Python爬虫常用之登录(二) 浏览器模拟登录
浏览器模拟登录的主要技术点在于:
1.如何使用python的浏览器操作工具selenium
2.简单看一下网页,找到帐号密码对应的框框,要知道python开启的浏览器如何定位到这些
一、使用selenium打开网页
from selenium import webdriver url = 'https://passport.cnblogs.com/user/signin' driver = webdriver.Firefox()
driver.get(url)
以上几句执行便可以打开博客园的登录界面,开启浏览器可能较慢,耐心等一下.
以前的selenium可以直接打开firefox,现在的需要安装geckodriver,自己百度下载一个对应自己浏览器的型号的.
chrome一直都需要驱动,使用chrome的需要设置的可能麻烦一点.推荐看一下虫师的相关文章,个人觉得讲得不错,百度搜索出来还是比较靠前的.
二、找到帐号密码对应的页面元素
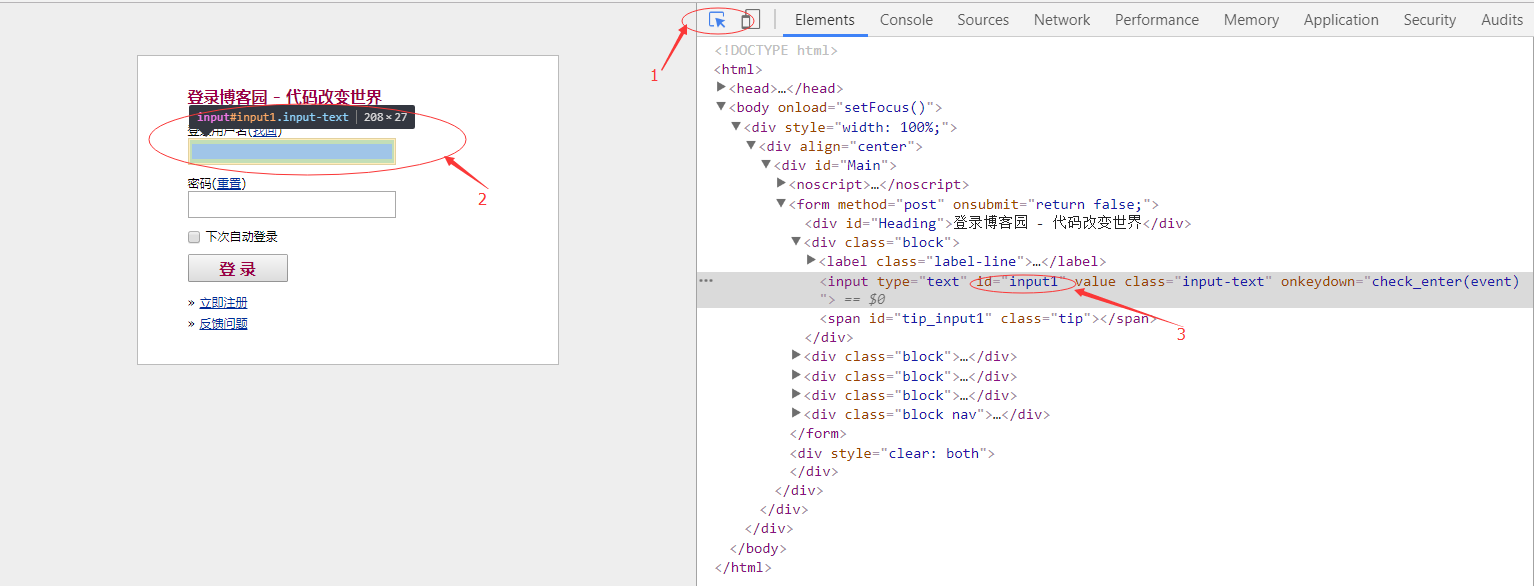 浏览器打开页面,点击f12,按上图步骤,找到了用户名的id"input1",同理找到密码的id,找到后发现是"input2".
浏览器打开页面,点击f12,按上图步骤,找到了用户名的id"input1",同理找到密码的id,找到后发现是"input2".
三、将自己的用户名和密码填入selenium打开的浏览器
使用find_element_by_id方法找到元素,再使用send_keys方法传入参数,最后使用click方法点击登录按钮即可.
成品代码有如下几句:
# /usr/bin/python
# encoding: utf-8 import time
from selenium import webdriver def login(username, password):
# url = 'https://passport.cnblogs.com/user/signin' # 使用这个url登录成功后定位到园子
url = 'https://passport.cnblogs.com/user/signin?ReturnUrl=https%3A%2F%2Fwww.cnblogs.com%2F' # url中指明定位到博客园首页 driver = webdriver.Firefox()
driver.get(url)
# print driver.title
name_input = driver.find_element_by_id('input1') # 找到用户名的框框
pass_input = driver.find_element_by_id('input2') # 找到输入密码的框框
login_button = driver.find_element_by_id('signin') # 找到登录按钮 name_input.clear()
name_input.send_keys(username) # 填写用户名
time.sleep(0.2)
pass_input.clear()
pass_input.send_keys(password) # 填写密码
time.sleep(0.2)
login_button.click() # 点击登录 time.sleep(0.2)
print driver.get_cookies() time.sleep(2)
print driver.title driver.close() if __name__ == "__main__":
user = "Masako"
pw = "*****"
login(user, pw)
使用time模块sleep主要是为了控制操作速度,防止被认为是机器人,比较符合现实的情况应该随机sleep时间.
上述代码执行之后(注意将用户名密码换成自己的),可以看到打开了浏览器,并自动填写了帐号密码,自动点击登录,成功后跳转,然后自动关闭浏览器.
本地可以看到打印了一份cookie和一个标题"博客园 - 开发者的网上家园".
如果登录失败,打印的标题会是"用户登录 - 博客园".
如果报错,未打开浏览器,多半是没有安装geckodriver.
上述代码会打开浏览器界面,若不想看到界面,可采用以下手段:
if __name__ == "__main__":
from pyvirtualdisplay import Display
display = Display(visible=0, size=(1366, 768))
display.start()
user = "Masako"
pw = "*****"
login(user, pw)
display.stop()
在调用浏览器的时候使用Display包裹,并将dispaly设置为不可见(visible=0)
Python爬虫常用之登录(二) 浏览器模拟登录的更多相关文章
- Python爬虫实战——反爬策略之模拟登录【CSDN】
在<Python爬虫实战-- Request对象之header伪装策略>中,我们就已经讲到:=="在header当中,我们经常会添加两个参数--cookie 和 User-Age ...
- Python爬虫入门(基础实战)—— 模拟登录知乎
模拟登录知乎 这几天在研究模拟登录, 以知乎 - 与世界分享你的知识.经验和见解为例.实现过程遇到不少疑问,借鉴了知乎xchaoinfo的代码,万分感激! 知乎登录分为邮箱登录和手机登录两种方式,通过 ...
- Python爬虫常用之登录(一) 思想
爬虫主要目的是获取数据,常见的数据可以直接访问网页或者抓包获取,然后再解析即可. 一些较为隐私的数据则不会让游客身份的访问者随便看到,这个时候便需要登录获取. 一般获取数据需要的是登录后的cookie ...
- Python爬虫教程-10-UserAgent和常见浏览器UA值
Python爬虫教程-10-UserAgent和常见浏览器UA值 有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器,隐藏用户身份, UserAgent 包含浏览器信息,用户身份,设备系统信息 Us ...
- Python爬虫常用之登录(三) 使用http请求登录
前面说了使用浏览器登录较为简单,不需要过多分析,而使用请求登录恰恰就是以分析为主. 开发一个请求登录程序的流程: 分析请求->模拟请求->测试登录->调整参数->测试登录-&g ...
- c# 爬虫(二) 模拟登录
有了上一篇的介绍,这次我们来说说模拟登录,上一篇见 :c# 爬虫(一) HELLO WORLD 原理 我们知道,一般需要登录的网站,服务器和客户端都会有一段时间的会话保持,而这个会话保持是在登录时候建 ...
- Python爬虫个人记录(二) 获取fishc 课件下载链接
参考: Python爬虫个人记录(一)豆瓣250 (2017.9.6更新,通过cookie模拟登陆方法,已成功实现下载文件功能!!) 一.目的分析 获取http://bbs.fishc.com/for ...
- Python爬虫实例(四)网站模拟登陆
一.获取一个有登录信息的Cookie模拟登陆 下面以人人网为例,首先使用自己的账号和密码在浏览器登录,然后通过抓包拿到cookie,再将cookie放到请求之中发送请求即可,具体代码如下: # -*- ...
- python中常用的模块二
一.序列化 指:在我们存储数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和传输的数据格式,这个就是序列化, 不同的序列化结果不同,但目的是一样的,都是为了存储和传输. 一,pickle.可 ...
随机推荐
- Part2_lesson4---ARM寻址方式
所谓寻址方式就是处理器根据指令中给出的信息来找到指令所需操作数的方式. 1.立即数寻址 ADD R0,R0,#0x3f; R0<-R0+0x3f 在以上指令中,第二个源操作数即为立即数,要求以“ ...
- Ubuntu14.04-LTS 从系统安装到配置可用
1.安装Ubuntu14.04LTS-64bit 使用U盘安装很方便快捷,可以使用老毛桃使用iso模式制作一个U盘启动盘,然后分区安装. 如果使用硬盘安装的话需要注意的问题是: 如果电脑上以前有Lin ...
- [operator]ELK6的安装
找了很久才找到一个博客写得比较全面的,FrankDeng 系统环境:CentOS7 相关软件:node-v10.9.0.tar.gz.kibana-6.4.0-linux-x86_64.tar.gz. ...
- oracle11g客户端配置及使用(Instant Client)
http://www.oracle.com/technetwork/topics/winx64soft-089540.html http://www.cnblogs.com/ychellboy/a ...
- C#结构(Struct)
Struct简介: 结构是使用 struct 关键字定义的,与类相似,都表示可以包含数据成员和函数成员的数据结构. 1.结构是一种值类型,并且不需要堆分配. 它都放在堆栈上2.结构的实例化可以不使用 ...
- Hibernate查询对象所有字段,单个字段 ,几个字段取值的问题
HQL 是Hibernate Query Language的简写,即 hibernate 查询语言:HQL采用面向对象的查询方式.HQL查询提供了更加丰富的和灵活的查询特性,因此Hibernate将H ...
- 使用#include消除重复代码
消除重复代码代码很多种,比如: 1)提炼成函数复用 2)使用宏 3)继承 4)使用闭包(boost::bind.boost::function) 上述是最为常用的,对于C++程序,闭包可能用得相对少一 ...
- Hadoop(HDFS、YARN、HBase、Hive和Spark等)默认端口表
端口 作用 9000 fs.defaultFS,如:hdfs://172.25.40.171:9000 9001 dfs.namenode.rpc-address,DataNode会连接这个端口 50 ...
- Gym - 100971J ——DFS
Statements Vitaly works at the warehouse. The warehouse can be represented as a grid of n × mcells, ...
- ExtractStrings字符串截取
//分割字符串 ExtractStrings var s: String; List: TStringList; begin s := 'about: #delphi; #pascal, ...