Hadoop系列-zookeeper基础
目前是刚刚初学完zookeeper,这篇文章主要是简单的对一些基本的概念进行梳理强化。
zookeeper基础概念的理解
有时候计算机领域很多名词都是从一长串英文提取首字母缩写而来,但很不幸zookeeper不是。那么,zookeeper到底是用来干什么的?我这里先摆一段官网的介绍:
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. All of these kinds of services are used in some form or another by distributed applications. Each time they are implemented there is a lot of work that goes into fixing the bugs and race conditions that are inevitable. Because of the difficulty of implementing these kinds of services, applications initially usually skimp on them, which make them brittle in the presence of change and difficult to manage. Even when done correctly, different implementations of these services lead to management complexity when the applications are deployed.(官网链接:http://zookeeper.apache.org)
由于目前还没有实际项目使用zookeeper的经验,针对上述的情况,目前只是对configuration、distributed synchronization有比较清楚的一个认识,认识到什么程度就先记录到什么程度,后期有更加深刻的认识后还会修改更新。首先,要明确两点,第一,zk是在分布式场景中使用,第二,主要的工作就是任务进程的协调调度。在多个应用访问同一个资源的情况下会出现资源竞争,例如一个是查询余额操作、一个是取钱操作、一个是存钱操作,这三个操作不可能放任不管让其自动操作,那么就会出现一个用于协调任务的调度器,zk就扮演这样一个角色,当然这只是其中一种应用-分布式锁,zk的其他应用还包括配置维护、分布式消息队列、分布式通知等。
zk的基本数据模型
zk的基本数据模型与Linux文件系统具有相似的结构,其中每一个节点称为znode,每一个znode都包含有两部分内容:
数据(默认最大存储空间为1MB,是原子操作)
元数据信息,包括cZxid、ctime、mtimp、pZxid等节点属性信息


节点类型
znode的类型在创建时就确定唯一,不可改变,包括:
临时节点、临时有序节点
永久节点、永久有序节点
临时性的节点生命周期取决于会话(session),会话结束节点自动消失,同时临时性节点不允许有子节点。永久性节点不依赖于会话,只有执行删除操作后才会消失。
watch机制
客户端可以通过设置watcher来监视节点的增、删、改等状态变化,当watcher被触发时,客户端会收到一条通知,考虑到需要减小网络数据传输流量,一个watcher只能被触发一次,要想多次触发,需要在触发执行的代码中再次设置watcher。
应用场景
配置管理
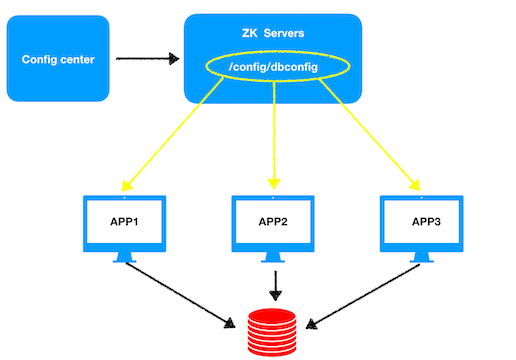
在一个分布式的系统中,每台机器运行一个app,app需要读取数据库的信息,而app与数据库连接需要相应的数据库信息,如ip地址、端口等,这个信息就可以通过一个配置文件存储在配置中心中,配置中心将配置信息写入znode的数据中进行存储,同时每个app会在相应的节点上注册一个watcher。一旦配置信息改变,配置中心将新的数据写入到节点中之后,watch机制触发,相应的app就会更改连接数据库所需的信息重新与数据库建立连接。

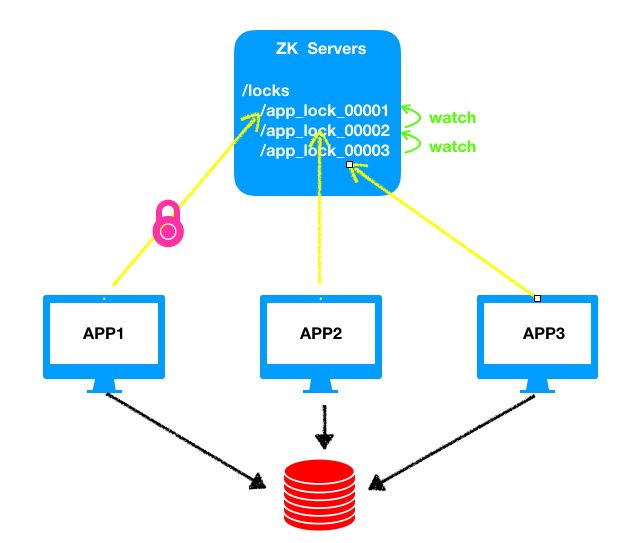
分布式锁
假设同一时间只能允许一个任务访问数据库中的某条数据,那么首先各个app会在ZK上注册一个自己的临时节点比如节点分别为/app_lock_00001、/app_lock_00002、/app_lock_00003,我们设置序号最小的节点获得锁,即/app_lock_00001,同时/app_lock_00002监听/app_lock_00001,/app_lock_00003监听/app_lock_00002,此时app1开始执行访问数据的操作,执行完成后断开连接,临时节点消失,/app_lock_00002节点监听到之后app2开始执行,同样的操作一直到app3执行完毕。

zk各台机器节点之间的角色
zk中各个机器节点之间的角色有:leader、follower、observe,三种,先不考虑observer,哪台节点是leader、哪些是follower是通过选举机制决定的。具体来讲有两种选举机制:
client端在连接zk servers的时候,会创建临时节点,根据client端与zk servers创建节点的时间顺序,哪一个先创建,哪一个作为leader,其他的就是follower。
client端在连接zk servers的时候,会创建临时有序节点,根据节点序号的大小,最小的为leader,其它为follower,并依次监听比当前节点号小的节点
zk运行正常情况下有以下特点:
客户端可随便连接其中的一台机器节点
客户端可以同时连接多台机器,实现连接的冗余
与事务(增、删、改)有关的操作会通过follower转发至leader,查询操作直接由所连接的服务器负责响应。
那么,对于事务操作转发给leader之后是如何进行的呢?首先,leader收到事务操作之后提出一个Proposal,其它的follower负责投票,leader收集投票之后如果超过半数,那么这次提议成功,同时响应对应的事务操作。同时发送消息给follower,follower接收消息之后会把操作更新至内存,最后响应client端。加入client数量不断增加的话,zk servers有可能就满足不了客户端访问的需求,而leader只有一个,那么就只能添加机器作为follower角色。依照这个逻辑,follower会不断增加,那么就会出现一个问题:一旦出现事务操作,leader要搜集半数以上的投票,follower越多,收集过程就会越慢。为了解决这个问题,在zookeeper3.3.3版本后引入了observer角色,observer不参与投票,但是其他方面包括转发事务操作、响应客户端查询操作都与follower一样,这样在增加机器的同时就不会因为投票规则而影响整体的响应性能。
以上是一个基本的认识,深入的细节可以参考博文:


Hadoop系列-zookeeper基础的更多相关文章
- Hadoop系列-HDFS基础
基本原理 HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方: 数据分块存储在多台主机 数据块采取冗余 ...
- Hadoop系列-MapReduce基础
由于在学习过程中对MapReduce有很大的困惑,所以这篇文章主要是针对MR的运行机制进行理解记录,主要结合网上几篇博客以及视频的讲解内容进行一个知识的梳理. MapReduce on Yarn运行原 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- hadoop系列:zookeeper(2)——zookeeper核心原理(选举)
1.前述 上篇文章<hadoop系列:zookeeper(1)--zookeeper单点和集群安装>(http://blog.csdn.net/yinwenjie/article/deta ...
- Zookeeper系列一:Zookeeper基础命令操作
有些事不是努力就可以改变的,五十块的人民币设计的再好看,也没有一百块的招人喜欢. 前言 由于公司年底要更换办公地点,所以最近投了一下简历,发现面试官现在很喜欢问dubbo.zookeeper和高并发等 ...
- HADOOP+SPARK+ZOOKEEPER+HBASE+HIVE集群搭建(转)
原文地址:https://www.cnblogs.com/hanzhi/articles/8794984.html 目录 引言 目录 一环境选择 1集群机器安装图 2配置说明 3下载地址 二集群的相关 ...
- Hadoop 系列(一)基本概念
Hadoop 系列(一)基本概念 一.Hadoop 简介 Hadoop 是一个由 Apache 基金会所开发的分布式系统基础架构,它可以使用户在不了解分布式底层细节的情況下开发分布式程序,充分利用集群 ...
- hadoop系列四:mapreduce的使用(二)
转载请在页首明显处注明作者与出处 一:说明 此为大数据系列的一些博文,有空的话会陆续更新,包含大数据的一些内容,如hadoop,spark,storm,机器学习等. 当前使用的hadoop版本为2.6 ...
- Hadoop生态圈-zookeeper完全分布式部署
Hadoop生态圈-zookeeper完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本篇博客部署是建立在Hadoop高可用基础之上的,关于Hadoop高可用部署请参 ...
随机推荐
- MyBatis -01- 初识 MyBatis + MyBatis 环境搭建
MyBatis -01- 初识 MyBatis + MyBatis 环境搭建 MyBatis 本是 apache 的一个开源项目 iBatis(iBATIS = "internet" ...
- python 字符串的方法和注释
capitalize() 把字符串的第一个字符改为大写 casefold() 把整个字符串的所有字符改为小写 center(width) 将字符串居中,并使用空格填充至长度 width 的新字符串 c ...
- 软工读书笔记 week 9 ——《构建之法》
软工读书笔记 week 9 ——<构建之法> 最近的三周我们正式开始我们的项目.然后我也把<构建之法>中的相关章节再拿出来读了一番.以下是一些 ...
- [C#] Microsoft .Net框架SerialPort类的用法与示例
从Microsoft .Net 2.0版本以后,就默认提供了System.IO.Ports.SerialPort类,用户可以非常简单地编写少量代码就完成串口的信息收发程序.本文将介绍如何在PC端用C# ...
- UIView使用UIMotionEffect效果
UIView使用UIMotionEffect效果 这个效果在模拟器上看不了,所以无法截图. UIView+MotionEffect.h + UIView+MotionEffect.m // // ...
- [翻译] PTEHorizontalTableView
PTEHorizontalTableView Horizontal UITableView inspired by EasyTableView. 水平滚动的UITableView,灵感来自于EasyT ...
- [翻译] UIImageView-Letters
UIImageView-Letters https://github.com/bachonk/UIImageView-Letters An easy, helpful UIImageView cate ...
- 安装oracle 11g时,报启动服务出现错误,找不到OracleMTSRecoveryService的解决方法
很多人在安装orcl数据库时,出现很多报错,我也不例外,因上次数据库出现问题,无法修复,只能从新安装,无奈的是,安装时报启动服务出现错误,找不到OracleMTSRecoveryService错MMP ...
- November 8th 2016 Week 46th Tuesday
When he can't, he tries a new way to share a new pair. 当他做不到时,他尝试一种新的方式:分享. To share, your failing e ...
- 新锤子驾到,通通闪开—Service Mesh
微服务方兴未艾如火如荼之际,除 Spring cloud 等经典框架之外,新一代的微服务开发技术正在悄然兴起,那就是Service Mesh(服务网格).2018 年是Service Mesh 元年, ...