Python 爬虫从入门到进阶之路(十三)
之前的文章我们介绍了一下 BeautifulSoup4 模块,接下来我们就利用 BeautifulSoup4 模块爬取《糗事百科》的糗事。
之前我们已经分别利用 re 模块和 Xpath 模块爬取过糗百,我们只需要在其基础上做一些修改就可以了,为了保证项目的完整性,我们重新再来一遍。
我们要爬取的网站链接是 https://www.qiushibaike.com/text/page/1/ 。
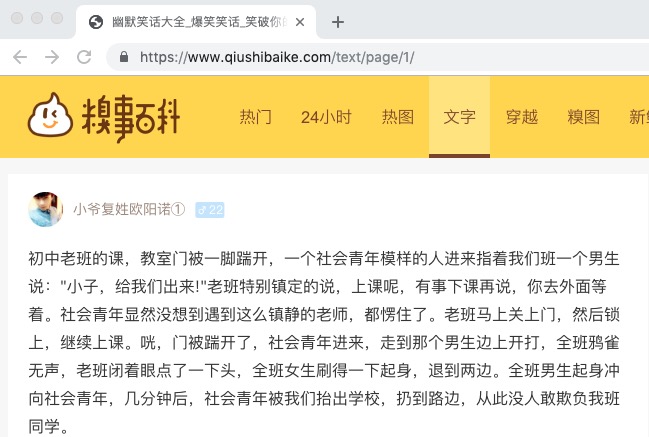
我们通过浏览器开发者工具的控制台发现我们想要的数据在 <div class="content">......</div> 内:

根据上面的分析我们可以写出代码如下:
import urllib.request
from bs4 import BeautifulSoup
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context url = "https://www.qiushibaike.com/text/page/1/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 解析html 为 Beautiful Soup 对象
soup = BeautifulSoup(html, "lxml")
content_list = soup.select('div.content')
print(content_list)
最终我们打印结果如下:
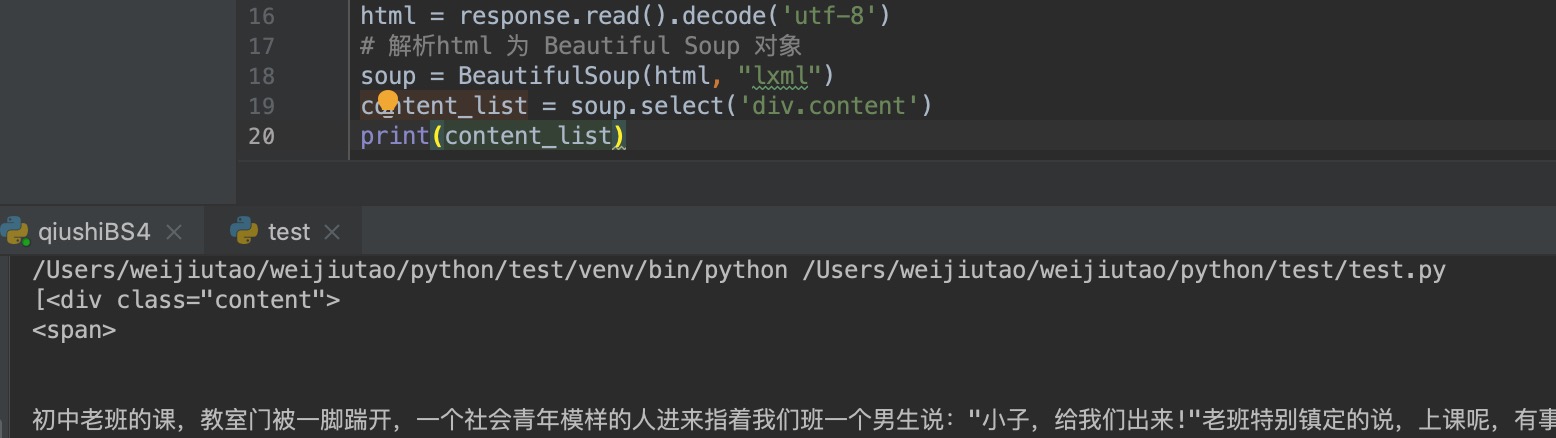
从上面的输出结果可以看出我们已经拿到了我们想要的数据,并且是一个列表类型,我们对列表进行操作扥别拿到糗事再存储到本地即可。
for item in item_list:
item = item.get_text().replace("\n", "")
self.writePage(item)
上面就可以实现一个获取 糗事百科 的糗事的简单爬虫,但是只能爬取单个页面的内容,通过分析 url 我们发现 https://www.qiushibaike.com/text/page/1/ 中最后的 1 即为页码,我们就可以根据这个页码逐一爬取更多页面的内容,最终的代码如下:
import urllib.request
from bs4 import BeautifulSoup
import ssl # 取消代理验证
ssl._create_default_https_context = ssl._create_unverified_context class Spider:
def __init__(self):
# 初始化起始页位置
self.page = 1
# 爬取开关,如果为True继续爬取
self.switch = True def loadPage(self):
"""
作用:打开页面
"""
url = "https://www.qiushibaike.com/text/page/" + str(self.page) + "/"
# User-Agent头
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36'
headers = {'User-Agent': user_agent}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
# 获取每页的HTML源码字符串
html = response.read().decode('utf-8')
# 解析html 为 Beautiful Soup 对象
soup = BeautifulSoup(html, "lxml")
content_list = soup.select('div.content')
# 调用dealPage() 处理糗事里的杂七杂八
self.dealPage(content_list) def dealPage(self, item_list):
"""
@brief 处理得到的糗事列表
@param item_list 得到的糗事列表
@param page 处理第几页
"""
for item in item_list:
item = item.get_text().replace("\n", "")
self.writePage(item) def writePage(self, text):
"""
@brief 将数据追加写进文件中
@param text 文件内容
"""
myFile = open("./qiushi.txt", 'a') # 追加形式打开文件
myFile.write(text + "\n\n")
myFile.close() def startWork(self):
"""
控制爬虫运行
"""
# 循环执行,直到 self.switch == False
while self.switch:
# 用户确定爬取的次数
self.loadPage()
command = input("如果继续爬取,请按回车(退出输入quit)")
if command == "quit":
# 如果停止爬取,则输入 quit
self.switch = False
# 每次循环,page页码自增1
self.page += 1
print("爬取结束!") if __name__ == '__main__':
# 定义一个Spider对象
qiushiSpider = Spider()
qiushiSpider.startWork()
最终会在本地添加一个 qiushi.txt 的文件,结果如下:

Python 爬虫从入门到进阶之路(十三)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- Hadoop源代码分析:HDFS读取和写入数据流控制(DataTransferThrottler类别)
DataTransferThrottler类别Datanode读取和写入数据时控制传输数据速率.这个类是线程安全的,它可以由多个线程共享. 用途是构建DataTransferThrottler对象,并 ...
- svm资料收集
向量点乘(内积)和叉乘(外积.向量积)概念及几何意义解读: https://blog.csdn.net/dcrmg/article/details/52416832 三角形余弦定理:https://z ...
- vi学习(1)
今天下午看了vi频繁使用的操作,现在记录,为了方便日后查询. 按vi模式.进入命令3部分. (一) 一般模式下 字符操作:上下左右箭头(或kjhl)能够实现光标上下左右移动一位. 假设想要进行多次移动 ...
- cocos2dx 2.2.3 xcode5.0,新mac项目错误
cocos2dx 2.2.3 xcode5.0,新建mac项目报错 Undefined symbols for architecture x86_64: "cocos2d::extens ...
- 使用lead分析功能相似的结构9*9乘法口诀功能
今天兄弟们的帮助,数据库,具有数据如下面的表: no name 1 a 2 b 3 c 4 d 怎样用一个sql显演示样例如以下结果: ab ac ad bc bd cd 对 ...
- jquery实现div拖拽
1.引入jquery1.8.3 ,模块拖拽js代码: //模块拖拽 $(function(){ var _move=false;//移动标记 var _x,_y;//鼠标离控件左上角的相对位置 $(& ...
- wpf自定义带刻度的柱状图控件
效果图: 主要代码xaml: <UserControl x:Class="INSControls._01Conning.Steer.ConningSpeedBar" xmln ...
- UWP项目生成错误: 未能使用“CompileXaml”任务的输入参数初始化该任务。“CompileXaml”任务不支持“PlatformXmlDir”参数。请确认该参数存在于此任务中,并且是可设置的公共实例属性。
UWP项目生成错误: 未能使用“CompileXaml”任务的输入参数初始化该任务.“CompileXaml”任务不支持“PlatformXmlDir”参数.请确认该参数存在于此任务中,并且是可设置的 ...
- C#最简单的文本加密
#region AES加密 public static byte[] TextEncrypt(string content, string secretKey) { byte[] data = Enc ...
- 基于X.509证书和SSL协议的身份认证过程实现(OpenSSL可以自己产生证书,有TCP通过SSL进行实际安全通讯的实际编程代码)good
上周帮一个童鞋做一个数字认证的实验,要求是编程实现一个基于X.509证书认证的过程,唉!可怜我那点薄弱的计算机网络安全的知识啊!只得恶补一下了. 首先来看看什么是X.509.所谓X.509其实是一种非 ...