python爬虫-模拟微博登录
微博模拟登录
这是本次爬取的网址:https://weibo.com/
一、请求分析
找到登录的位置,填写用户名密码进行登录操作
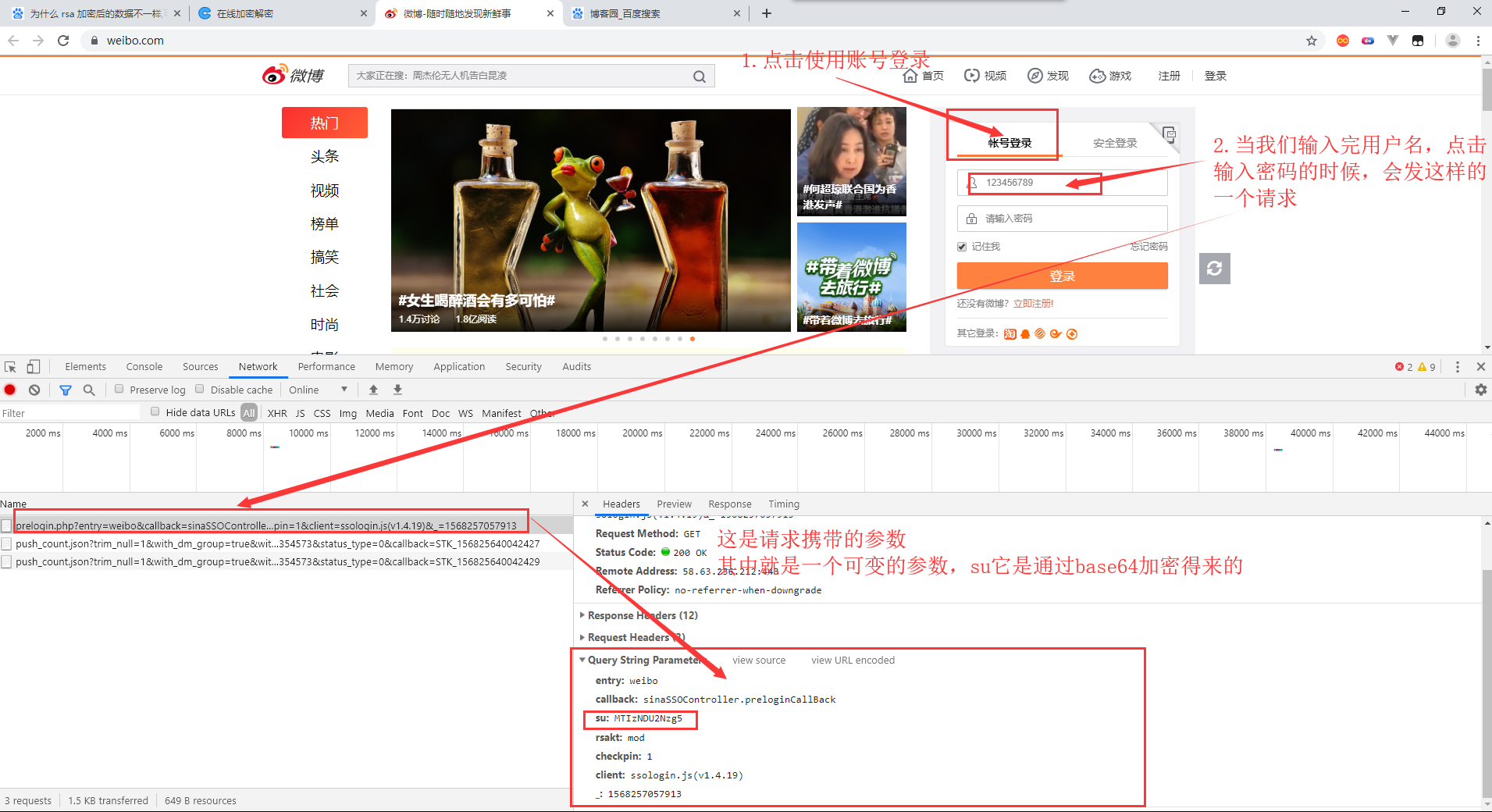
看看这次请求响应的数据是什么
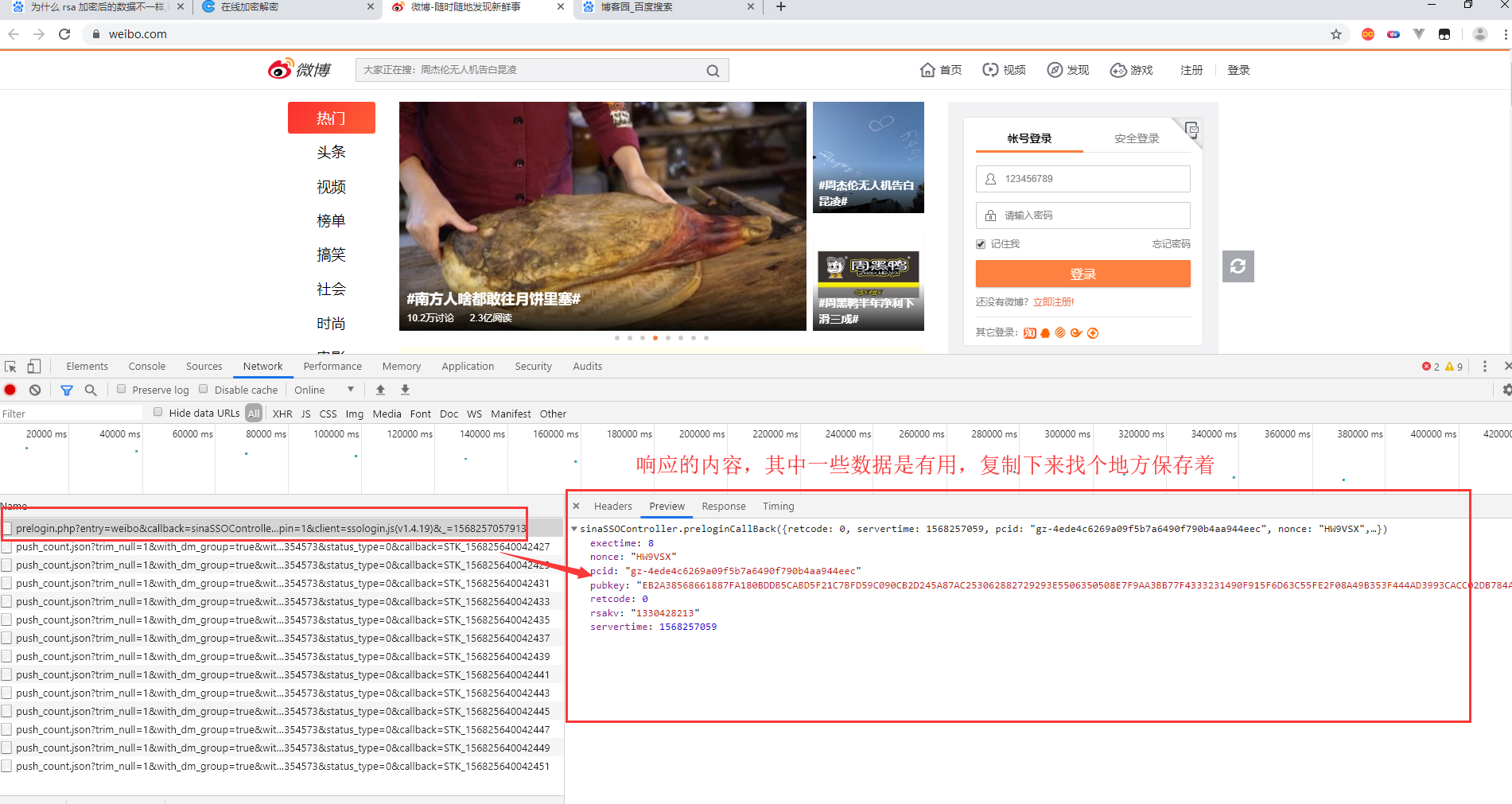
这是响应得到的数据,保存下来
exectime: 8
nonce: "HW9VSX"
pcid: "gz-4ede4c6269a09f5b7a6490f790b4aa944eec"
pubkey: "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443"
retcode: 0
rsakv: "1330428213"
servertime: 1568257059
继续完善登录操作,输入密码,点击登录按钮

经过分析呢,发现变化的参数就是sp,nonce,servetime。servetime就是当前的时间戳,我们只需找到其他两个参数的生成方法就好了。对了su这个参数是通过base64加密生成的
二、找到sp,nonce的加密方式
这次就不通过search关键字去找加密位置了
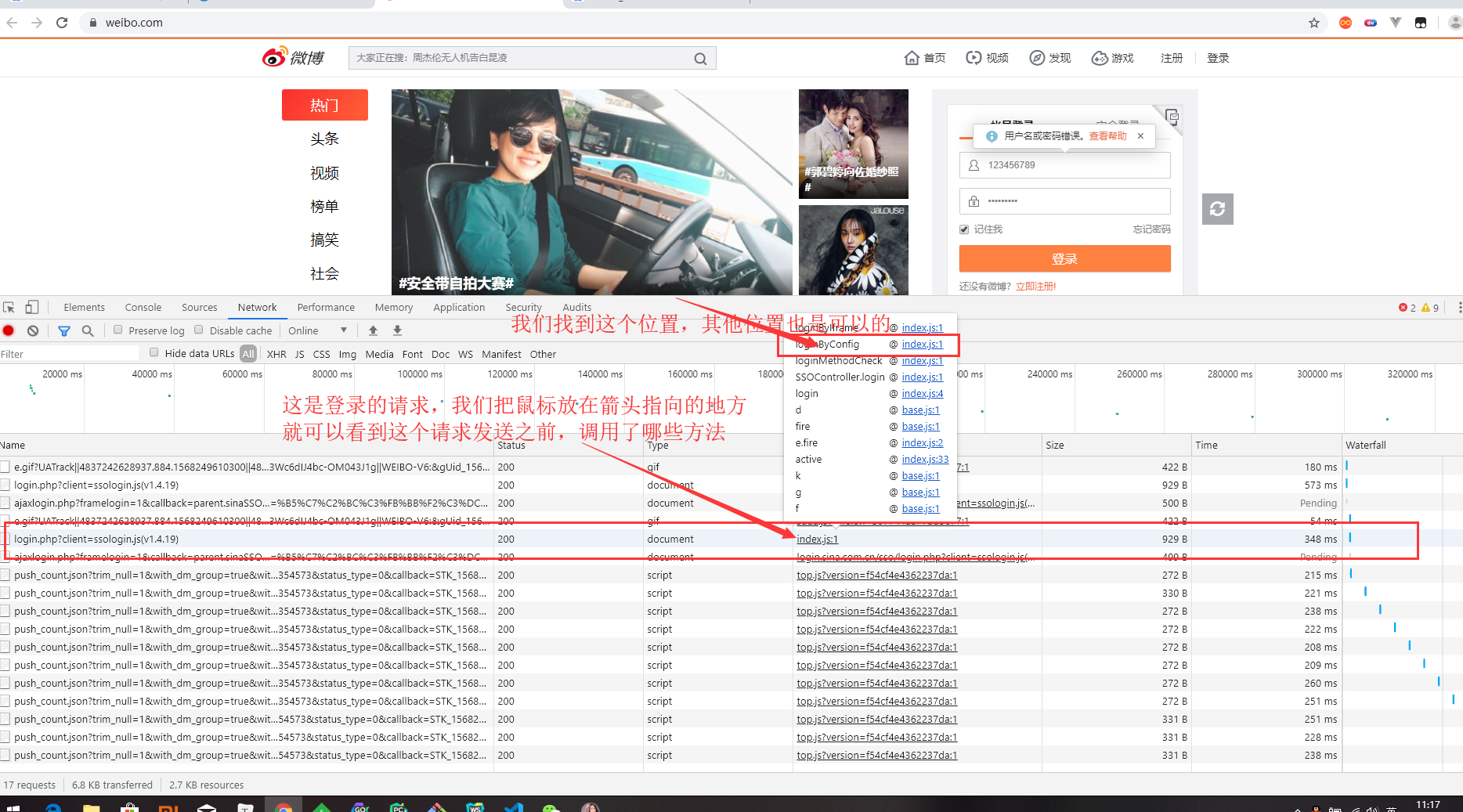
找到调用函数的位置,打上断点,再进行登录操作

经过js代码流程调试分析,最终我们找到了加密的位置
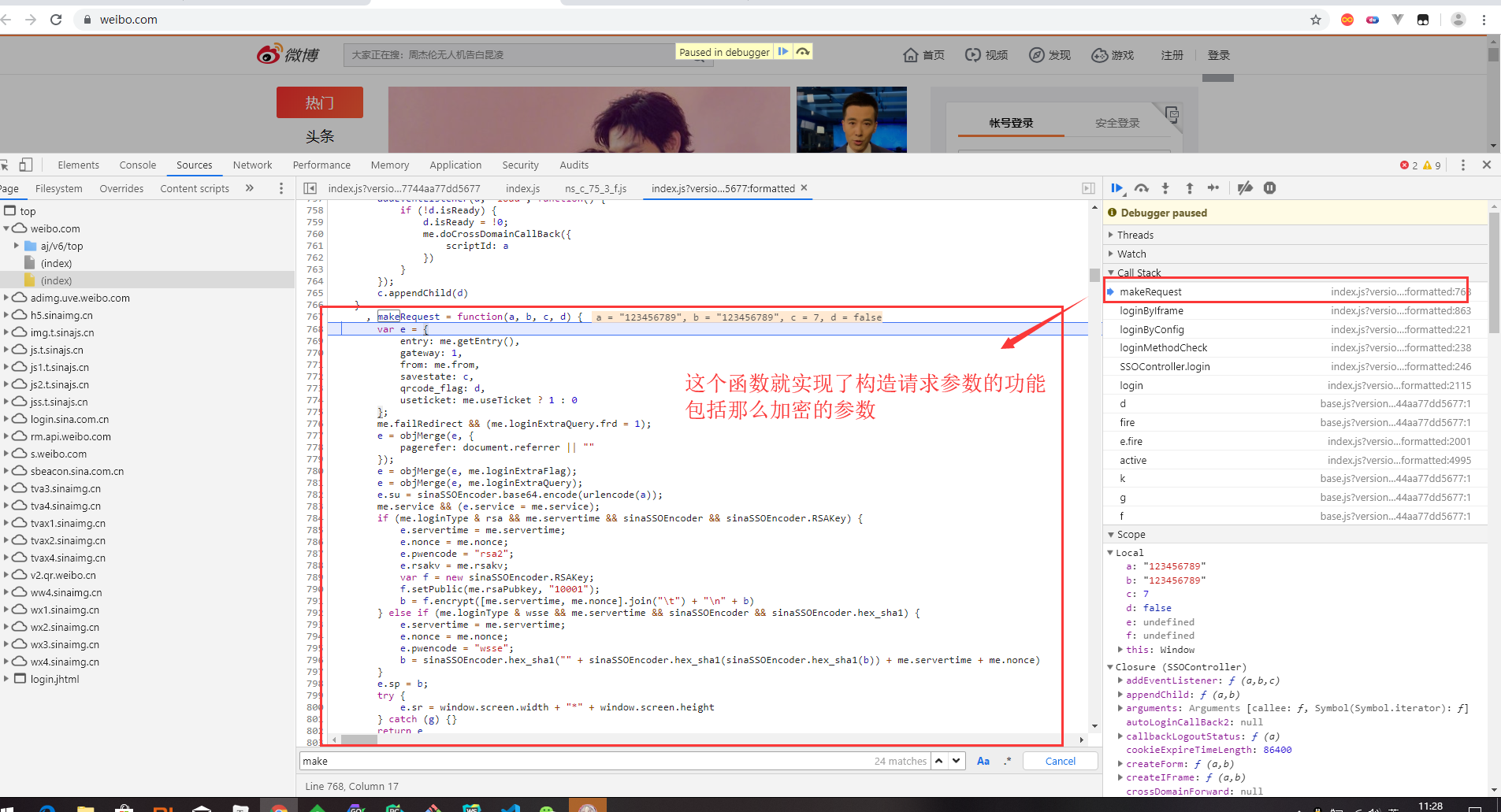
简单介绍下怎么调试js代码

找到sp,nonce的位置,通过python代码去实现它的加密方式
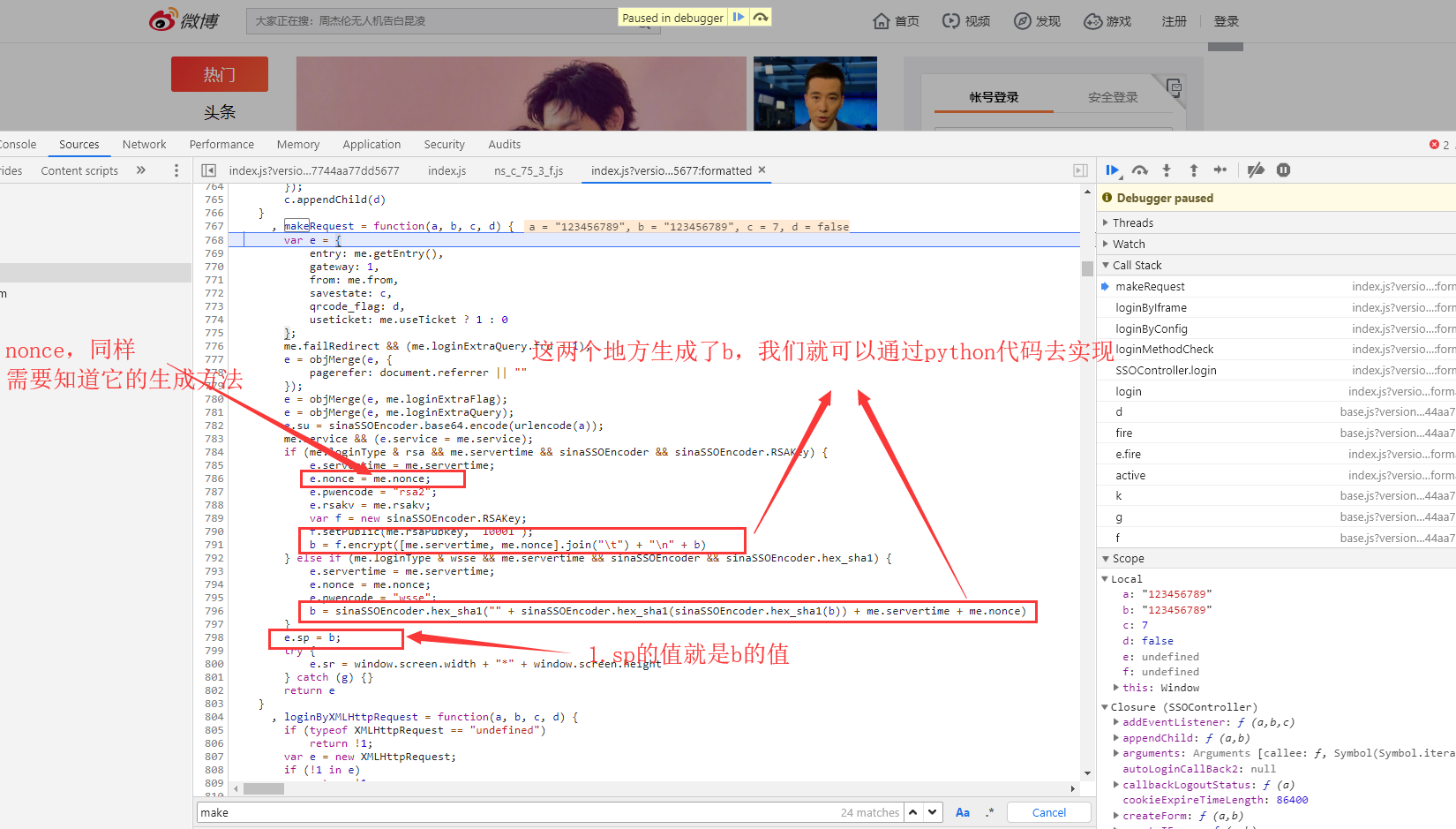
sp它是通过rsa加密方式,加密生成的。rsa的具体用法可以通过百度找到。或者通过sha1加密生成。至于me.rsaPubkey他怎么得到的,他就是我们还没有点击登录前,就发了一个请求,那个请求的响应数据就有它。如果你测试的次数多了的话,会发现这个值它是固定下来的。所以我们也可以直接去用,不用请求获取。
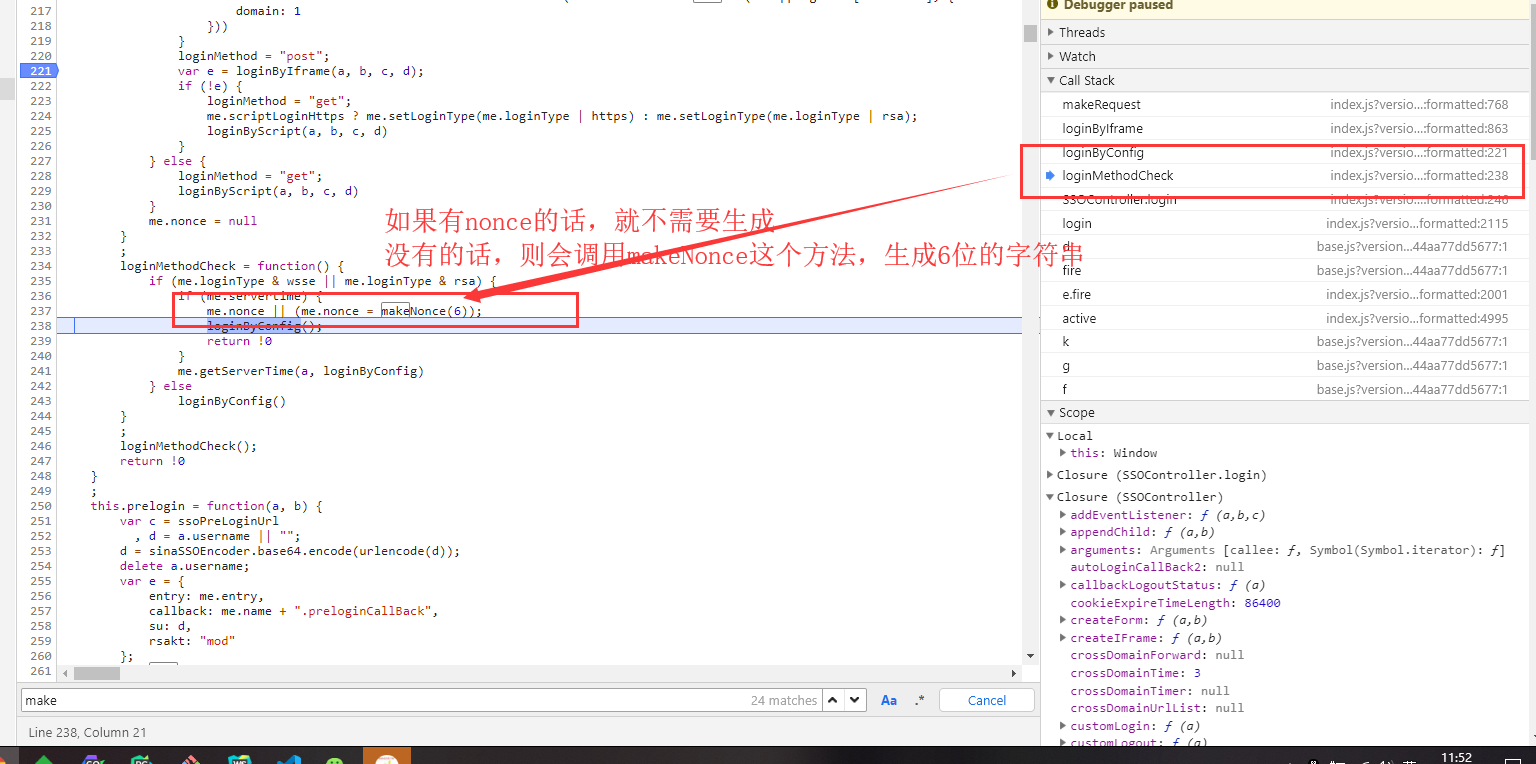
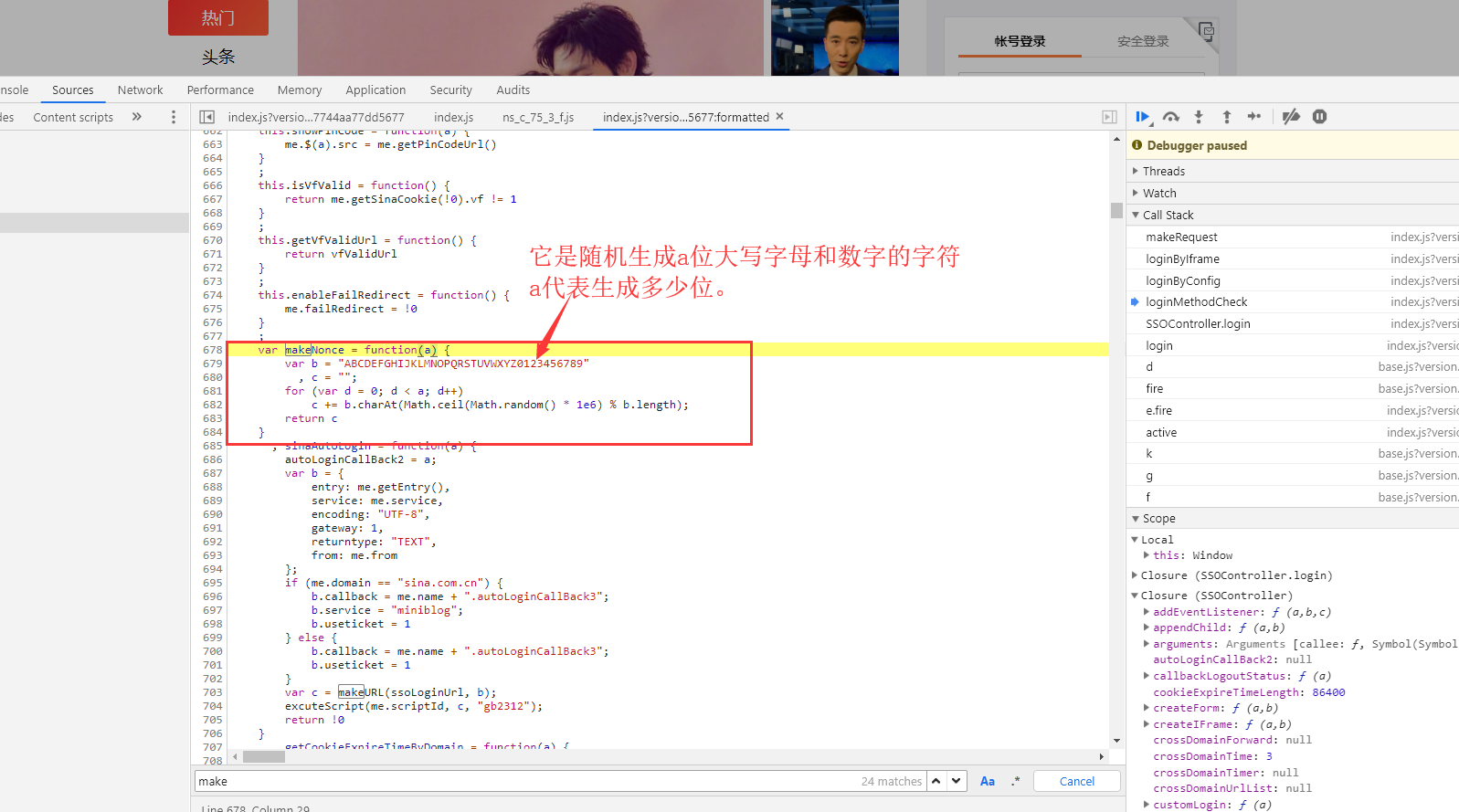
nonce:它呢也出现过在未点击登录前的那个请求响应的数据中,但是呢,我们点了几次登录,都未发现这个请求了。nonce的值每次还不一样。所以它肯定是本地js文件的某个函数生成,不用请求服务器获取。我们在这里找到了nonce的生成函数
import random
import rsa
import hashlib
from binascii import b2a_hex
def get_nonce(n):
result = ""
random_str = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
for i in range(n):
index = random.randint(0, len(random_str) - 1)
result += random_str[index]
return result
def get_sp_rsa(password, servertime, nonce):
key = "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443"
pubkey = rsa.PublicKey(int(key, 16), int("10001", 16))
res = rsa.encrypt(bytes("" + "\t".join([servertime, nonce]) + "\n" + password,encoding="utf-8"), pubkey)
return b2a_hex(res)
def get_sp_sha1(password, servertime, nonce):
res = hashlib.sha1(bytes("" + hashlib.sha1(bytes(hashlib.sha1(bytes(password, encoding="utf-8")).hexdigest(),encoding="utf-8")).hexdigest() + servertime + nonce,encoding="utf-8")).hexdigest()
return res
三、响应数据
请求参数分析的差不多了,这次输入正确的用户名,密码。查看响应的数据的是什么。

打开fiddler,然后退出当前账号,重新进行登录操作。fiddler上面就会出现很多请求。找到需要的请求,看看响应内容
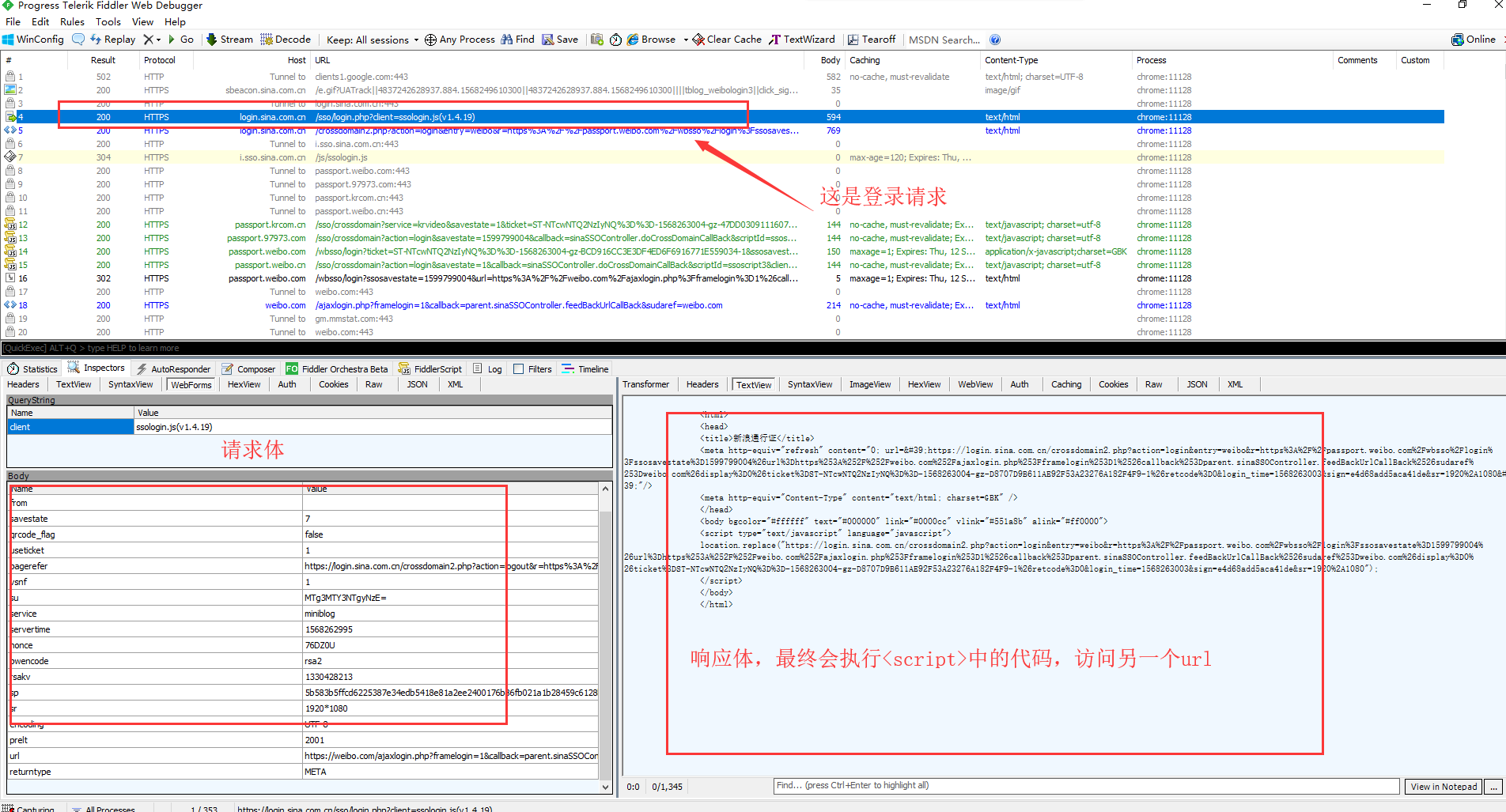
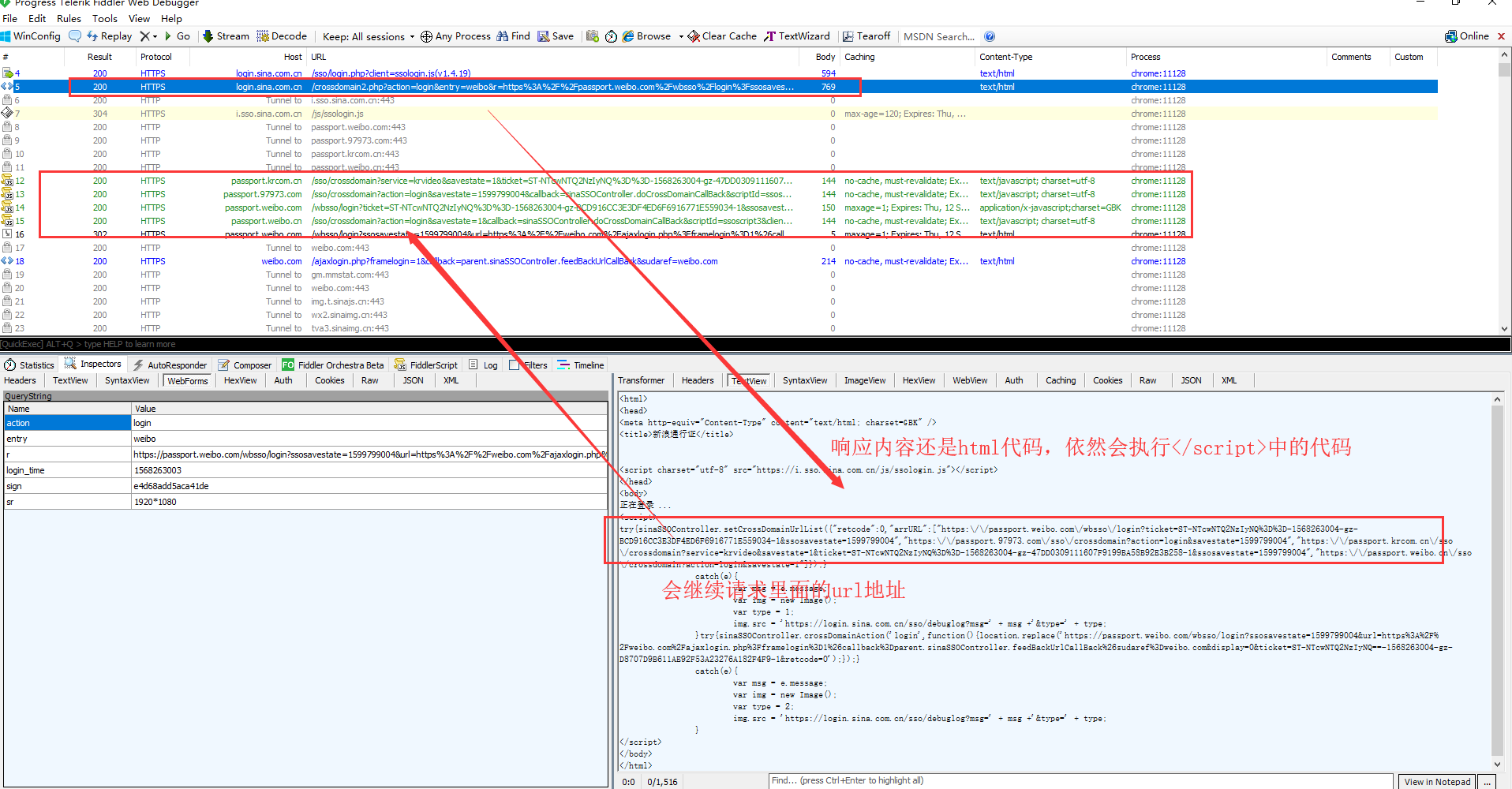
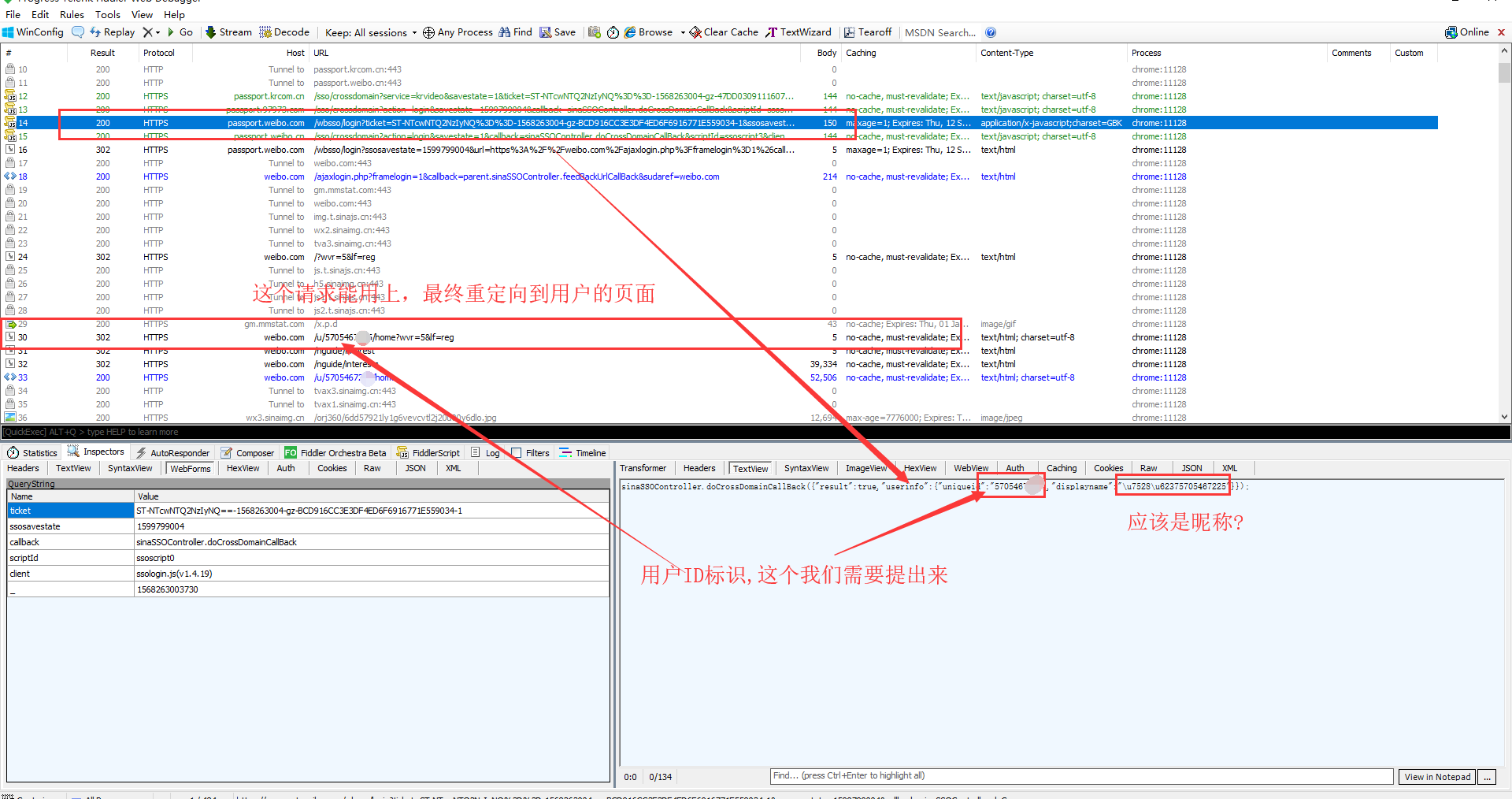
这样做,每个响应都会set-cookie。所以照着上面的流程实现,标识登录的cookie肯定能得到。之后的话,只要带上这个cookie去做其他操作就行了。
最后附上代码
import requests, random, time, rsa, hashlib, base64, re, json
from binascii import b2a_hex
class WeiBo:
def __init__(self):
self.session = requests.Session()
self.headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"
}
def login(self, account, password):
api = "https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19)"
nonce = self._get_nonce()
servertime = self._get_now_time()
sp = self._get_sp_rsa(password, servertime, nonce)
su = self._get_su(account)
data = {
"entry": "weibo",
"gateway": "1",
"from": "",
"savestate": "7",
"qrcode_flag": "false",
"useticket": "1",
"pagerefer": "https://login.sina.com.cn/crossdomain2.php?action=logout&r=https%3A%2F%2Fpassport.weibo.com%2Fwbsso%2Flogout%3Fr%3Dhttps%253A%252F%252Fweibo.com%26returntype%3D1",
"vsnf": "1",
"su": su,
"service": "miniblog",
"servertime": servertime,
"nonce": nonce,
"pwencode": "rsa2",
"rsakv": "1330428213",
"sp": sp,
"sr": "1920*1080",
"encoding": "UTF - 8",
"prelt": "149",
"url": "https://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack",
"returntype": "META",
}
headers = self.headers.copy()
headers.update({
"Host": "login.sina.com.cn",
"Origin": "https://weibo.com",
"Referer": "https://weibo.com/"
})
response = self.session.post(api, headers=headers, data=data, allow_redirects=False)
search_result = self._re_search("location.replace\(\"(.*?)\"", response.text)
redirct_url = search_result and search_result.group(1)
if not redirct_url:
raise Exception("重定向url获取失败")
response = self.session.get(redirct_url, headers=headers.update({
"Referer": "https://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.19)"
}), allow_redirects=False)
search_result = self._re_search('"arrURL":(.*?)}', response.text)
redirct_urls = search_result and search_result.group(1)
if not redirct_urls:
raise Exception("重定向url获取失败")
redirct_url_list = json.loads(redirct_urls)
userId = ""
for url in redirct_url_list:
response = self.session.get(url, headers=self.headers)
if url.startswith("https://passport.weibo.com/wbsso/login"):
userId = self._re_search('"uniqueid":"(.*?)"', response.text).group(1)
if not userId:
raise Exception("userId获取失败")
user_details_url = "https://weibo.com/u/{}/home?wvr=5&lf=reg".format(userId)
response = self.session.get(user_details_url, headers={
"Referer": "https://weibo.com/",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36"
})
if self._re_search(userId, response.text):
print("登录成功")
print(self.session.cookies)
else:
print("登录失败")
def _get_nonce(self):
nonce = ""
random_str = "ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
for i in range(5):
index = random.randint(0, len(random_str) - 1)
nonce += random_str[index]
return nonce
def _get_now_time(self):
return str(int(time.time()))
def _get_sp_rsa(self, password, servertime, nonce):
key = "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443"
pubkey = rsa.PublicKey(int(key, 16), int("10001", 16))
res = rsa.encrypt(bytes("" + "\t".join([servertime, nonce]) + "\n" + password, encoding="utf-8"), pubkey)
return b2a_hex(res)
def _get_sp_sha1(self, password, servertime, nonce):
res = hashlib.sha1(bytes("" + hashlib.sha1(bytes(hashlib.sha1(bytes(password, encoding="utf-8")).hexdigest(),
encoding="utf-8")).hexdigest() + servertime + nonce,
encoding="utf-8")).hexdigest()
return res
def _get_su(self, account):
return str(base64.b64encode(bytes(account, encoding="utf-8")), encoding="utf-8")
def _re_search(self, pattern, html):
return re.search(pattern, html, re.S)
def test(self):
self.login("18716758777", "123456")
if __name__ == '__main__':
wb = WeiBo()
wb.test()
python爬虫-模拟微博登录的更多相关文章
- python爬虫--模拟12306登录
模拟12306登录 超级鹰: #!/usr/bin/env python # coding:utf-8 import requests from hashlib import md5 class Ch ...
- python爬虫模拟登陆
python爬虫模拟登陆 学习了:https://www.cnblogs.com/chenxiaohan/p/7654667.html 用的这个 学习了:https://www.cnblogs.co ...
- python+selenium模拟京东登录后台
python+selenium模拟京东登录后台 import json from time import sleep from selenium import webdriver #from sele ...
- python爬虫模拟登录验证码解决方案
[前言]几天研究验证码解决方案有三种吧.第一.手工输入,即保存图片后然后我们手工输入:第二.使用cookie,必须输入密码一次,获取cookie:第三.图像处理+深度学习方案,研究生也做相关课题,就用 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫之新浪微博登录
fiddler 之前了解了一些常见到的反爬措施,JS加密算是比较困难,而微博的登录中正是用JS加密来反爬,今天来了解一下. 分析过程 首先我们去抓包,从登录到微博首页加载出来的过程.我们重点关注一下登 ...
- 用python连接数据库模拟用户登录
使用pycharm下载pymysql库,在终端输入命令: pip install mysql 使用pycharm写登入操作前需要在数据库内添加一些数据,比如用户名和密码 create database ...
- python爬虫模拟登录的图片验证码处理和会话维持
目标网站:古诗文网 登录界面显示: 打开控制台工具,输入账号密码,在ALL栏目中进行抓包 数据如下: 登录请求的url和请求方式 登录所需参数 参数分析: __VIEWSTATE和__VIEWSTAT ...
- Python爬虫常用之登录(二) 浏览器模拟登录
浏览器模拟登录的主要技术点在于: 1.如何使用python的浏览器操作工具selenium 2.简单看一下网页,找到帐号密码对应的框框,要知道python开启的浏览器如何定位到这些 一.使用selen ...
随机推荐
- Unbutu在VMWare中挂载共享文件夹
第一,安装VMTools,步骤自行搜索,安装成功后重启虚拟机. 第二,重启后,在虚拟机管理页面设置共享目录,选择总是启用,开启虚拟机. 第三,在终端进入挂载目录cd /mnt/hgfs/,通过命令su ...
- Scala集合(四)
1. 集合 集合主要有三种: Sequence Map Set sequence是一种线性元素的集合,可能会是索引或者线性的(链表).map是包含键值对的集合,就像Java的Map,set是包含无重复 ...
- Asp.Net Core WebAPI+PostgreSQL部署在Docker中
PostgreSQL是一个功能强大的开源数据库系统.它支持了大多数的SQL:2008标准的数据类型,包括整型.数值值.布尔型.字节型.字符型.日期型.时间间隔型和时间型,它也支持存储二进制的大对像, ...
- [android视频教程] 传智播客android开发视频教程
本套视频共有67集,是传智播客3G-Android就业班前8天的的课程量.本套视频教程是黎活明老师在2011年底对传智播客原来的Android核心基础课程精心重新录制的,比早期的Android课程内容 ...
- Springboot源码分析之项目结构
Springboot源码分析之项目结构 摘要: 无论是从IDEA还是其他的SDS开发工具亦或是https://start.spring.io/ 进行解压,我们都会得到同样的一个pom.xml文件 4. ...
- set集合的常用方法
set集合是一种无序不重复的集合 add (self, *args, **kwargs) ...
- Yarn上常驻Spark-Streaming程序调优
对于长时间运行的Spark Streaming作业,一旦提交到YARN群集便需要永久运行,直到有意停止.任何中断都会引起严重的处理延迟,并可能导致数据丢失或重复.YARN和Apache Spark都不 ...
- 天眼查sign 算法破解
天眼查sign 算法破解 最近真的在sign算法破解上一去不复返 前几天看过了企查查的sign破解 今天再看看天眼查的sign算法破解,说的好(zhuang)点(bi)就是破解,不好的就是这是很简单的 ...
- MongoDB 数据库的学习与使用
MongoDB 数据库 一.MongoDB 简介(了解) MongoDB 数据库是一种 NOSQL 数据库,NOSQL 数据库不是这几年才有的,从数据库的初期发展就以及存在了 NOSQL 数据库. ...
- JS中的分支结构
if语句 语法: if (expression1) { } else if (expression2) { } else { } 执行机制: 先对expression1做判定,如果为真,执行对应的代码 ...