开源通用爬虫框架YayCrawler-框架的运行机制
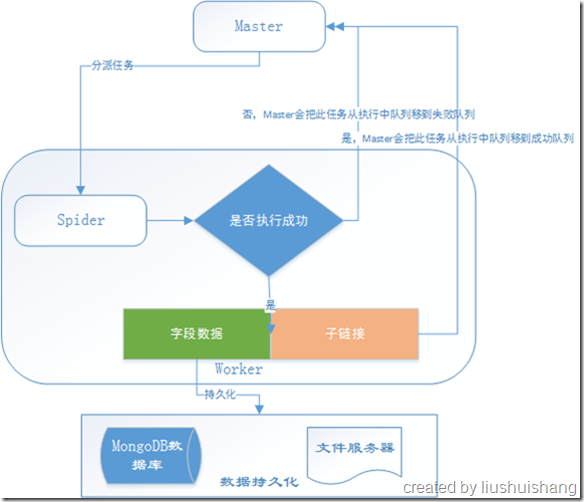
这一节我将向大家介绍一下YayCrawler的运行机制,首先允许我上一张图:
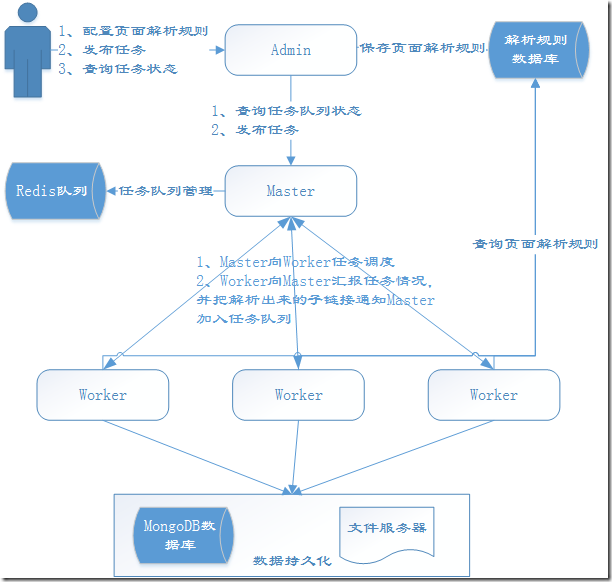
首先各个组件的启动顺序建议是Master、Worker、Admin,其实不按这个顺序也没关系,我们为了讲解方便假定是这个启动顺序。
一、Master端分析
Master启动后会连接Redis查询任务队列状态,Master维持了四个状态的任务队列:待执行任务队列、执行中任务队列、成功任务队列和失败任务队列。Master内部有一个任务调度器,Master等Worker心跳包到来的时候,观察Worker是否还有任务分配的余地(每个Worker可以设置自己本地的任务队列的长度),如果Worker还能接收n个任务,任务调度器就会从待执行任务队列中取至多n个任务分配给该Worker。分配成功后,Master会把这n个任务从待执行队列移到执行中队列。
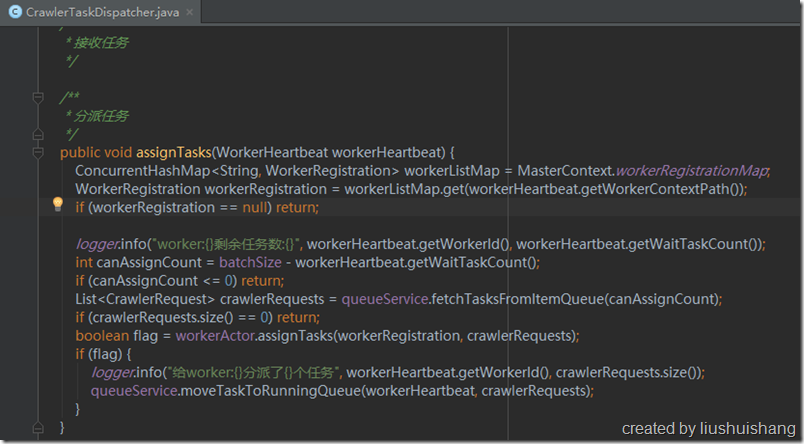
Master会定期扫描已注册的Worker,如果某个Worker的上次心跳时间距离了现在已经超过了2倍Worker自身的心跳间隔,那么Master会认为此Worker已经失联,不能再给它分配任务,因此会把它从已注册列表移除。
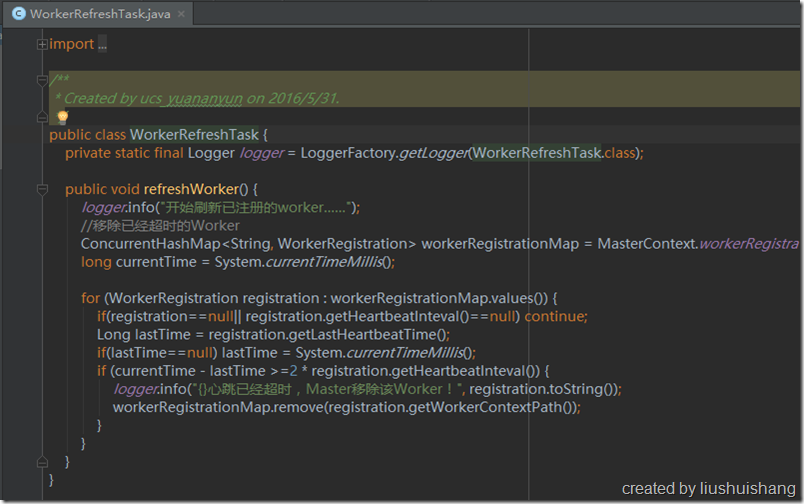
Master会定期扫描执行中队列,如果发现某个任务的分配时间距离现在已经超过了某个预设值,我们可以认为这个任务出现了差错,应该重新执行一遍,因此Master会重新把这个任务从执行中队列移到待执行队列,以便再次分配执行。
二、Worker端分析
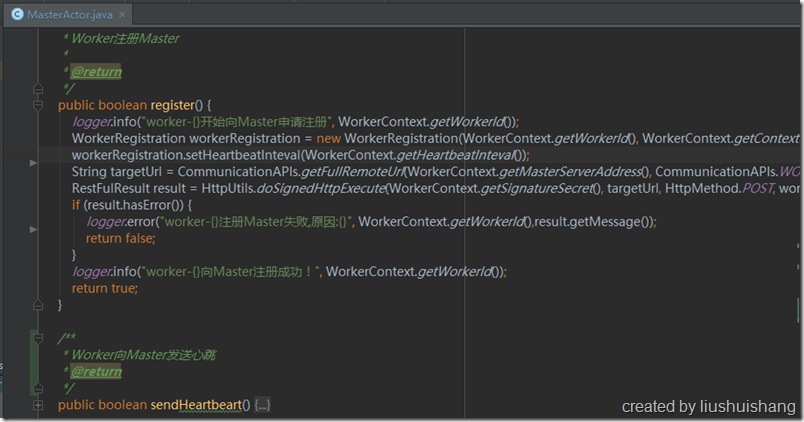
Worker的配置文件里面配置了Master的服务通信地址,Worker启动的时候就会通过这个地址向Master注册,注册的信息包括Worker的通信地址、心跳间隔、任务配额等。Worker注册成功后会定期向Master发送心跳,向Master汇报自己的状态的同时领取任务。
三、Admin端分析
Admin端主要是为用户提供一个操作的接口界面,这是一个Web工程,Admin端的配置文件里面也记录了Master的服务通信地址。用户在Admin端可以针对目标网页编写抽取规则,测试规则,直到保存到数据库。用户可以在界面上查看任务的执行情况,比如成功的任务,失败的任务,任务的结果等;用户也可以在界面上单个或批量发布普通任务/定时任务,这些任务最终会在Worker上执行,Worker在解析的时候会参考用户设置的解析规则。
四、其他
Master、Worker和Admin三者之间的通信是基于http协议的,为了安全,通信过程中都使用了token, timestamp, nonce来对消息体进行签名并验证,只有签名正确才能通信成功。
框架中的队列、持久化方式都是基于接口编程的,您可以很方便的用自己的实现来替换原有的处理。
开源通用爬虫框架YayCrawler-框架的运行机制的更多相关文章
- 开源通用爬虫框架YayCrawler-开篇
各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品--YayCrawler,其在GitHub上的网址是:https://github.com/liushuishang/YayCraw ...
- 开源通用爬虫框架YayCrawler-运行与调试
本节我将向大家介绍如何运行与调试YayCrawler.该框架是采用SpringBoot开发的,所以可以通过java –jar xxxx.jar的方式运行,也可以部署在tomcat等容器中运行. 首先 ...
- 01_日志采集框架Flume简介及其运行机制
离线辅助系统概览: 1.概述: 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出. 任务调度等不可或缺的辅助系统,而这些辅助 ...
- 开源通用爬虫框架YayCrawler-页面的抽取规则定义
本节我将向大家介绍一下YayCrawler的核心-页面的抽取规则定义,这也是YayCrawler能够做到通用的主要原因之一.如果我要爬去不同的网站的数据,尽管他们的网站采用的开发技术不同.页面的结构不 ...
- php CI框架目录结构及运行机制
CI目录结构 CI主要组成部分为,application(应用文件夹).system(系统文件夹)和index.php入口文件. 应用文件夹中主要是存放控制器.模型和视图等,系统文件夹中主 ...
- 爬虫框架YayCrawler
爬虫框架YayCrawler 各位好!从今天起,我将用几个篇幅的文字向大家介绍一下我的一个开源作品——YayCrawler,其在GitHub上的网址是:https://github.com/liush ...
- 爬虫(十八):Scrapy框架(五) Scrapy通用爬虫
1. Scrapy通用爬虫 通过Scrapy,我们可以轻松地完成一个站点爬虫的编写.但如果抓取的站点量非常大,比如爬取各大媒体的新闻信息,多个Spider则可能包含很多重复代码. 如果我们将各个站点的 ...
- 【转】Python爬虫(6)_scrapy框架
官网链接:https://docs.scrapy.org/en/latest/topics/architecture.html 性能相关 在编写爬虫时,性能的消耗主要在IO请求中,当单进程单线程模式下 ...
- 爬虫之scrapy框架
解析 Scrapy解释 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓 ...
随机推荐
- <20190102>收录些比较低级错误导致的主板故障现象
今天收录俩个比较低级的错误. 故障现象: 水冷排风扇高速运转, 并无法调控. 现在CPU散热的水冷排都设计了三条线, 温控4Pin , 水泵线 3Pin , 接在机箱上USB口取电的灯线或者 ...
- python之面向对象进阶2
封装.property装饰器 封装分为3种情况:封装对象的属性.封装类的属性.封装方法. 封装对象的属性:(在属性名前加双下划线__) class Person: def __init__(self, ...
- MATLAB卷积运算(conv、conv2、convn)解释
1 conv(向量卷积运算) 所谓两个向量卷积,说白了就是多项式乘法.比如:p=[1 2 3],q=[1 1]是两个向量,p和q的卷积如下:把p的元素作为一个多项式的系数,多项式按升幂(或降幂)排列, ...
- mysql5.6.8源码安装
内核: [root@opop ~]# cat /etc/centos-release CentOS release 6.8 (Final)[root@opop ~]# uname -aLinux op ...
- ESP WIFI
esp_err_tesp_wifi_init(constwifi_init_config_t *config) 这个WIFI初始化函数是使用所有的WIFI API之前必须调用的函数: 函数的参数是一个 ...
- 【Codeforces 526D】Om Nom and Necklace
Codeforces 526 D 题意:给一个字符串,求每个前缀是否能表示成\(A+B+A+B+\dots+A\)(\(k\)个\(A+B\))的形式. 思路1:求出所有前缀的哈希值,以便求每个子串的 ...
- three.js - 渲染并展示三维对象
看结果: 看源码及解释: <!DOCTYPE html> <html lang="en"> <head> <meta charset=&q ...
- 网易云音乐 歌词制作软件 BesLyric (最新版本下载)
导读 BesLyric , 一款专门制作 网易云音乐 LRC 滚动歌词的软件! 搜索.下载.制作 歌词更方便! 哈哈,喜欢网易云音乐,又愁于制作歌词的童鞋有福啦!Beslyric 为你排忧解难! 本文 ...
- docker[caffe&&pycaffe]
0 引言 今天花了一天,完成了整个caffe的dockerfile编写,其支持python3.6.6,这里主要的注意点是protobuf的版本(在3.6.0之后,只支持c11),还有在制作镜像的时候注 ...
- Luogu3613 睡觉困难综合征/BZOJ4811 Ynoi2017 由乃的OJ 树链剖分、贪心
传送门 题意:给出一个$N$个点的树,树上每个点有一个位运算符号和一个数值.需要支持以下操作:修改一个点的位运算符号和数值,或者给出两个点$x,y$并给出一个上界$a$,可以选取一个$[0,a]$内的 ...