R语言绘制KS曲线
更多大数据分析、建模等内容请关注公众号《bigdatamodeling》
将代码封装在函数PlotKS_N里,Pred_Var是预测结果,可以是评分或概率形式;labels_Var是好坏标签,取值为1或0,1代表坏客户,0代表好客户;descending用于控制数据按违约概率降序排列,如果Pred_Var是评分,则descending=0,如果Pred_Var是概率形式,则descending=1;N表示在将数据按风险降序排列后,等分N份后计算KS值。
PlotKS_N函数返回的结果为一列表,列表中的元素依次为KS最大值、KS取最大值的人数百分位置、KS曲线对象、KS数据框。
代码如下:
1 #################### PlotKS_N ################################
2 PlotKS_N<-function(Pred_Var, labels_Var, descending, N){
3 # Pred_Var is prop: descending=1
4 # Pred_Var is score: descending=0
5 library(dplyr)
6
7 df<- data.frame(Pred=Pred_Var, labels=labels_Var)
8
9 if (descending==1){
10 df1<-arrange(df, desc(Pred), labels)
11 }else if (descending==0){
12 df1<-arrange(df, Pred, labels)
13 }
14
15 df1$good1<-ifelse(df1$labels==0,1,0)
16 df1$bad1<-ifelse(df1$labels==1,1,0)
17 df1$cum_good1<-cumsum(df1$good1)
18 df1$cum_bad1<-cumsum(df1$bad1)
19 df1$rate_good1<-df1$cum_good1/sum(df1$good1)
20 df1$rate_bad1<-df1$cum_bad1/sum(df1$bad1)
21
22 if (descending==1){
23 df2<-arrange(df, desc(Pred), desc(labels))
24 }else if (descending==0){
25 df2<-arrange(df, Pred, desc(labels))
26 }
27
28 df2$good2<-ifelse(df2$labels==0,1,0)
29 df2$bad2<-ifelse(df2$labels==1,1,0)
30 df2$cum_good2<-cumsum(df2$good2)
31 df2$cum_bad2<-cumsum(df2$bad2)
32 df2$rate_good2<-df2$cum_good2/sum(df2$good2)
33 df2$rate_bad2<-df2$cum_bad2/sum(df2$bad2)
34
35 rate_good<-(df1$rate_good1+df2$rate_good2)/2
36 rate_bad<-(df1$rate_bad1+df2$rate_bad2)/2
37 df_ks<-data.frame(rate_good,rate_bad)
38
39 df_ks$KS<-df_ks$rate_bad-df_ks$rate_good
40
41 L<- nrow(df_ks)
42 if (N>L) N<- L
43 df_ks$tile<- 1:L
44 qus<- quantile(1:L, probs = seq(0,1, 1/N))[-1]
45 qus<- ceiling(qus)
46 df_ks<- df_ks[df_ks$tile%in%qus,]
47 df_ks$tile<- df_ks$tile/L
48 df_0<-data.frame(rate_good=0,rate_bad=0,KS=0,tile=0)
49 df_ks<-rbind(df_0, df_ks)
50
51 M_KS<-max(df_ks$KS)
52 Pop<-df_ks$tile[which(df_ks$KS==M_KS)]
53 M_good<-df_ks$rate_good[which(df_ks$KS==M_KS)]
54 M_bad<-df_ks$rate_bad[which(df_ks$KS==M_KS)]
55
56 library(ggplot2)
57 PlotKS<-ggplot(df_ks)+
58 geom_line(aes(tile,rate_bad),colour="red2",size=1.2)+
59 geom_line(aes(tile,rate_good),colour="blue3",size=1.2)+
60 geom_line(aes(tile,KS),colour="forestgreen",size=1.2)+
61
62 geom_vline(xintercept=Pop,linetype=2,colour="gray",size=0.6)+
63 geom_hline(yintercept=M_KS,linetype=2,colour="forestgreen",size=0.6)+
64 geom_hline(yintercept=M_good,linetype=2,colour="blue3",size=0.6)+
65 geom_hline(yintercept=M_bad,linetype=2,colour="red2",size=0.6)+
66
67 annotate("text", x = 0.5, y = 1.05, label=paste("KS=", round(M_KS, 4), "at Pop=", round(Pop, 4)), size=4, alpha=0.8)+
68
69 scale_x_continuous(breaks=seq(0,1,.2))+
70 scale_y_continuous(breaks=seq(0,1,.2))+
71
72 xlab("of Total Population")+
73 ylab("of Total Bad/Good")+
74
75 ggtitle(label="KS - Chart")+
76
77 theme_bw()+
78
79 theme(
80 plot.title=element_text(colour="gray24",size=12,face="bold"),
81 plot.background = element_rect(fill = "gray90"),
82 axis.title=element_text(size=10),
83 axis.text=element_text(colour="gray35")
84 )
85
86 result<-list(M_KS=M_KS,Pop=Pop,PlotKS=PlotKS,df_ks=df_ks)
87 return(result)
88 }
接下来以实际数据为例查看该函数的运行结果。
pred_train是建模得到的预测结果,这里是概率形式:
> pred_train
[1] 0.40418112 0.35814193 0.45220572 0.53482002 0.12923573 ...
labels_train是好坏标签:
> labels_train
[1] 0 0 0 0 0 ...
函数运行的结果存放在train_ks里:
train_ks<-PlotKS_N(pred_train, labels_train, 1, 100)
我们来查看train_ks中的每一元素:
1、KS最大值
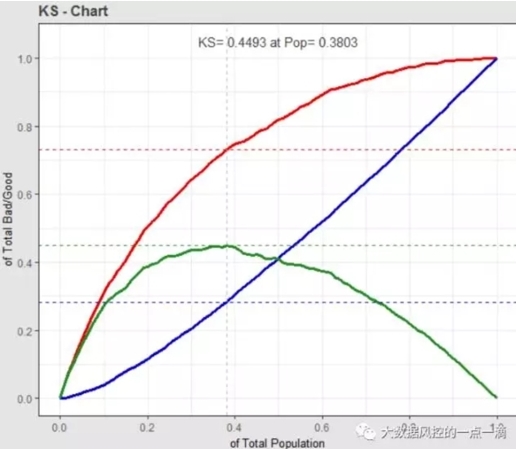
> train_ks$M_KS
[1] 0.4492765
2、KS取最大值的人数百分位置
> train_ks$Pop
[1] 0.3803191
3、KS曲线对象
R语言绘制KS曲线的更多相关文章
- Python绘制KS曲线
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> python实现KS曲线,相关使用方法请参考上篇博客-R语言实现KS曲线 代码如下: ############## ...
- R语言绘制相对性关系图
准备 第一步就是安装R语言环境以及RStudio 图绘制准备 首先安装库文件,敲入指令,回车 install.packages('corrplot') 然后安装excel导入的插件,点击右上角impo ...
- 一幅图解决R语言绘制图例的各种问题
一幅图解决R语言绘制图例的各种问题 用R语言画图的小伙伴们有木有这样的感受,"命令写的很完整,运行没有报错,可图例藏哪去了?""图画的很美,怎么总是图例不协调?" ...
- R语言绘制空间热力图
先上图 R语言的REmap包拥有非常强大的空间热力图以及空间迁移图功能,里面内置了国内外诸多城市坐标数据,使用起来方便快捷. 开始 首先安装相关包 install_packages("dev ...
- R语言绘制花瓣图flower plot
R语言中有很多现成的R包,可以绘制venn图,但是最多支持5组,当组别数大于5时,venn图即使能够画出来,看上去也非常复杂,不够直观: 在实际的数据分析中,组别大于5的情况还是经常遇到的,这是就可以 ...
- R语言绘制沈阳地铁线路图
##使用leaflet绘制地铁线路图,要求 ##(1)图中绘制地铁线路 library(dplyr) library(leaflet) library(data.table) stations< ...
- R语言绘制QQ图
无论是直方图还是经验分布图,要从比较上鉴别样本是否处近似于某种类型的分布是困难的 QQ图可以帮我们鉴别样本的分布是否近似于某种类型的分布 R语言,代码如下: > qqnorm(w);qqline ...
- R语言绘制直方图,
直方图: 核密度函数: 练习题目1: 绘制出15位同学体重的直方图和核密度估计图,并与正态分布的概率密度函数作对比 代码如下: > w <- c(75.0, 64.0, 47.4, 66. ...
- R语言绘制正太分布图,并进行正太分布检验
正态分布 判断一样本所代表的背景总体与理论正态分布是否没有显著差异的检验. 方法一概率密度曲线比较法 看样本与正太分布概率密度曲线的拟合程度,R代码如下: #画样本概率密度图s-rnorm(100 ...
随机推荐
- Java自动生成数据
最近在造数据库中的表数据,写了些数据生成类 可以随机生成姓名.性别,民族,出生日期,身份证号,手机号,邮箱,身高,文化程度,地址,单位,日期时间,编码等 package com.util.create ...
- asp.net core 自定义 Policy 替换 AllowAnonymous 的行为
asp.net core 自定义 Policy 替换 AllowAnonymous 的行为 Intro 最近对我们的服务进行了改造,原本内部服务在内部可以匿名调用,现在增加了限制,通过 identit ...
- Mybatis加入日志
*在mybatis-config.xml核心配置文件中加入如下设置,在configration中标签中加入 <!--打印日志,方便看输出SQL --> <settings> & ...
- ssm 不能将查询的结果返回到界面的一个原因
* 在controller类中,应先定义一个ArrayList的集合即就是: List<Product> defaultProductList = new ArrayList(); // ...
- CentOS 7安装图形界面步骤和问题解决方法
CentOS 7图形安装步骤: 首先需要进行必要的图形组件安装--命令为: yum groupinstall "X Window System " yum groupinstall ...
- oracle:表重命名
SQL> rename test1 to test; Table renamed. SQL> alter table test rename to test1; Table altered ...
- vue-cli从2升级到3报错error 404 Not Found: @wry/context@^0.4.0
vue3出来了,想尝尝鲜. 于是按官方的方法卸载2安装3. npm uninstall vue-cli -g npm install -g @vue/cli 但是报错了 error 404 Not F ...
- Vue——watch监听对象,监听嵌套多次的对象属性
首先是watch 然后是methods
- 为什么 Redis 是单线程的?
以前一直有个误区,以为:高性能服务器 一定是 多线程来实现的 原因很简单因为误区二导致的:多线程 一定比 单线程 效率高.其实不然. 在说这个事前希望大家都能对 CPU . 内存 . 硬盘的速度都有了 ...
- golang实现rabbitmq消息队列失败尝试
在工作中发现,有些时候消息因为某些原因在消费一次后,如果消息失败,这时候不ack,消息就回一直重回队列首部,造成消息拥堵. 如是有了如下思路: 消息进入队列前,header默认有参数 retry_nu ...