简易数据分析 07 | Web Scraper 抓取多条内容

这是简易数据分析系列的第 7 篇文章。
在第 4 篇文章里,我讲解了如何抓取单个网页里的单类信息;
在第 5 篇文章里,我讲解了如何抓取多个网页里的单类信息;
今天我们要讲的是,如何抓取多个网页里的多类信息。
这次的抓取是在简易数据分析 05的基础上进行的,所以我们一开始就解决了抓取多个网页的问题,下面全力解决如何抓取多类信息就可以了。
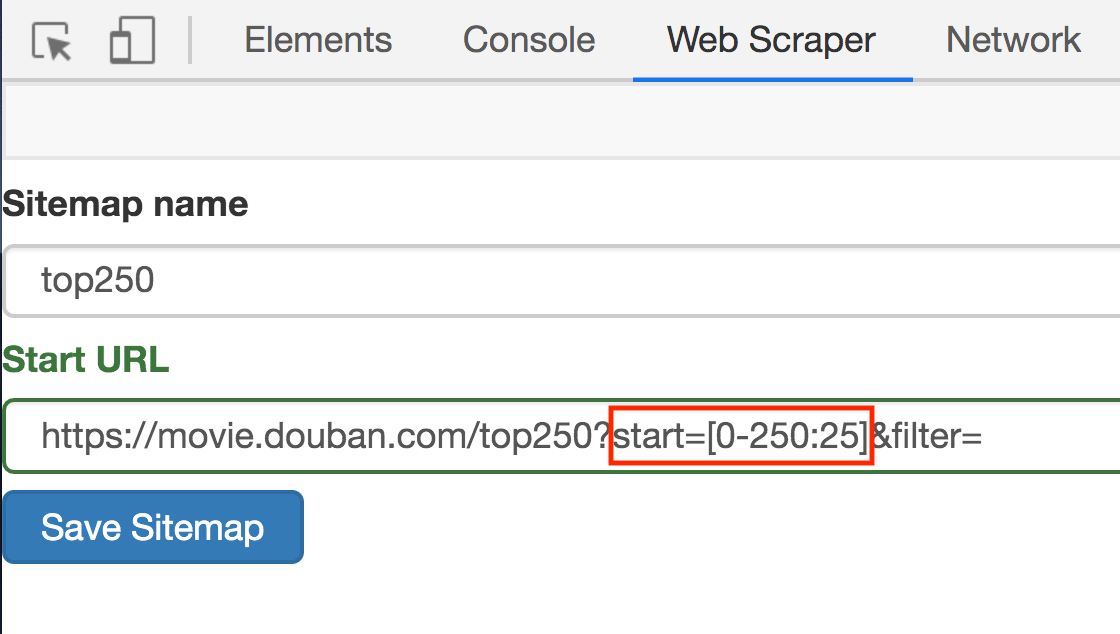
我们在实操前先把逻辑理清:
上几篇只抓取了一类元素:电影名字。这期我们要抓取多类元素:排名,电影名,评分和一句话影评。
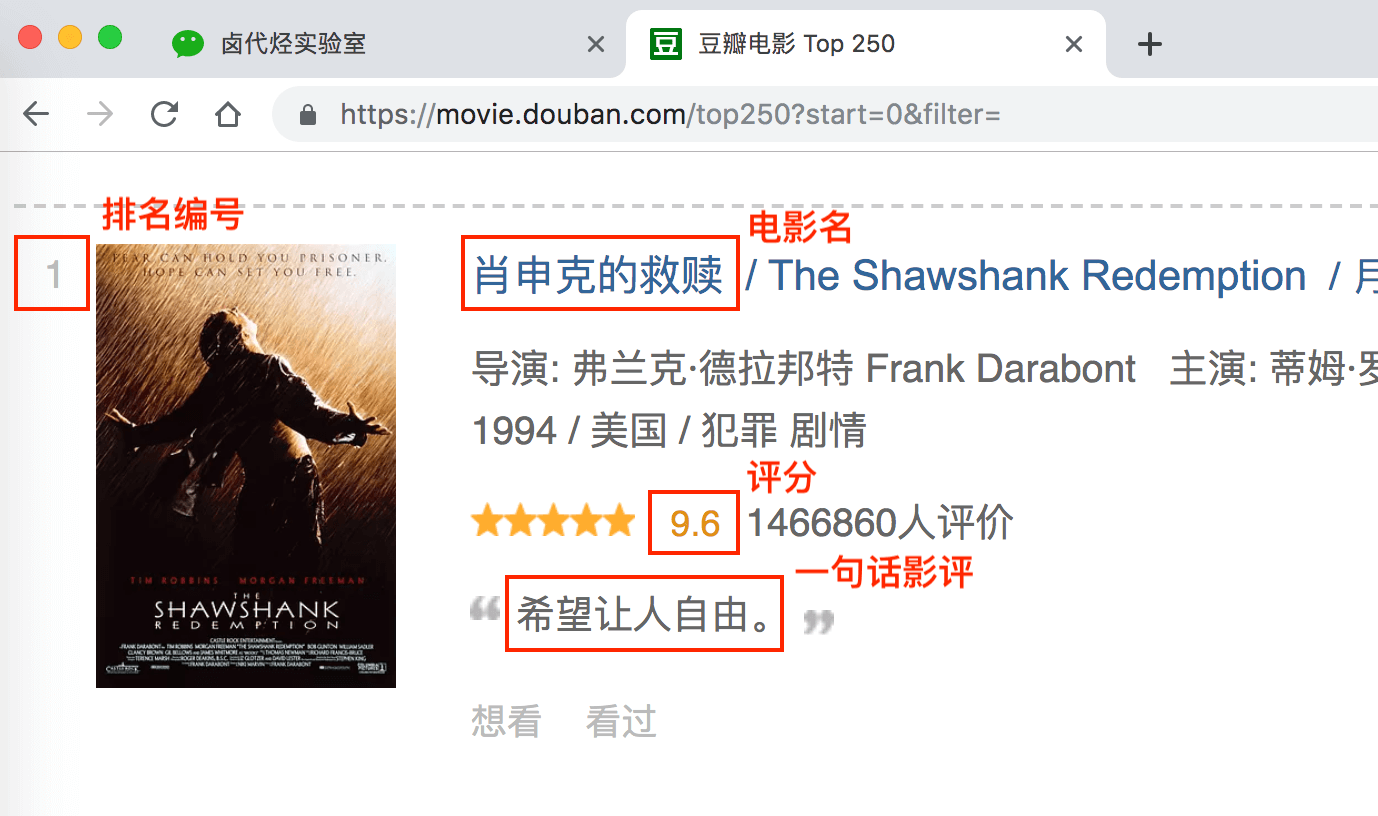
根据 Web Scraper 的特性,想抓取多类数据,首先要抓取包裹多类数据的容器,然后再选择容器里的数据,这样才能正确的抓取。我画一张图演示一下:

我们首先要抓取多个 container(容器),再抓取 container 里的元素:编号、电影名、评分和一句话影评,当爬虫运行完后,我们就会成功抓取数据。
概念上搞清楚了,我们就可以讲实际操作了。
如果对以下的操作有疑问,可以看 简易数据分析 04 的内容,那篇文章详细图解了如何用 Web Scraper 选择元素的操作
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据

2.删除掉旧的 selector,点击 Add new selector 增加一个新的 selector

3.在新的 selector 内,注意把 Type 类型改为 Element(元素),因为在 Web Scraper 里,只有元素类型才能包含多个内容。

我们勾选的元素区域如下图所示,确认无误后点击 Save selector 按钮,就会回退到上一个操作面板。
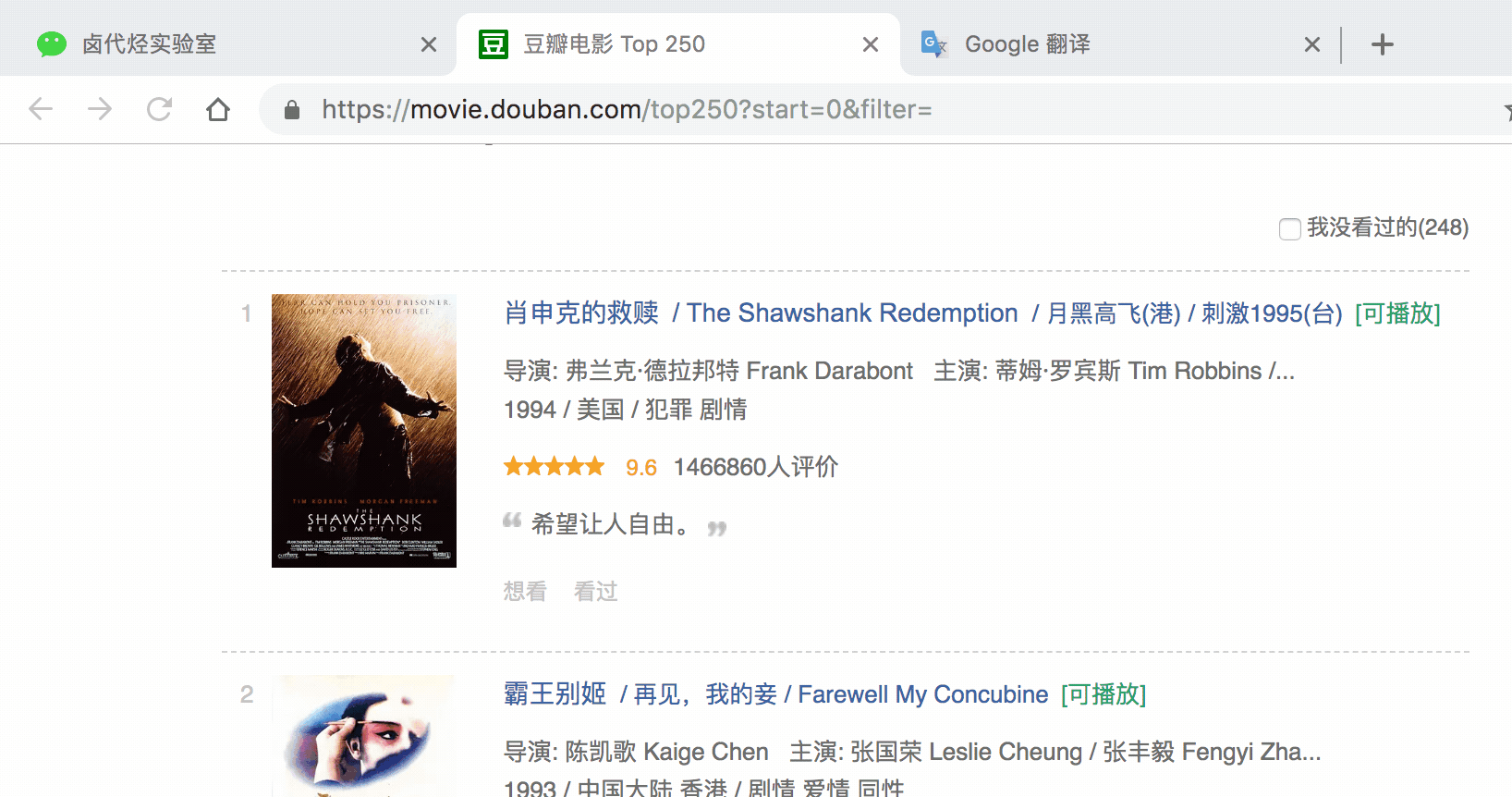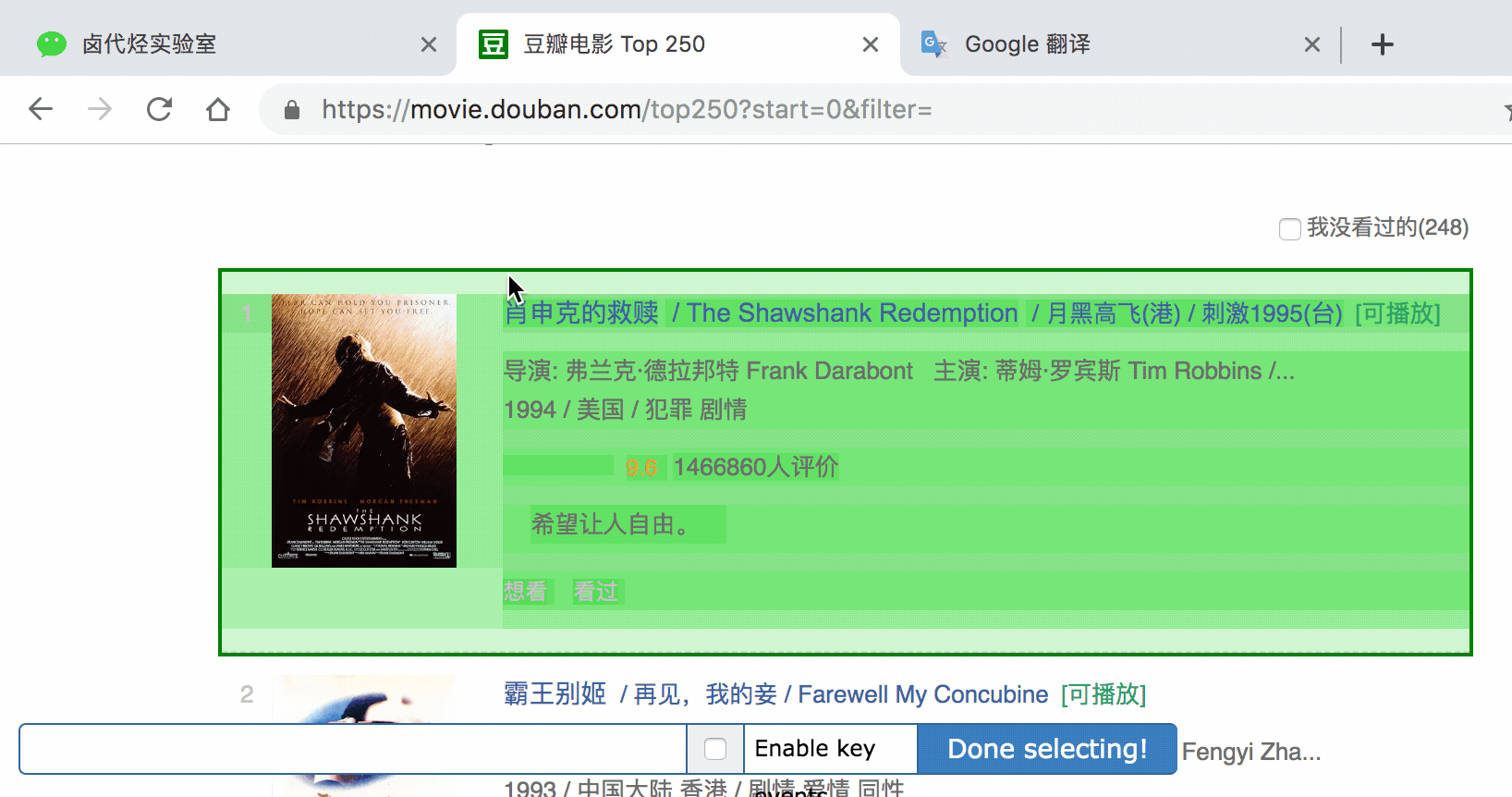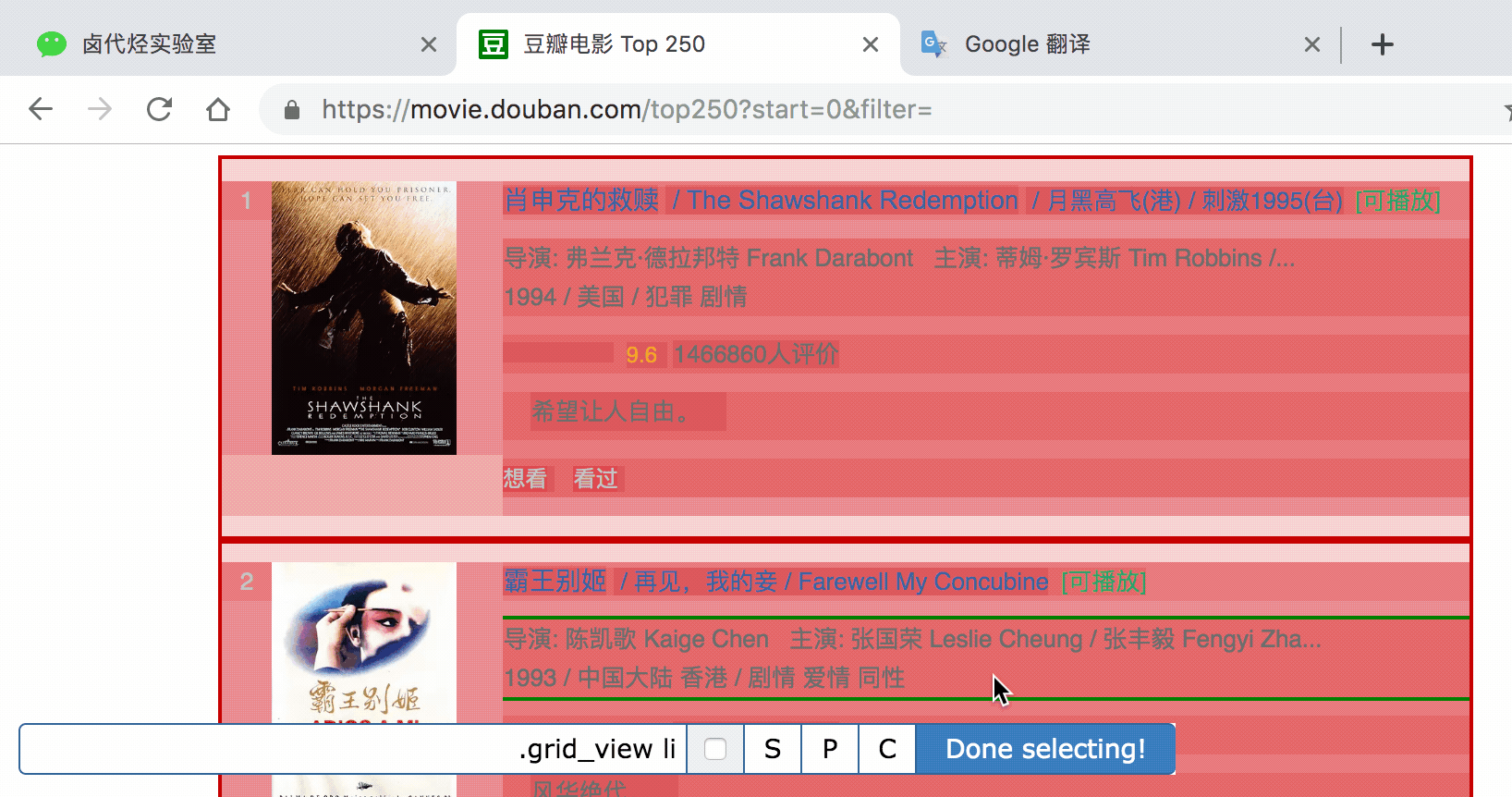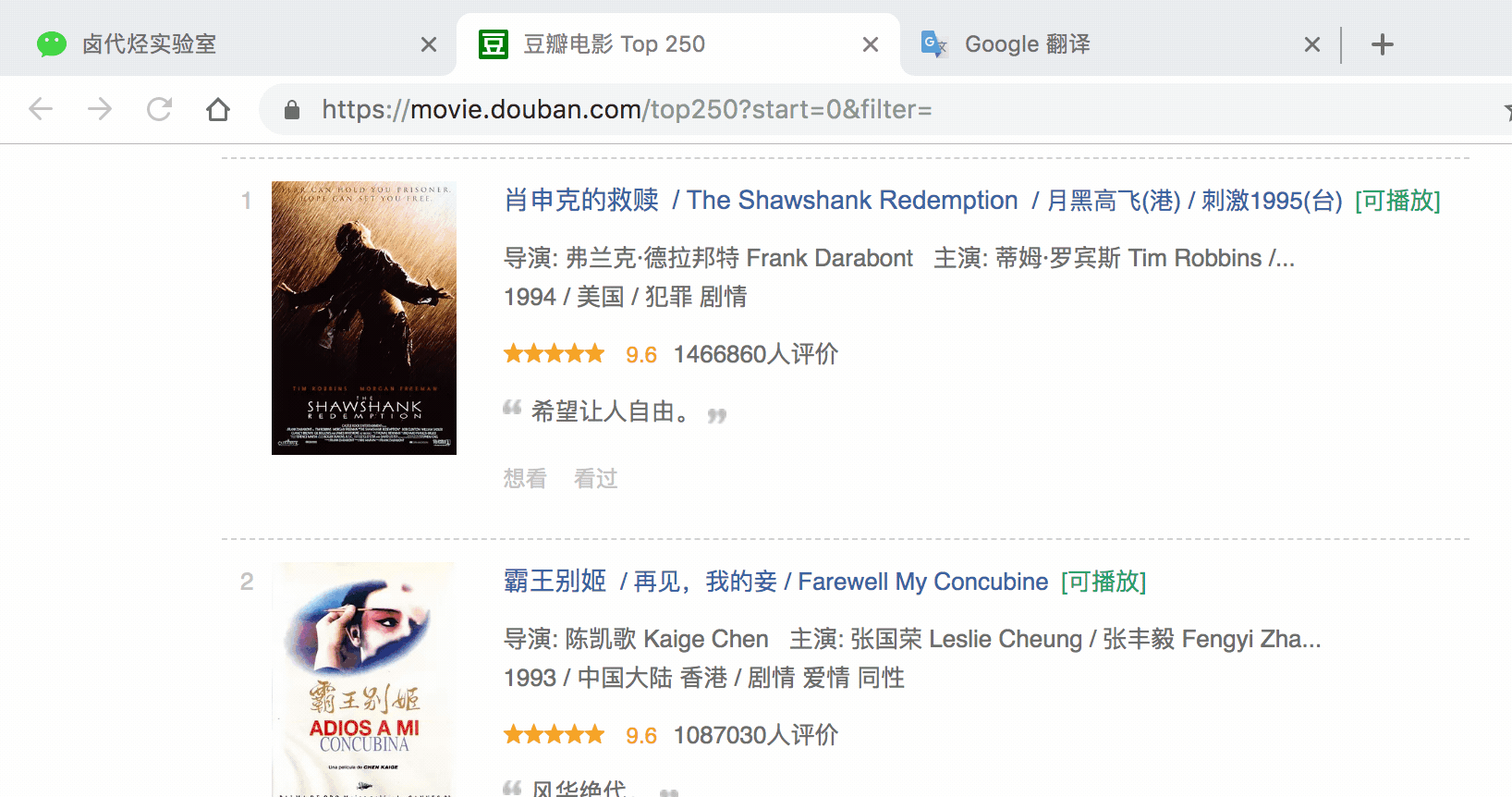
在新的面板里,点击刚刚创建的 selector 那行数据:

点击后我们就会进入一个新的面板,根据导航我们可知在 container 内部。

在新的面板里,我们点击 Add new selector,新建一个 selector,用来抓取电影名,类型为 Text,值得注意的是,因为我们是在 container 内选择文字的,一个 container 内只有一个电影名,所以多选不要勾选,要不然会抓取失败。

选择电影名的时候你会发现 container 黄色高亮,我们就在黄色的区域里选择电影名就好了。
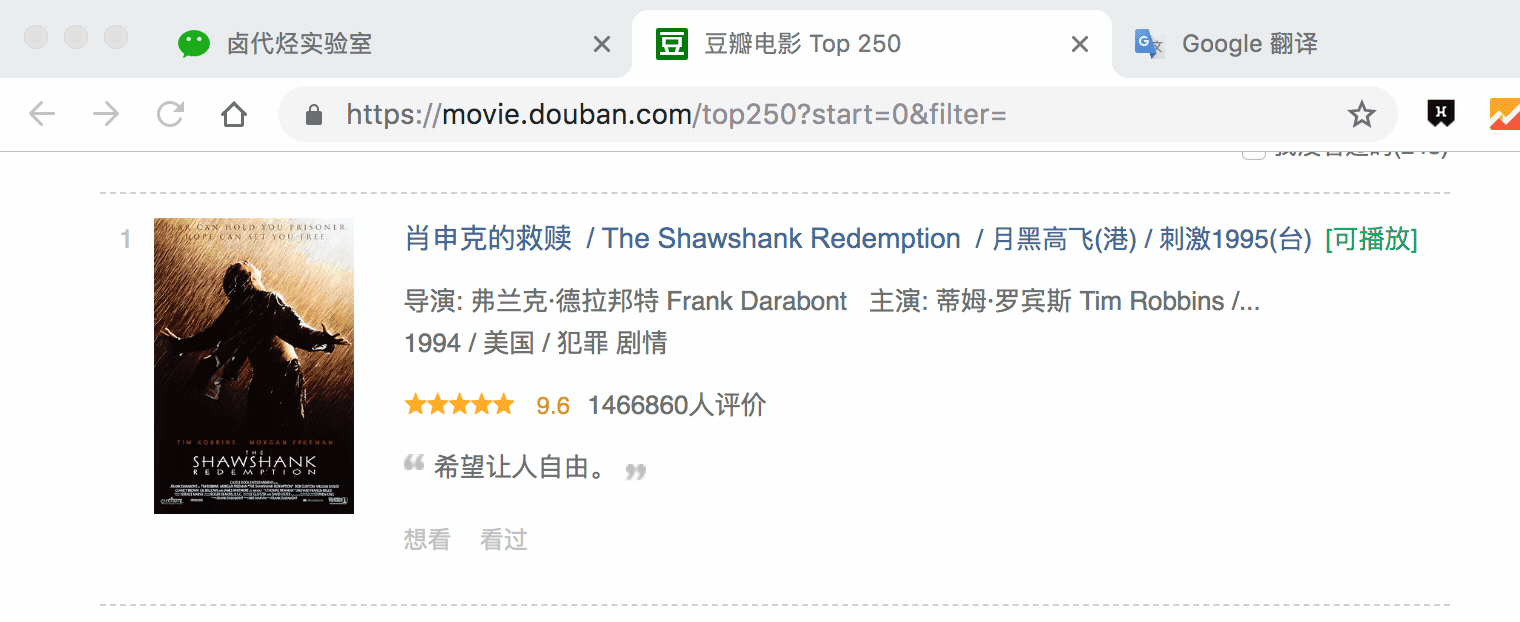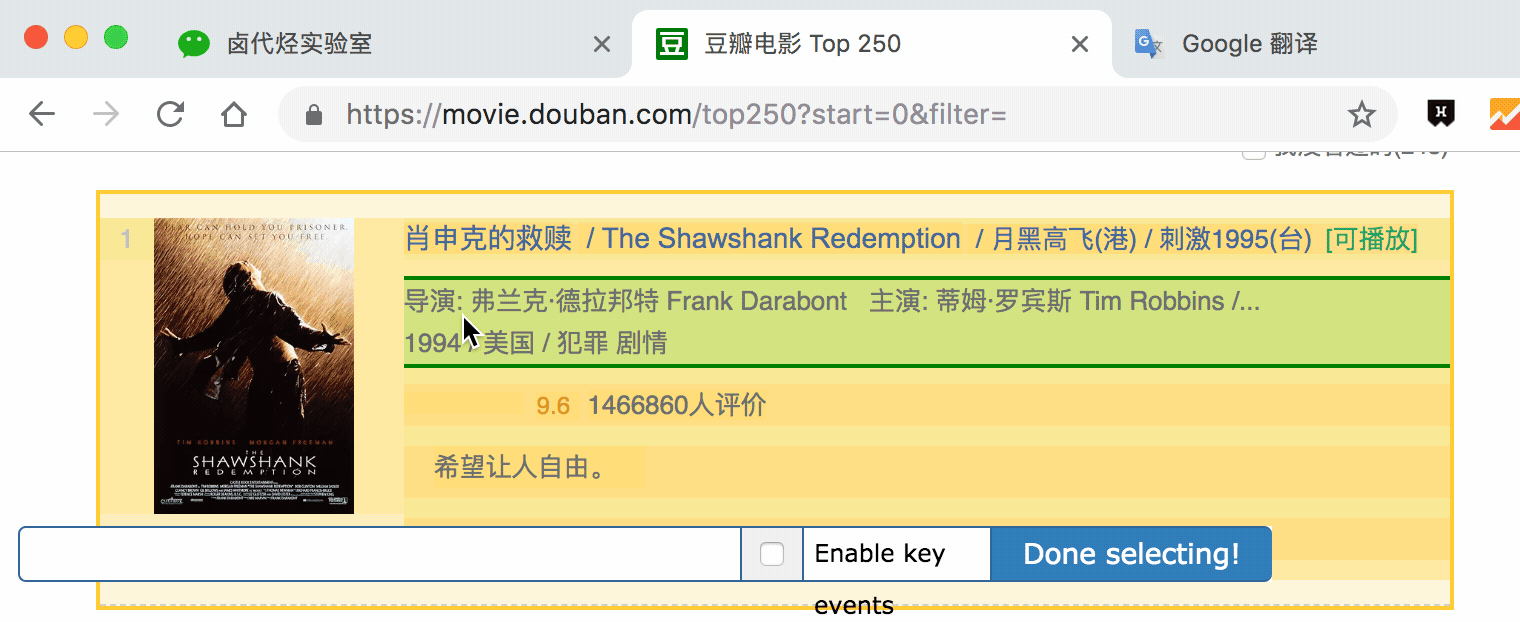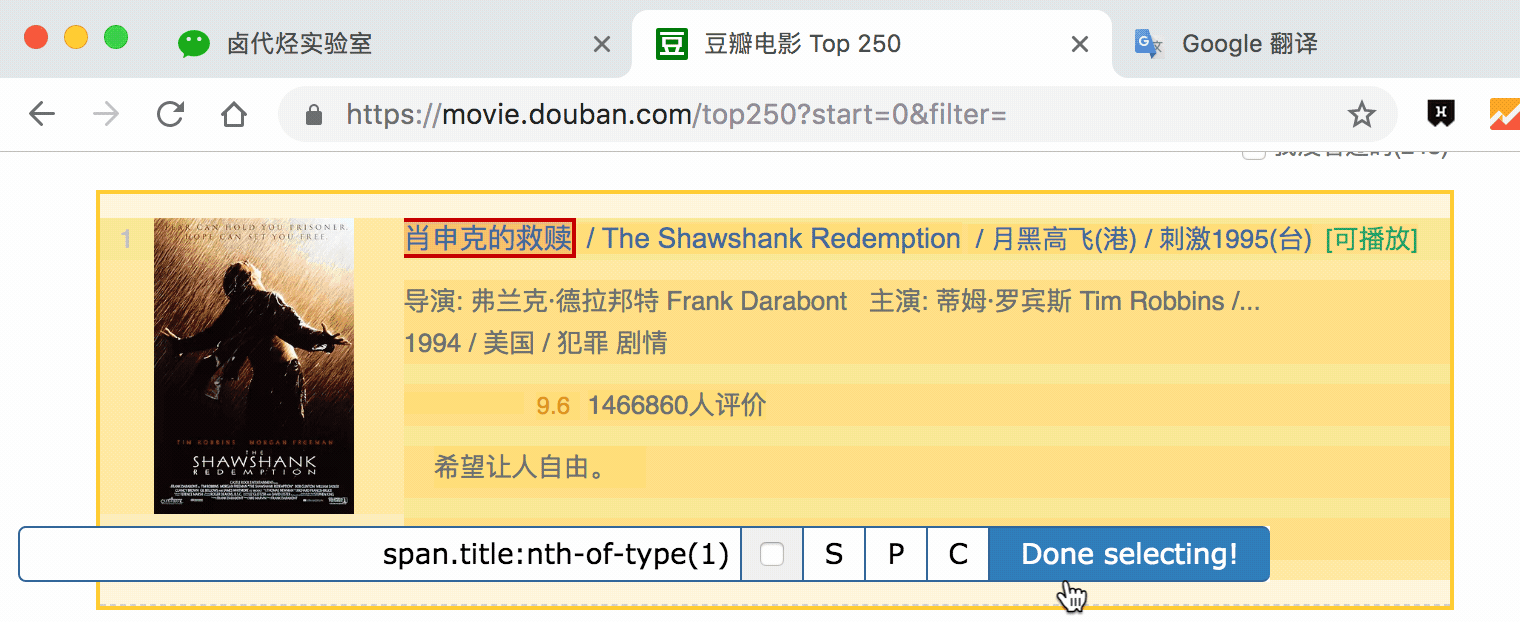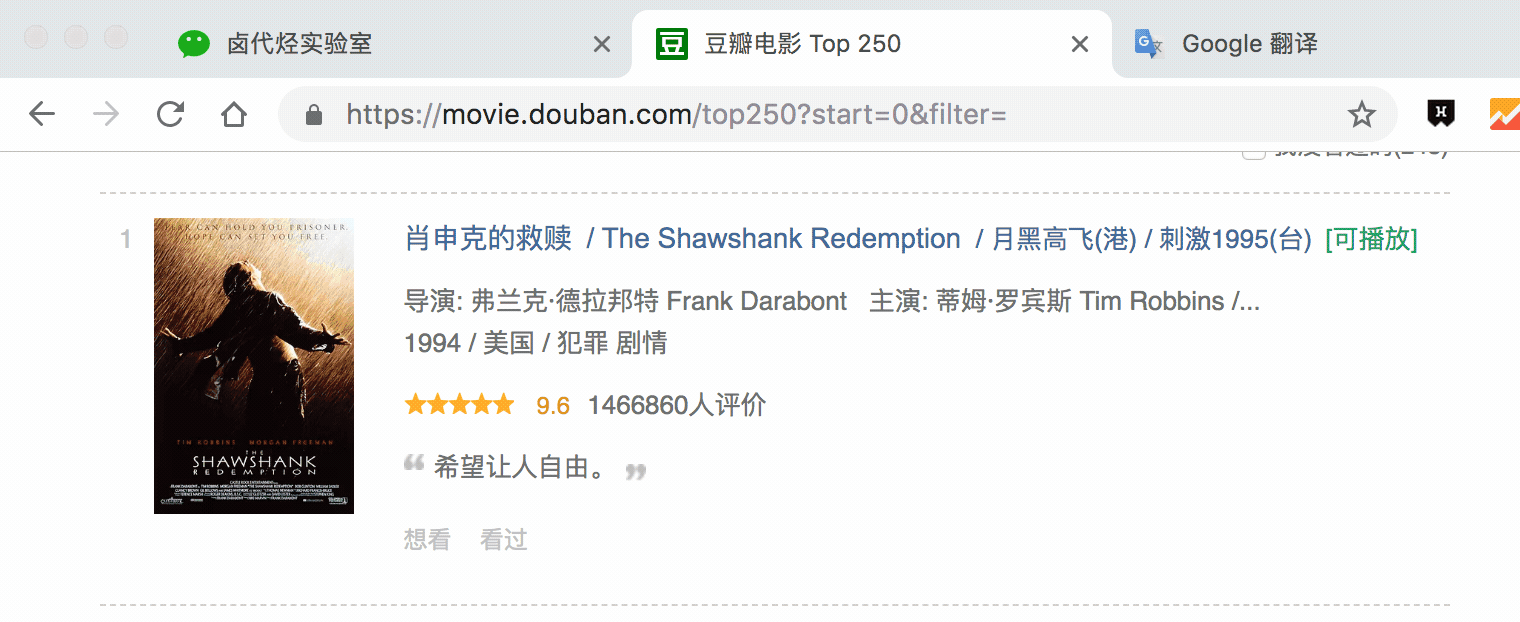
点击 Save selector 保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评,因为操作和上面一模一样,我这里就省略讲解了。
排名编号:

评分:

一句话影评:

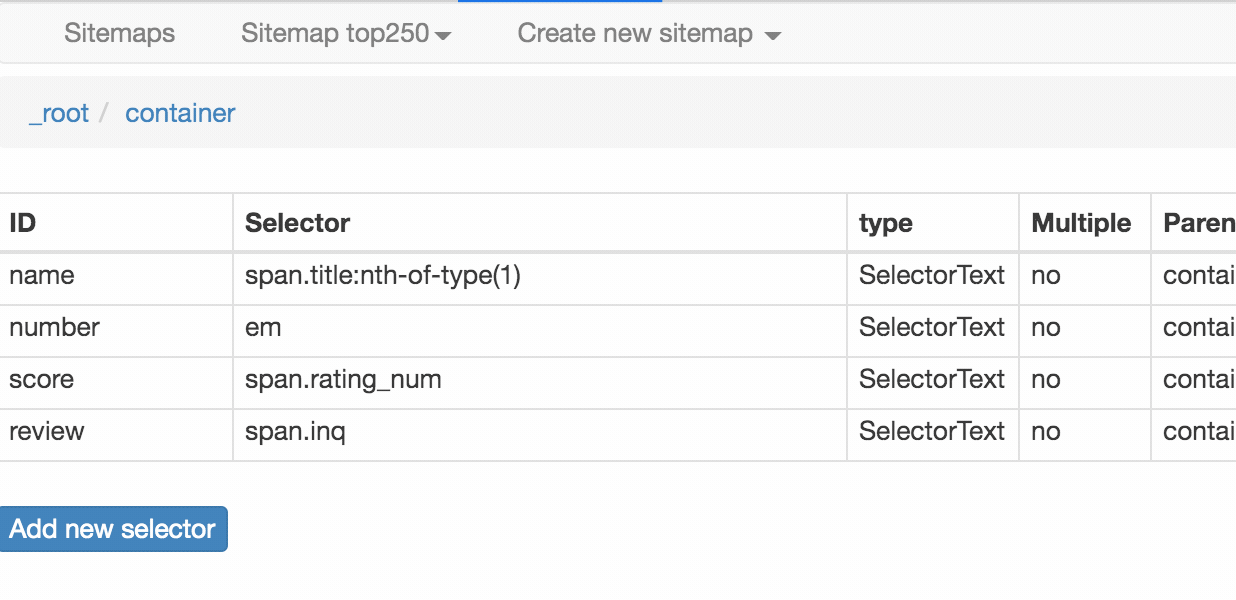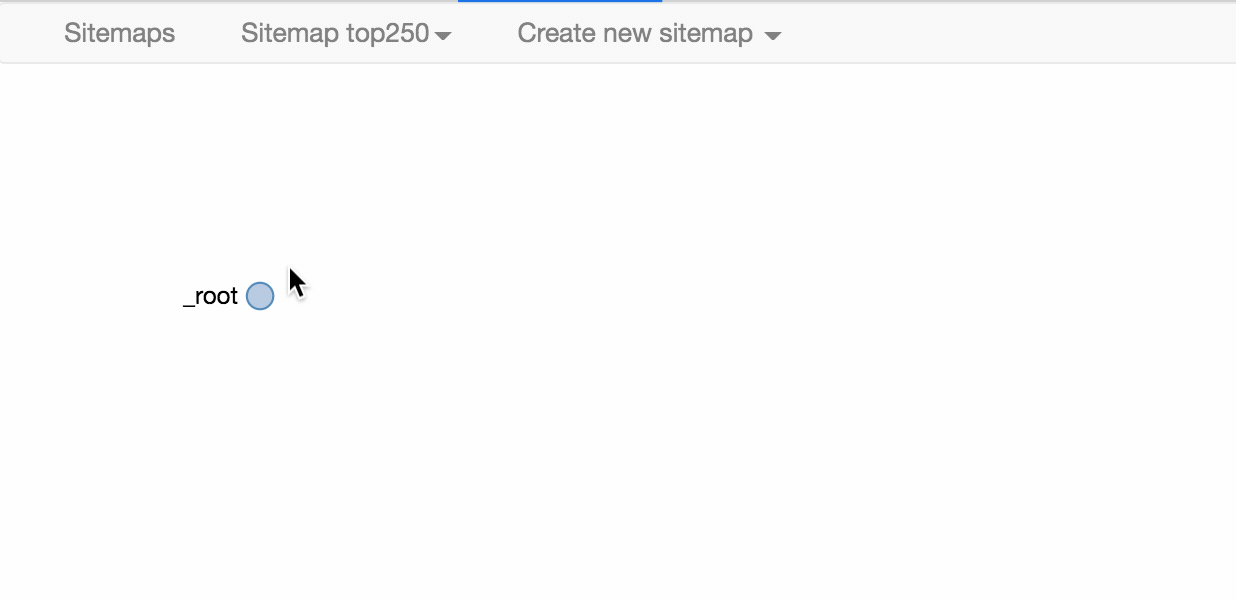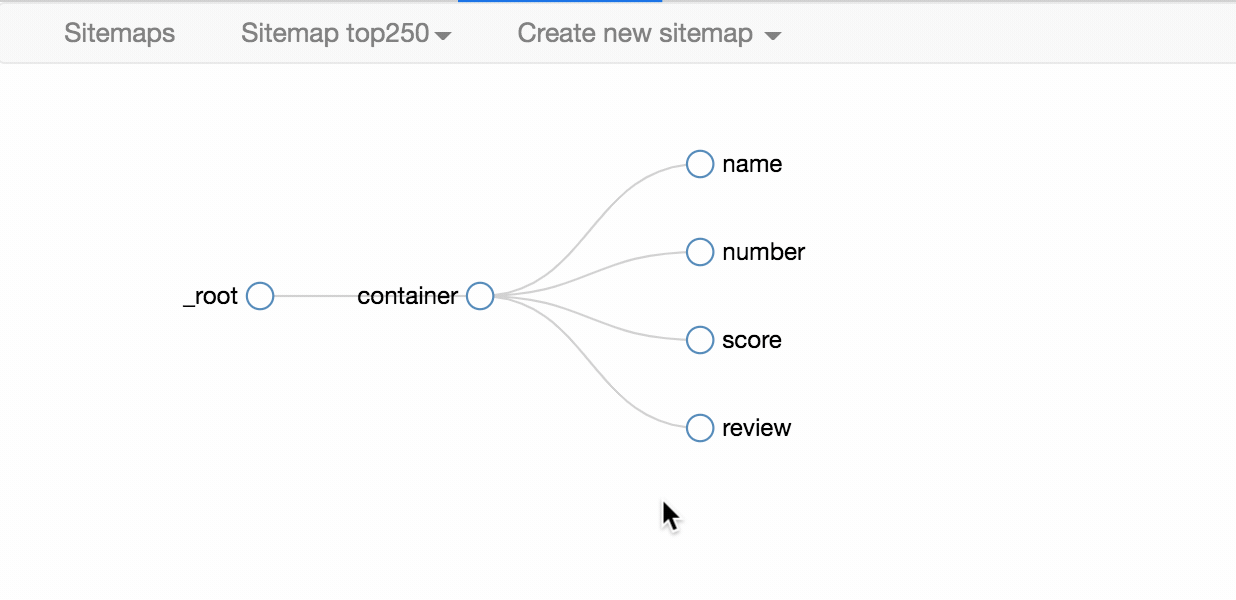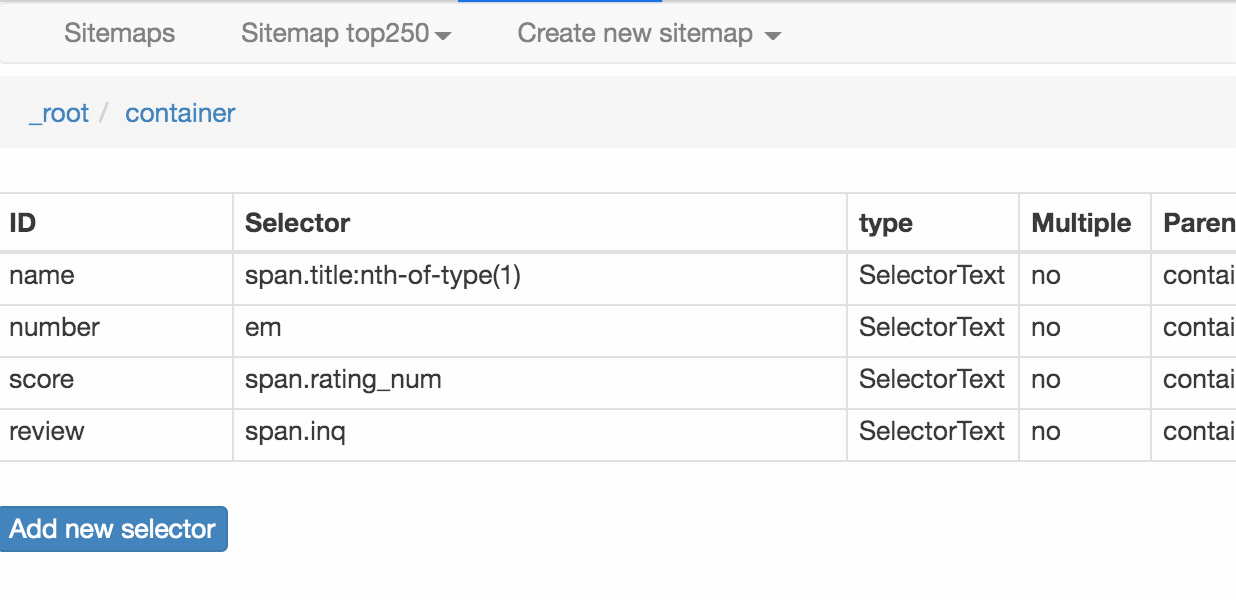
我们可以在面板里观察我们选择的多个元素,一共有四个元素:分别为 name、number、score 和 review,类型都是 Text,不需要多选,父选择器都是 container。

我们可以点击 点击 Stiemap top250 下的 selector graph,查看我们爬虫选择元素的层级关系,确认正确后我们再点击 Stiemap top250 下的 Selectors,回到选择器展示面板。
下图就是我们这次爬虫的层级关系,是不是和我们之前理论分析的一样?

确认选择无误后,我们就可以抓取数据了,操作在 简易数据分析 04 、 简易数据分析 05 里都说过了,忘记的朋友可以看旧文回顾一下。下图是我抓取的数据:

还是和以前一样,数据是乱序的,不过这个不要紧,因为排序属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
今天的内容其实还是比较多的,大家可以先消化一下,下一篇我们讲讲,如何抓取点击「加载更多」加载数据的网页内容。
这次的 sitemap 就分享给大家,大家可以导入到 Web Scraper 中进行实验,具体方法可以看我上一篇教程文章。
Sitemap:
{"_id":"top250","startUrl":["https://movie.douban.com/top250?start=[0-250:25]&filter="],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["container"],"selector":"span.title:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"number","type":"SelectorText","parentSelectors":["container"],"selector":"em","multiple":false,"regex":"","delay":0},{"id":"score","type":"SelectorText","parentSelectors":["container"],"selector":"span.rating_num","multiple":false,"regex":"","delay":0},{"id":"review","type":"SelectorText","parentSelectors":["container"],"selector":"span.inq","multiple":false,"regex":"","delay":0}]}
推荐阅读:
简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
简易数据分析 05 | Web Scraper 翻页——控制链接批量抓取数据

简易数据分析 07 | Web Scraper 抓取多条内容的更多相关文章
- 简易数据分析 11 | Web Scraper 抓取表格数据
这是简易数据分析系列的第 11 篇文章. 今天我们讲讲如何抓取网页表格里的数据.首先我们分析一下,网页里的经典表格是怎么构成的. First Name 所在的行比较特殊,是一个表格的表头,表示信息分类 ...
- 简易数据分析 13 | Web Scraper 抓取二级页面
这是简易数据分析系列的第 13 篇文章. 不知不觉,web scraper 系列教程我已经写了 10 篇了,这 10 篇内容,基本上覆盖了 Web Scraper 大部分功能.今天的内容算这个系列的最 ...
- 简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
这是简易数据分析系列的第 8 篇文章. 我们在Web Scraper 翻页--控制链接批量抓取数据一文中,介绍了控制网页链接批量抓取数据的办法. 但是你在预览一些网站时,会发现随着网页的下拉,你需要点 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器
这是简易数据分析系列的第 9 篇文章. 今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器. 如何只抓取前 100 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- web scraper 抓取数据并做简单数据分析
其实 web scraper 说到底就是那点儿东西,所有的网站都是大同小异,但是都还不同.这也是好多同学总是遇到问题的原因.因为没有统一的模板可用,需要理解了 web scraper 的原理并且对目标 ...
- web scraper 抓取网页数据的几个常见问题
如果你想抓取数据,又懒得写代码了,可以试试 web scraper 抓取数据. 相关文章: 最简单的数据抓取教程,人人都用得上 web scraper 进阶教程,人人都用得上 如果你在使用 web s ...
随机推荐
- 说说IEnumerable和yield
IEnumerable数据类型是我比较喜欢的数据类型,特别是其强类型IEnumerable<T>更获得Linq的支持使得代码看起来更加优雅.整洁. 编写返回值为IEnumerable(或I ...
- python中的变量,字符串,用户交互,if语句
一:python介绍 python的创始人为吉多·范罗苏姆,创始时间是1989年. 1python是一门什么样的语言 python是一门解释型弱类型语言★ 弱类型:弱类型的变量可以变,强类型的变量不能 ...
- UTM (Urchin Tracking Module) codes
UTM Codes are a great way to see the results of your offline marketing In today’s day and age, we ar ...
- c#两种方式调用google地球,调用COM API以及调用GEPLUGIN 与js交互,加载kml文件,dae文件。将二维高德地图覆盖到到三维谷歌地球表面。
网络上资源很多不全面,自己在开发的时候走了不少弯路,在这里整理了最全面的google全套开发,COM交互,web端交互.封装好了各种模块功能. 直接就可以调用. 第一种方式:调用COMAPI实现调用g ...
- Google Earth Engine城市水体提取
Google Earth Engine城市水体提取 大家都知道城市水体提取相比较于山区,丘陵的地区,肯定是比较难的,为什么呢,因为城市水体有很多高层建筑导致的阴影,这个就非常复杂了,而且现在很多高分影 ...
- idea创建类报错
创建类报错: 在idea.exe.vmoptions 或 idea64.exe.vmoptions中加入配置 -Djdk.util.zip.ensureTrailingSlash=false jar包 ...
- git的基本指令
更多详情请看廖雪峰官方网站 http://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000 1.删 ...
- OSI参考模型---网络基础篇(1)
什么是网络 网络就是将分布在不同地理位置,具有独立功能的终端(一切联网的设备都叫终端:例如电脑,手机,智能家电等等联网的设备),通过通信线路(双绞线.光纤.电话线等等)和通信设备(例如:交换机.路由器 ...
- PHP中var_dump、&&和GLOBALS的爱恨纠缠
var_dump函数:用来打印显示一个变量的内容与结构: &&:定义一个可变变量.php中,在定义变量时,需要在前面加上一个“&”符号,当加上两个“&&”符号时 ...
- QT 资料收集 (不定期添加)
Qt之界面实现技巧 http://blog.sina.com.cn/s/blog_a6fb6cc90101dech.html