解以上背景后,最后解释一下vLLM的batch机制。传统推理框架通常以整个请求为调度单位,导致GPU在等待最长请求完成时处于空闲状态。vLLM则采用token级调度,将多个请求的当前token生成步骤合并为一个batch处理。例如,如果有5个请求正在生成,每个请求每轮生成1个token,vLLM会将这5个token作为一个批次并行计算,而不是串行处理每个请求。在每一步生成后,调度器会检查已完成的序列,释放其占用的物理页,并立即填充新请求的prefill或生成阶段的token。这种"无需等待整个批次完成"的机制,就是continuous batching,使得GPU能够持续满载运行,提高了系统吞吐量。
3. Prefill-Decode分离
前面提到Prefill和Decode是两个对资源要求差异很大的两个阶段,一个是计算密集型,容易迅速饱和GPU;而另一个是访存密集型,需要更大的批量计算才能达到计算瓶颈,同时也更受到GPU内存带宽的限制。基于这点不同,将两者一起处理的话并不利于优化吞吐量,除了两者之间互相干扰导致性能下降外,它们之间的资源分配以及并行策略也会相互耦合并难以优化。所以,基于这两个不同的场景,自然就出现了将两者分离的方案,也就是prefill-decode分离。
一个最容易想到的方法就是将prefill和decode分配到不同的GPU,并为每个阶段制定并行策略,这样就直接解决了两者资源需求目标不同的问题。同时资源分配和并行策略进行了解耦,并可以分别进行优化。在一个实验中,使用单个A100-80GB GPU上运行一个13B的LLM,使用一个输入长度为512、输出长度为64的合成工作负载,并假设请求按泊松分布到达。结果表明:简单的分离方法在没有任何并行化的情况下就能实现2倍的有效吞吐量[5]。
在将prefill和decode分配在不同GPU上后,也引入了另一个问题,需要在GPU之间传输KV Cache,也就是在prefill阶段计算得到的KV需要传输到decode阶段使用的GPU上。KV Cache在推理时消耗的GPU内存很高,所以乍一看会认为KV Cache的传输会是一个瓶颈,但实际不然。通过合理的配置并利用到高速网络传输如NVLink和PCI-e5.0,KV cache的传输的开销可以高效到低于一个decoding step。在验证这点时,可以做一个理论上的计算。假设现在有一个8通道的PCI-e 5.0 x 16(每个通道64GB/s传输速度)作为GPU之间的节点网络。给定一个2048 token的请求,使用模型OPT-175B,可以估算KV cache传输的延迟为:
Latency = 2048 tokens * (4.5MB/token) / (64GB/s * 8) = 17.6ms
这个延迟要低于OPT-175B模型在A100上的单步decode延迟(大约在30-50ms)。对于更大的模型、更长的序列或更先进的网络(例如具有600GB/s带宽的A100 NVLink),KV Cache的传输相比单步decode的延迟会显得更微不足道。通过仔细布置prefill和decode的worker,并利用高带宽网络,可以有效隐藏KV Cache的传输开销。
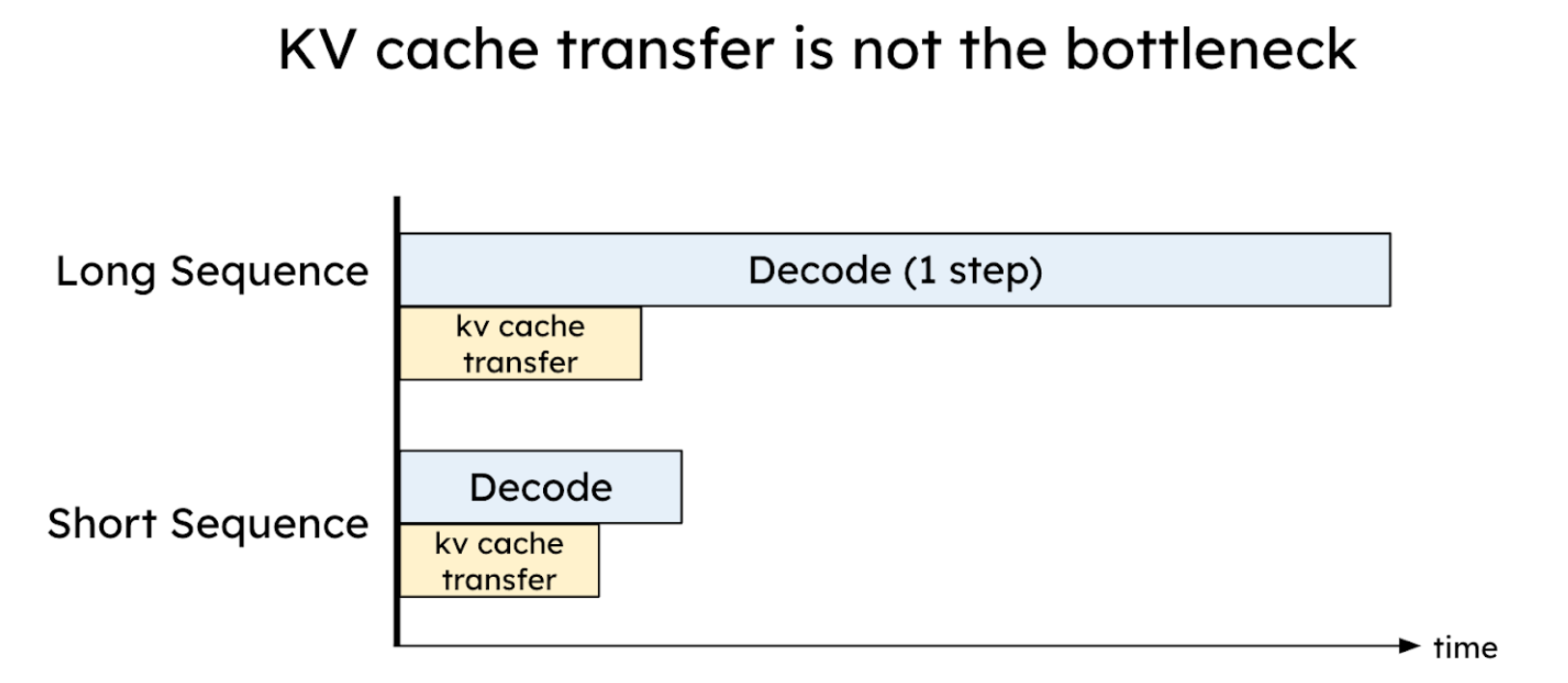
KV缓存传输的开销可以有效地减小到低于一个解码步骤的时间[6]
目前多个LLM推理框架都已经提供了PD分离的功能,包括vLLM,SGLang,Dynamo和llm-d。下面我们以vLLM为例介绍其实现方式。
3.1. vLLM实现prefill与decode
vLLM通过运行2个vLLM实例实现的pd分离,一个是prefill instance,另一个是decode instance。然后中间使用一个connector将prefill KV cache以及结果从prefill instance迁移到decode instance。
在这个功能中有3个关键的抽象组件:
- Connector:KV consumer通过connector以批量的方式从KV producer获取请求的KV Cache
- LookupBuffer:提供两个API,分别是insert(插入KV Cache到写入缓冲区)和drop_select(根据给定条件返回匹配的KV Cache,并将其从从缓冲区中删除)
- Pipe:单向的FIFO管道,用于tensor传输。支持send_tensor和rev_tensor两个操作
三个组件的运作方式如下图所示:

在vLLM中目前提供5种实现:
- SharedStorageConnector:通过文件/内存映射传输KV
- LMCacheConnector:基于NIXL的KV传输
- NixlConnector:完全异步的传输(send&recv)
- P2pNcclConnector:基于NCCL的点对点传输
- MultiConnector:可以封装多种Connector为一个列表,实现多级缓存/回退策略
然后我们再来看vLLM官方展示的workflow图:
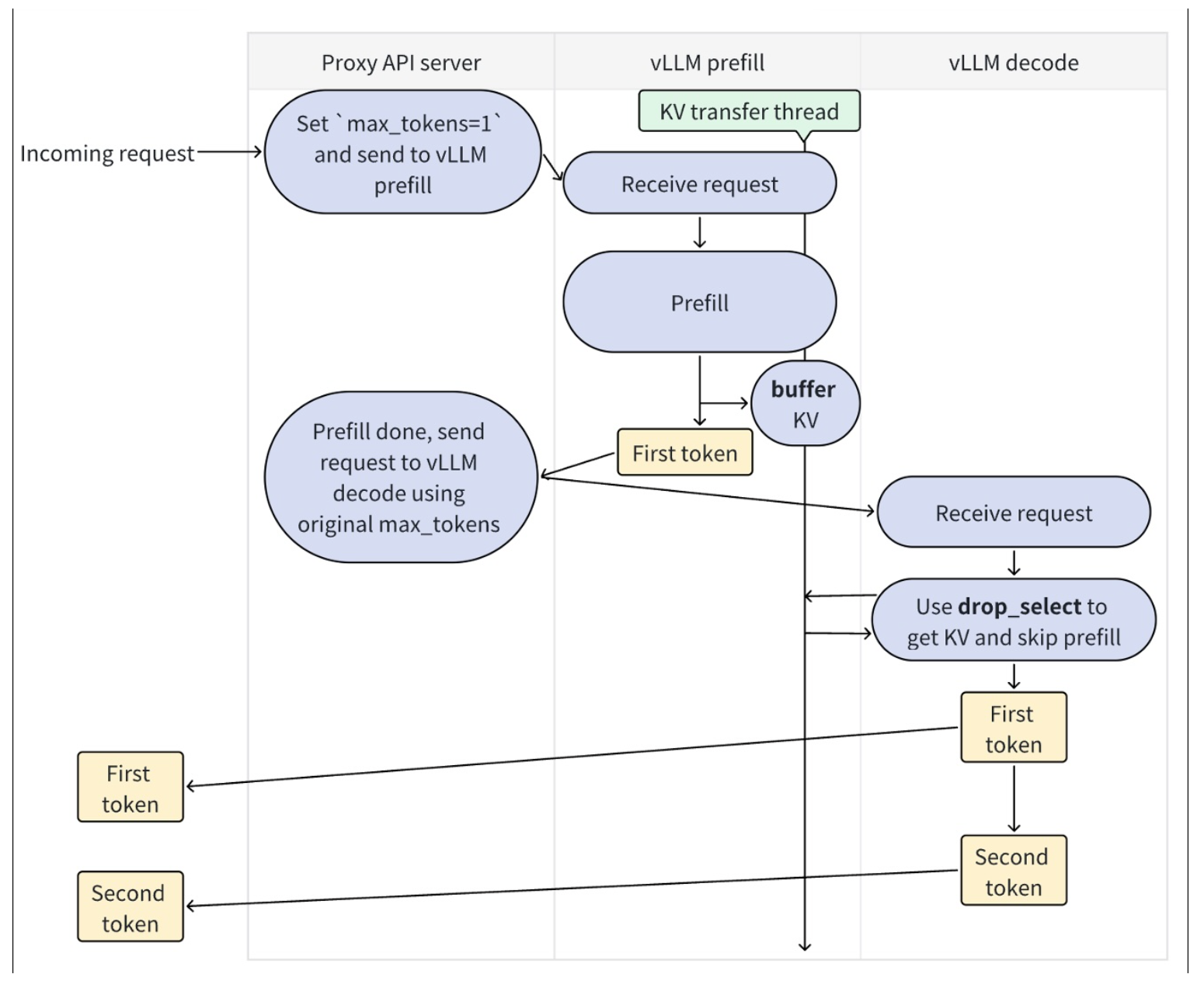
Disaggregated Prefilling workflow[7]
可以看到,请求先到达Proxy API Server,然后发往prefill实例进行prefill过程:
- 在prefill实例接收到请求后,开始执行prefill推理,并单独启动一个线程将KV-Cache异步写入KV lookup buffer
- 在prefill实例完成了prefill过程,并继续生成了首个token后,表示prefill阶段结束,并将此token返回给Proxy API Server进程,同时将请求发往decode实例
- Decode实例接收到请求后,从缓冲区获取KV Cache,跳过prefill阶段,开始进行decode过程,同时将首token和后续生成的token返回给前端
可以看到,在vLLM的prefill阶段里,并非只是生成prefill的token就结束,而是会顺便把第一个token也同时计算出来。另一方面,在vLLM的官方文档里也提到[7],目前该特性主要改善的是时延而非吞吐,需要根据TTFT(首token生成时间)和ITL(token间延迟)的需求进行调整参数。
总结
vLLM目前仍然是一个热门且具有代表性的LLM推理引擎,凭借其创新的PagedAttention显存管理和连续批处理技术,显著提升了推理吞吐量与显存利用率。它通过分页机制减少KV Cache碎片,以token级调度实现动态批处理,并支持prefill-decode分离架构,有效优化高并发场景下的性能表现,成为部署大语言模型的高效选择之一。在推理引擎方面,除了vLLM外,SGLang也是一个与vLLM非常有竞争力的推理引擎。相对于vLLM着力于在高并发单轮推理场景,SGLang的优势更多在于多轮对话和复杂处理场景。SGLang采用了基数树(Radix Tree)管理KV Cache的RadixAttention技术,通过自动识别和复用不同请求之间的共享前缀KV缓存,实现了更高的缓存命中率(3-5倍)。SGLang还引入了前端DSL(领域特定语言),简化了复杂LLM程序的开发流程。本文中提到的prefill-decode分离特性在SGLang中也提供了实现。虽然SGLang作为较新的框架,其社区规模和用户基数相比vLLM更少,但它的生态也正在快速发展,其高性能与高效率的优点也愈发受到社区关注。后续我们会继续介绍SGLang的特点与使用。
References
1. 企业级模型推理部署工具vllm使用指南 - 部署最新deepseek-v3-0324模型:https://zhuanlan.zhihu.com/p/1914740230273099340
2. Introduction to vLLM and PagedAttention:https://www.runpod.io/blog/introduction-to-vllm-and-pagedattention
3.【AI Infra漫谈系列】揭秘vLLM推理逻辑:https://zhuanlan.zhihu.com/p/697858922
4. vLLM V1: A Major Upgrade to vLLM's Core Architecture:https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
5. 揭秘老黄演讲中关键技术:PD分离!UCSD力作,LLM吞吐量跃升4倍:https://baijiahao.baidu.com/s?id=1827006277573818899&wfr=spider&for=pc
6. Throughput is Not All You Need: Maximizing Goodput in LLM Serving using Prefill-Decode Disaggregation:https://hao-ai-lab.github.io/blogs/distserve/
7. Disaggregated Prefilling:https://docs.vllm.ai/en/stable/features/disagg_prefill.html#development
vLLM框架:LLM推理的高效机制的更多相关文章
- MyBatis框架——动态SQL、缓存机制、逆向工程
MyBatis框架--动态SQL.缓存机制.逆向工程 一.Dynamic SQL 为什么需要动态SQL?有时候需要根据实际传入的参数来动态的拼接SQL语句.最常用的就是:where和if标签 1.参考 ...
- 组件化框架设计之Java SPI机制(三)
阿里P7移动互联网架构师进阶视频(每日更新中)免费学习请点击:https://space.bilibili.com/474380680 本篇文章将从深入理解java SPI机制来介绍组件化框架设计: ...
- php CI框架目录结构及运行机制
CI目录结构 CI主要组成部分为,application(应用文件夹).system(系统文件夹)和index.php入口文件. 应用文件夹中主要是存放控制器.模型和视图等,系统文件夹中主 ...
- Android 框架修炼-自己开发高效异步图片加载框架
一.概述 目前为止,第三方的图片加载框架挺多的,比如UIL , Volley Imageloader等等.但是最好能知道实现原理,所以下面就来看看设计并开发一个加载网络.本地的图片框架. 总所周知,图 ...
- Crystal框架配置参数加载机制详解?
前言 定义 配置参数定义的形式 配置参数文件定义在哪里? 配置参数加载的优先级 如何使用配置参数? 最佳实践 Jar项目中如何定义配置参数? War项目中如何定义或重载Jar包中的配置参数? 开发人员 ...
- Unity 游戏框架搭建 (五) 简易消息机制
什么是消息机制? 23333333,让我先笑一会. 为什么用消息机制? 三个字,解!!!!耦!!!!合!!!!. 我的框架中的消息机制用例: 1.接收者 ``` using UnityEngine ...
- 简易RPC框架-心跳与重连机制
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- 开源通用爬虫框架YayCrawler-框架的运行机制
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图: 首先各个组件的启动顺序建议是Master.Worker.Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启 ...
- java框架篇---hibernate之缓存机制
一.why(为什么要用Hibernate缓存?) Hibernate是一个持久层框架,经常访问物理数据库. 为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能. 缓存内的数据是对物理数 ...
- cassandra框架模型之二——存储机制 CommitLog MemTable SSTable
四.副本存储 Cassandra不像HBase是基于HDFS的分布式存储,它的数据是存在每个节点的本地文件系统中. Cassandra有三种副本配置策略: 1) SimpleStrategy (Rac ...
随机推荐
- 参加 Hugging Face 组织的 Gradio & MCP 智能体主题黑客松
欢迎参加 Gradio & MCP 智能体主题黑客松! 准备好了吗?一场以智能体(Agent)和模型上下文协议(Model Context Protocol,简称 MCP)为核心的全球在线黑客 ...
- Redis的zset底层数据结构,为什么用跳跃表而不用红黑树?
共同点:红黑树和跳表的插入.删除.查找以及迭代输出的时间复杂度是一样的. 跳表在区间查询的时候效率是高于红黑树的,它查找时,以O(logn)的时间复杂度定位到区间的起点,然后在原始链表往后遍历就 ...
- 3D Gaussian splatting 03: 用户数据训练和结果查看
目录 3D Gaussian splatting 01: 环境搭建 3D Gaussian splatting 02: 快速评估 3D Gaussian splatting 03: 用户数据训练和结果 ...
- 远程登录Mysql,命令行登录Mysql的方法
1.本地登录MySQL命令:mysql -u root -p //root是用户名,输入这条命令按回车键后系统会提示你输入密码2.指定端口号登录MySQL数据库将以上命令:mysql -u roo ...
- RT-Thread 4.0.3 适配 UART_V2 版本
RT-Thread 4.0.3 适配 UART_V2 版本 本文为针对发布版4.0.3 进行 UART_V2 驱动的移植适配操作笔记. 由于使用了 libmodbus 软件包,需要 posix_ter ...
- 如何在FastAPI中玩转GitHub认证,让用户一键登录?
title: 如何在FastAPI中玩转GitHub认证,让用户一键登录? date: 2025/06/22 09:11:47 updated: 2025/06/22 09:11:47 author: ...
- MySQL 07 行锁功过:怎么减少行锁对性能的影响?
行锁是针对数据表中行记录的锁,是在引擎层由引擎实现的. 从两阶段锁说起 在InnoDB事务中,行锁是在需要的时候才加上的,但并不是不需要了就立即释放,而是等到事务结束时才释放,这就是两阶段锁协议. 知 ...
- C# DateTime时间戳帮助类型
https://www.cnblogs.com/minotauros/p/10773258.html /// <summary> /// 时间工具类 /// </summary> ...
- 渗透测试工作站搭建:Kali + Wave + Zsh + Tmux + 工具集整合实践
前言 在开始任何渗透测试工作之前,搭建一个可靠高效的工作环境至关重要.这包括组织工具.配置系统,以及确保所有必要资源随时可用.通过尽早建立结构良好的测试基础架构,我们可以减少停机时间.最大程度地减少错 ...
- Codeforces Round #619 (Div. 2) ABC 题解
A. Three Strings 题意:每次可以把c[i]拿去和a[i]或b[i]交换. 问你能否把ab变成相等. 思路:在ab不相等的时候看看c能不能与一方相等来中和.不能的话就不行. view c ...