Scrapy项目之User timeout caused connection failure(异常记录)
Windows 10家庭中文版,Python 3.6.4,Scrapy 1.5.0,
提示:此文存在问题,真正测试, 请勿阅读,
07-14 14:26更新:
经过两个多小时的测试,发现此问题的原因是 昨天编写爬虫程序后,给爬虫程序添加了下面的属性:
download_timeout = 20
此属性的解释:
The amount of time (in secs) that the downloader will wait before timing out.
在获取某网站的子域名的robots.txt文件时,需要的时间远远超过20秒,因此,即便有三次重试的机会,也会最终失败。
此值默认为180,因为某网站是国内网站,因此,孤以为它的文件全部都会下载的很快,不需要180这么大,于是更改为20,谁知道,其下子域名的robots.txt却需要这么久:
测试期间更改为30时,状况好了,目前已取消设置此值,已能抓取到需要的数据。
可是,为什么robots.txt会下载这么慢呢?
删除Request中定义的errback进行测试,也可以获取到需要的数据。
那么,在Request中定义errback有什么用呢?
现在,再次在项目内、项目外执行下面的命令都不会发生DNSLookupError了(测试过)(可是,上午怎么就发生了呢?):
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"
--------可以忽略后面部分--------
昨日写了一个爬虫程序,用来抓取新闻数据,但在抓取某网站数据时发生了错误:超时、重试……开始是超过默认等待180秒的时间,后来自己在爬虫程序中改为了20秒,所以下图显示为20 seconds。
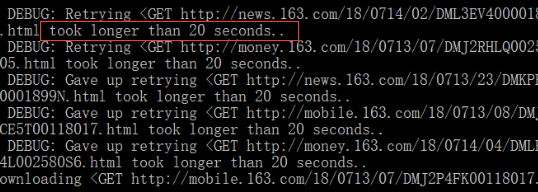
完全不知道怎么回事!上面是使用Scrapy项目内的基于CrawlerRunner编写的程序运行的,看不到更多数据!
尝试将爬虫中的allowed_domains改为下面两种形式(最后会使用第二种)进行测试——以为和子域名有关系:仍然失败。
#allowed_domains = ['www.163.com', 'money.163.com', 'mobile.163.com',
# 'news.163.com', 'tech.163.com'] allowed_domains = ['163.com']
后来又在settings.py中关闭了robots.txt协议、开启了Cookies支持:仍然失败。
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # Disable cookies (enabled by default)
COOKIES_ENABLED = True
此时,依靠着之前的知识储备是无法解决问题的了!
使用scrapy shell对获取超时的网页进行测试,结果得到了twisted.internet.error.DNSLookupError的异常信息:
scrapy shell "http://money.163.com/18/0714/03/DML7R3EO002580S6.html"


但是,使用ping命令却可以得到上面失败的子域名的IP地址:
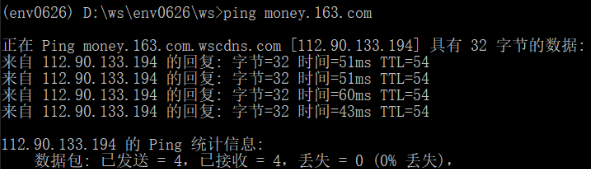
twisted作为一个很常用的Python库,怎么会发生这样的问题呢!完全不应该的!
求助网络吧!最终找到下面的文章:
How do I catch errors with scrapy so I can do something when I get User Timeout error?
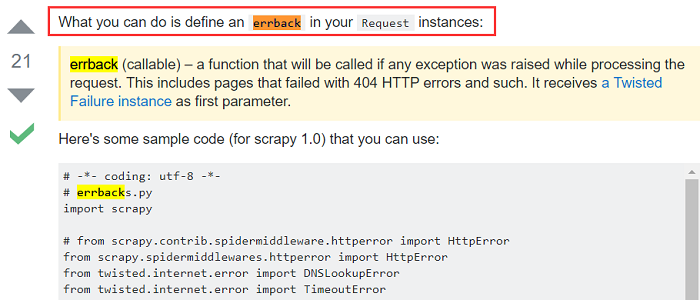
最佳答案!中文什么意思:在Request实例中定义errback!(请读三遍)
这么简单?和处理DNSLookupError错误有什么关系呢?为何定义了回调函数就可以了呢?
没想明白,不行动……
继续搜索,没有更多了……
好吧,试试这个方法,更改某网站的爬虫程序如下:
增加了errback = self.errback_163,其中,回调函数errback_163的写法和上面的参考文章中的一致(后来发现其来自Scrapy官文Requests and Responses中)。
yield response.follow(item, callback = self.parse_a_new,
errback = self.errback_163)
准备就绪,使用scapy crawl测试最新程序(在将之前修改的配置还原后——遵守robots.txt协议、禁止Cookies、allowed_domains设置为163.com):成功抓取了想要的数据!
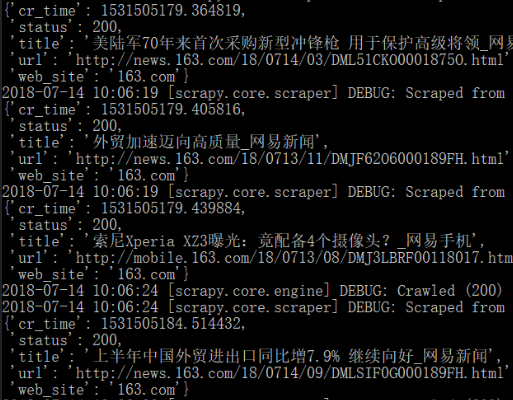
好了,问题解决了。可是,之前的疑问还是没有解决~后续再dig吧!~“神奇的”errback!~
Scrapy项目之User timeout caused connection failure(异常记录)的更多相关文章
- FTP上传文件,报错java.net.SocketException: Software caused connection abort: recv failed
FTP上传功能,使用之前写的代码,一直上传都没有问题,今天突然报这个错误: java.net.SocketException: Software caused connection abort: re ...
- scrapy 项目实战(一)----爬取雅昌艺术网数据
第一步:创建scrapy项目: scrapy startproject Demo 第二步:创建一个爬虫 scrapy genspider demo http://auction.artron.net/ ...
- java.net.SocketException: Software caused connection abort: socket write error
用Java客户端程序访问Java Web服务器时出错: java.net.SocketException: Software caused connection abort: socket write ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
- java.net.SocketException:Software caused connection abort: recv failed 异常分析 +socket客户端&服务端代码
java.net.SocketException:Software caused connection abort: recv failed 异常分析 分类: 很多的技术 2012-01-04 12: ...
- Software caused connection abort: recv failed 错误介绍
解决1: Software caused connection abort: recv failed java.net.SocketException: Software caused connect ...
- Software caused connection abort: socket write error
Exception in thread "main" java.net.SocketException: Software caused connection abort: soc ...
- HttpUrlConnection java.net.SocketException: Software caused connection abort: recv failed
最近做java swing程序在模拟httprequest请求的时候出现了这个错误 java.net.SocketException: Software caused connection abort ...
- 报错java.net.SocketException: Software caused connection abort: recv failed 怎么办
产生这个异常的原因有多种方面,单就如 Software caused 所示, 是由于程序编写的问题,而不是网络的问题引起的. 已知会导致这种异常的一个场景如下: 客户端和服务端建立tcp的短连接,每次 ...
随机推荐
- 解题:CF825E Minimal Labels
题面 看起来似乎是个水水的拓扑排序+堆,然而并不对,因为BFS拓扑排序的话每次只会在“当前”的点中排出一个最小/大的字典序,而我们是要一个确定的点的字典序尽量小.正确的做法是反向建图,之后跑一个字典序 ...
- opencv 启动摄像头 C++
http://blog.csdn.net/thefutureisour/article/details/7530177 在网上看了许多关于OpenCV启动摄像头的资料,但是,都是基于C语言的,代码又臭 ...
- C++调Python示例(转载)
C++调Python,代码粘贴如下: #include <iostream> #include <Python.h> using namespace std; void Hel ...
- P2243 电路维修
P2243 电路维修 题目背景 Elf 是来自Gliese 星球的少女,由于偶然的原因漂流到了地球上.在她无依无靠的时候,善良的运输队员Mark 和James 收留了她.Elf 很感谢Mark和Jam ...
- UDP_TCP示意图
- Kafka 0.8 Consumer处理逻辑
0.前言 客户端用法: kafka.javaapi.consumer.ConsumerConnector consumer = kafka.consumer.Consumer.createJavaCo ...
- HTTP协议(2)-------- 网络编程
1. HTTP请求格式 做过Socket编程的人都知道,当我们设计一个通信协议时,“消息头/消息体”的分割方式是很常用的,消息头告诉对方这个消息是干什么的,消息体告诉对方怎么干.HTTP协议传输的消息 ...
- ngx_lua_API 指令详解(一)ngx.timer.at 指令
语法: ok,err = ngx.timer.at(delay,callback,user_arg1,user_arg2 ...) 上下文: init_worker_by_lua *,set_by_l ...
- Javascript Ajax异步读取RSS文档
RSS 是一种基于 XML的文件标准,通过符合 RSS 规范的 XML文件可以简单实现网站之间的内容共享.Ajax 是Asynchronous JavaScript and XML的缩写.通过 Aja ...
- 解决IE6中 PNG图片透明的终极方案-八种方案!
“珍惜生命,远离IE6”,IE6中的bug令很多Web前端开发人员实为头疼,因此不知道烧了多少脑细胞,在众多的Bug中最令人抓狂的就是IE对png图片的不支持,导致设计师和重构师放弃了很多很炫的效果, ...