100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」?
1、k均值聚类模型
给定样本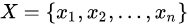 ,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类。用C表示划分,他是一个多对一的函数,k均值聚类就是一个从样本到类的函数。
,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类。用C表示划分,他是一个多对一的函数,k均值聚类就是一个从样本到类的函数。
2、k均值聚类策略
k均值聚类的策略是通过损失函数最小化选取最优的划分或函数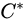 。
。
首先,计算样本之间的距离,这里选欧氏距离平方。
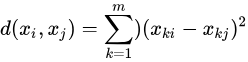
然后定义样本与其所属类的中心之间的距离的总和为损失函数
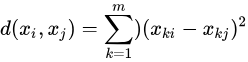
其中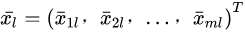 为第l个类的均值或中心
为第l个类的均值或中心
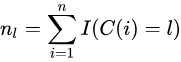
,是指示函数,取值1或0.
k均值聚类就是求解最优化问题:

3、k均值聚类算法
k均值聚类的算法是一个迭代过程,
首先:
对于给定中心值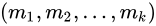 ,求划分C,是目标函数极小化:
,求划分C,是目标函数极小化:
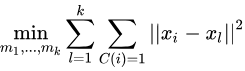
即,类中心确定的情况下,将样本分到一个类中,使样本和其所属类的中心之间的距离总和最小。
然后:
对于给定的划分C,再求各个类的中心,是目标函数极小化。
即,划分C确定的情况下,使样本和其所属类的中心之间的距离总和最小。求解结果,对于每个包含nl个样本的类Gi,更新其均值ml:
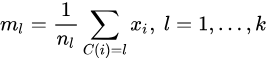
重复以上两个步骤,知道分化不在改变。
from myUtil import *
def kMeans(dataSet, k):
m = shape(dataSet)[0] # 返回矩阵的行数
# 本算法核心数据结构:行数与数据集相同
# 列1:数据集对应的聚类中心,列2:数据集行向量到聚类中心的距离
ClustDist = mat(zeros((m, 2)))
# 随机生成一个数据集的聚类中心:本例为4*2的矩阵
# 确保该聚类中心位于min(dataSet[:,j]),max(dataSet[:,j])之间
clustercents = randCenters(dataSet, k) # 随机生成聚类中心
flag = True # 初始化标志位,迭代开始
counter = [] # 计数器
# 循环迭代直至终止条件为False
# 算法停止的条件:dataSet的所有向量都能找到某个聚类中心,到此中心的距离均小于其他k-1个中心的距离
while flag:
flag = False # 预置标志位为False
# ---- 1. 构建ClustDist:遍历DataSet数据集,计算DataSet每行与聚类的最小欧式距离 ----#
# 将此结果赋值ClustDist=[minIndex,minDist]
for i in xrange(m):
# 遍历k个聚类中心,获取最短距离
distlist = [distEclud(clustercents[j, :], dataSet[i, :]) for j in range(k)]
minDist = min(distlist)
minIndex = distlist.index(minDist)
if ClustDist[i, 0] != minIndex: # 找到了一个新聚类中心
flag = True # 重置标志位为True,继续迭代
# 将minIndex和minDist**2赋予ClustDist第i行
# 含义是数据集i行对应的聚类中心为minIndex,最短距离为minDist
ClustDist[i, :] = minIndex, minDist
# ---- 2.如果执行到此处,说明还有需要更新clustercents值: 循环变量为cent(0~k-1)----#
# 1.用聚类中心cent切分为ClustDist,返回dataSet的行索引
# 并以此从dataSet中提取对应的行向量构成新的ptsInClust
# 计算分隔后ptsInClust各列的均值,以此更新聚类中心clustercents的各项值
for cent in xrange(k):
# 从ClustDist的第一列中筛选出等于cent值的行下标
dInx = nonzero(ClustDist[:, 0].A == cent)[0]
# 从dataSet中提取行下标==dInx构成一个新数据集
ptsInClust = dataSet[dInx]
# 计算ptsInClust各列的均值: mean(ptsInClust, axis=0):axis=0 按列计算
clustercents[cent, :] = mean(ptsInClust, axis=0)
return clustercents, ClustDist
参考:
https://jakevdp.github.io/PythonDataScienceHandbook
https://www.cnblogs.com/eczhou/p/7860424.html
统计学习方法14.3

100天搞定机器学习|day44 k均值聚类数学推导与python实现的更多相关文章
- 100天搞定机器学习|Day8 逻辑回归的数学原理
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|day54 聚类系列:层次聚类原理及案例
几张GIF理解K-均值聚类原理 k均值聚类数学推导与python实现 前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使每个样本与其所属类的中心或均值最近. 今天我们看一下无监 ...
- 100天搞定机器学习|Day11 实现KNN
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- 100天搞定机器学习|Day22 机器为什么能学习?
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day9-12 支持向量机
机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机器学习|D ...
- 100天搞定机器学习|Day17-18 神奇的逻辑回归
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 100天搞定机器学习|Day21 Beautiful Soup
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
随机推荐
- .net持续集成sonarqube篇之sonarqube安装与基本配置
系列目录 Sonarqube下载与安装 Sonarqube下载地址是:https://www.sonarqube.org/downloads/下载版本有两个,一个是长期支持版,另一个是最新版,此处安装 ...
- 前端响应式痛点解决之box-sizing
前置 在 CSS 盒子模型的默认定义里,你对一个元素所设置的 width 与 height 只会应用到这个元素的内容区.如果这个元素有任何的 border 或 padding ,绘制到屏幕上时的盒子宽 ...
- ArcGIS API For JavaScript 开发(一)环境搭建
标签:B/S结构开发,Asp.Net开发,WebGIS开发 前言:为什么写这个,一是学习:二是分享,共同进步,毕竟也是在这个园子里学到了很多: (一)环境搭建 集成开发环境:VS2013 Ultima ...
- SSM框架实现原理图(转)
- 从深处去掌握数据校验@Valid的作用(级联校验)
每篇一句 NBA里有两大笑话:一是科比没天赋,二是詹姆斯没技术 相关阅读 [小家Java]深入了解数据校验:Java Bean Validation 2.0(JSR303.JSR349.JSR380) ...
- 【iOS】the executable was signed with invalid entitlements
又遇到了这个问题,貌似之前遇到过,如图所示: 原因:开发证书里没添加手机. PS: Xcode7 除外,据说已经不需要证书了,这里用的是 6.4
- 拉格朗日对偶性(Lagrange duality)
目录 拉格朗日对偶性(Lagrange duality) 1. 从原始问题到对偶问题 2. 弱对偶与强对偶 3. KKT条件 Reference: 拉格朗日对偶性(Lagrange duality) ...
- Linux下,为应用程序添加桌面图标(ubuntu18.4)
一.桌面图标位置 Lniux下桌面图标储存路径为:/usr/share/applications 二.桌面图标格式 所有桌面图标格式均为desktop,即名为XXX.desktop 三.编辑内容(常用 ...
- js 双向绑定数据
let aaa = []; let bbb = [1,2,3]; let ccc = [0,9,8]; aaa = bbb; //此时aaa与bbb被绑定(aaa指向bbb的指向) ,若使用push则 ...
- Unity学习--捕鱼达人笔记
1.2D模式和3D模式的区别,2D模式默认的摄像机的模式是Orthographic(正交摄像机),3D模式默认的摄像机的模式是Perspective(透视摄像机).3D会额外给你一个平衡光.3D模式修 ...