GoogLeNet InceptionV2/V3/V4
仅用作自己学习
这篇文章中我们会详细讲到Inception V2/V3/V4的发展历程以及它们的网络结构和亮点。
GoogLeNet Inception V2
GoogLeNet Inception V2在《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》出现,最大亮点是提出了Batch Normalization方法,它起到以下作用:
- 使用较大的学习率而不用特别关心诸如梯度爆炸或消失等优化问题;
- 降低了模型效果对初始权重的依赖;
- 可以加速收敛,一定程度上可以不使用Dropout这种降低收敛速度的方法,但却起到了正则化作用提高了模型泛化性;
- 即使不使用ReLU也能缓解激活函数饱和问题;
- 能够学习到从当前层到下一层的分布缩放( scaling (方差),shift (期望))系数。
在机器学习中,我们通常会做一种假设:训练样本独立同分布(iid)且训练样本与测试样本分布一致,如果真实数据符合这个假设则模型效果可能会不错,反之亦然,这个在学术上叫Covariate Shift,所以从样本(外部)的角度说,对于神经网络也是一样的道理。从结构(内部)的角度说,由于神经网络由多层组成,样本在层与层之间边提特征边往前传播,如果每层的输入分布不一致,那么势必造成要么模型效果不好,要么学习速度较慢,学术上这个叫InternalCovariate Shift。
假设:yy为样本标注,X={x1,x2,x3,......}X={x1,x2,x3,......}为样本xx通过神经网络若干层后每层的输入;
理论上:p(x,y)p(x,y)的联合概率分布应该与集合XX中任意一层输入的联合概率分布一致,如:p(x,y)=p(x1,y)p(x,y)=p(x1,y);
但是:p(x,y)=p(y|x)⋅p(x)p(x,y)=p(y|x)·p(x),其中条件概率p(y|x)p(y|x)是一致的,即p(y|x)=p(y|x1)=p(y|x1)=......p(y|x)=p(y|x1)=p(y|x1)=......,但由于神经网络每一层对输入分布的改变,导致边缘概率是不一致的,即p(x)≠p(x1)≠p(x2)......p(x)≠p(x1)≠p(x2)......,甚至随着网络深度的加深,前面层微小的变化会导致后面层巨大的变化。
BN整个算法过程如下:

- 以batch的方式做训练,对m个样本求期望和方差后对训练数据做白化,通过白化操作可以去除特征相关性并把数据缩放在一个球体上,这么做的好处既可以加快优化算法的优化速度也可能提高优化精度,一个直观的解释:
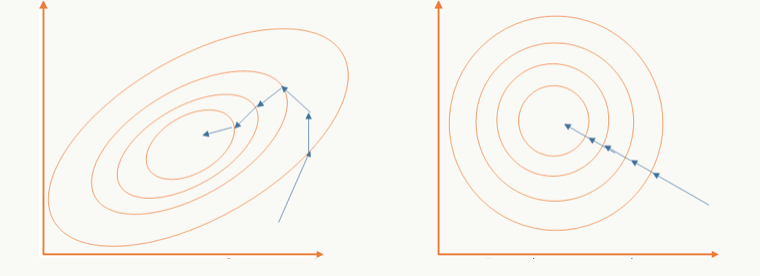
左边是未做白化的原始可行域,右边是做了白化的可行域;
- 当原始输入对模型学习更有利时能够恢复原始输入(和残差网络有点神似):
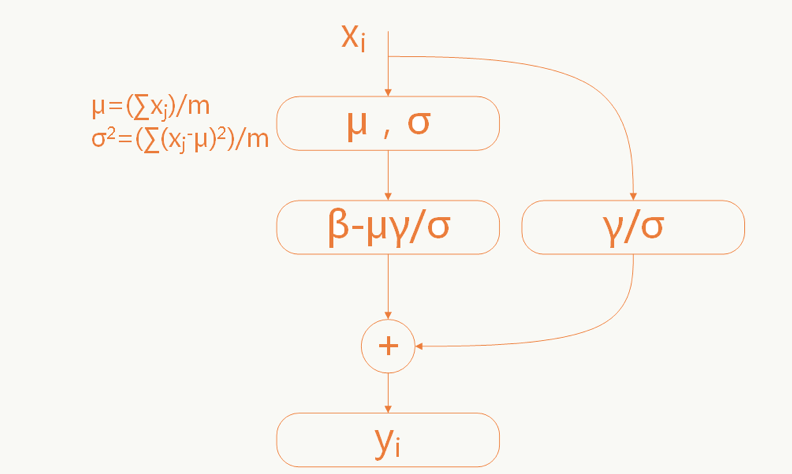
这里的参数γγ和σσ是需要学习的。
卷积神经网络中的BN
卷积网络中采用权重共享策略,每个feature map只有一对γγ和σσ需要学习。

GoogLeNet Inception V3
GoogLeNet Inception V3在《Rethinking the Inception Architecture for Computer Vision》中提出(注意,在这篇论文中作者把该网络结构叫做v2版,我们以最终的v4版论文的划分为标准),该论文的亮点在于:
- 提出通用的网络结构设计准则
- 引入卷积分解提高效率
- 引入高效的feature map降维
网络结构设计的准则
前面也说过,深度学习网络的探索更多是个实验科学,在实验中人们总结出一些结构设计准则,但说实话我觉得不一定都有实操性:
- 避免特征表示上的瓶颈,尤其在神经网络的前若干层
神经网络包含一个自动提取特征的过程,例如多层卷积,直观并符合常识的理解:如果在网络初期特征提取的太粗,细节已经丢了,后续即使结构再精细也没法做有效表示了;举个极端的例子:在宇宙中辨别一个星球,正常来说是通过由近及远,从房屋、树木到海洋、大陆板块再到整个星球之后进入整个宇宙,如果我们一开始就直接拉远到宇宙,你会发现所有星球都是球体,没法区分哪个是地球哪个是水星。所以feature map的大小应该是随着层数的加深逐步变小,但为了保证特征能得到有效表示和组合其通道数量会逐渐增加。
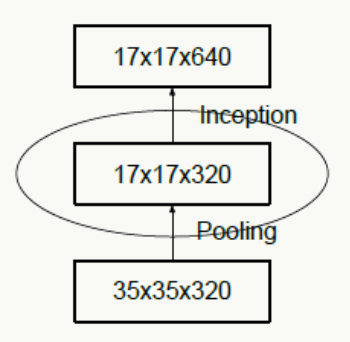
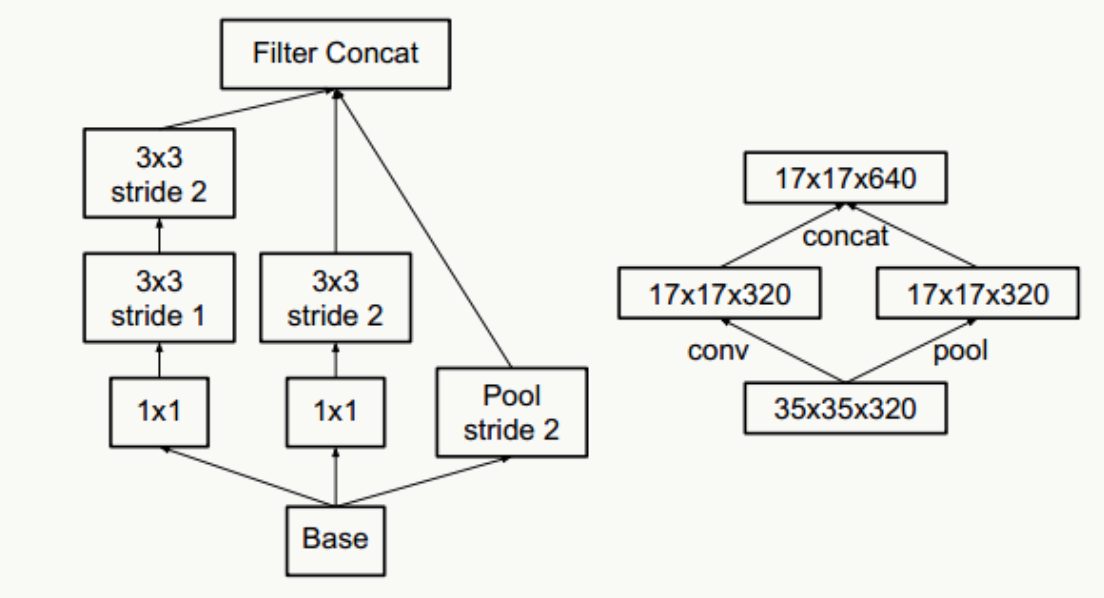
下图违反了这个原则,刚开就始直接从35×35×320被抽样降维到了17×17×320,特征细节被大量丢失,即使后面有Inception去做各种特征提取和组合也没用。
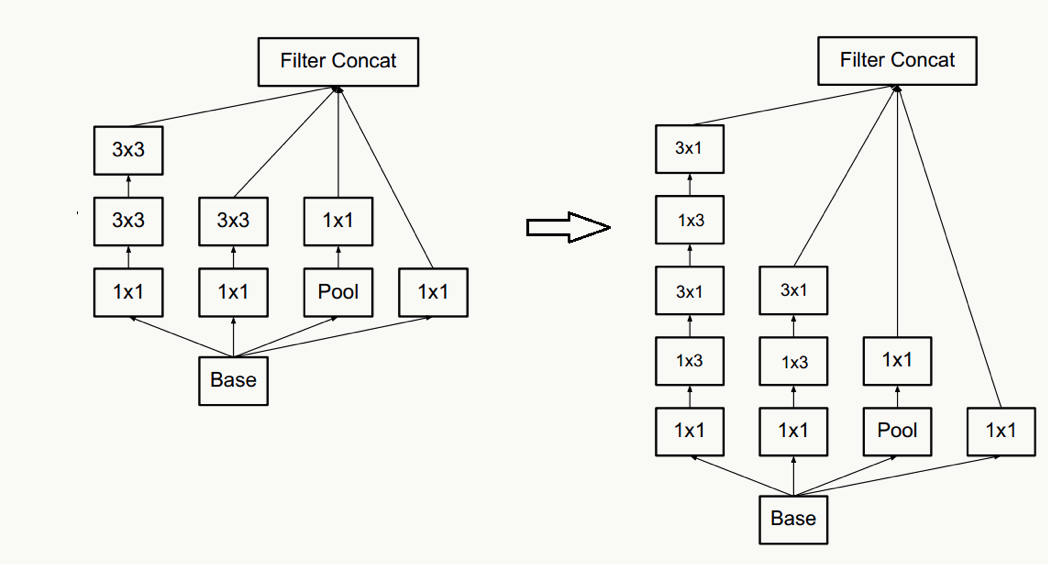
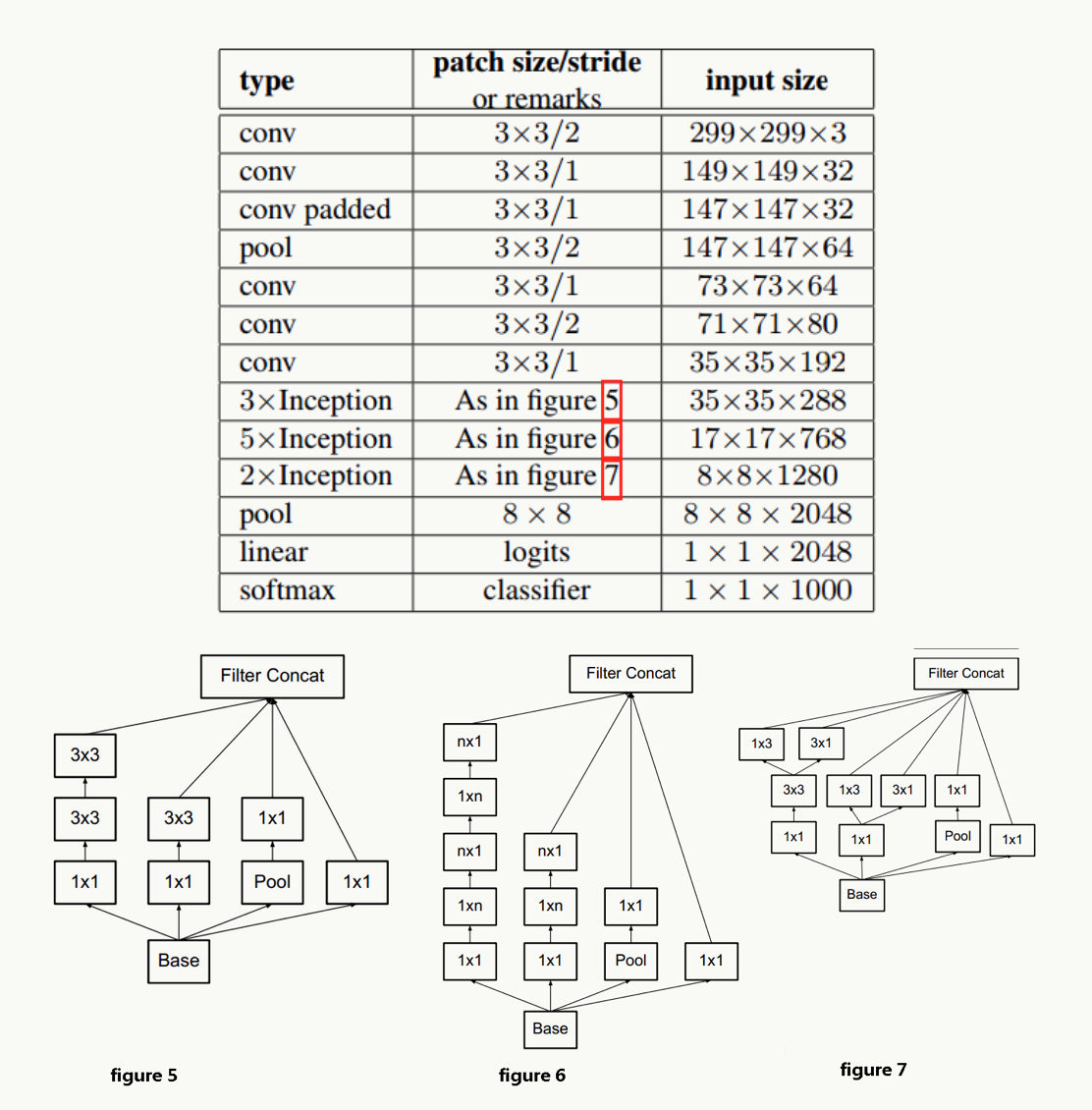
- 对于神经网络的某一层,通过更多的激活输出分支可以产生互相解耦的特征表示,从而产生高阶稀疏特征,从而加速收敛,注意下图的1×3和3×1激活输出:

- 合理使用维度缩减不会破坏网络特征表示能力反而能加快收敛速度,典型的例如通过两个3×3代替一个5×5的降维策略,不考虑padding,用两个3×3代替一个5×5能节省1-(3×3+3×3)/(5×5)=28%的计算消耗。

- 以及一个n×n卷积核通过顺序相连的两个1×n和n×1做降维(有点像矩阵分解),如果n=3,计算性能可以提升1-(3+3)/9=33%,但如果考虑高性能计算性能,这种分解可能会造成L1 cache miss率上升。
- 通过合理平衡网络的宽度和深度优化网络计算消耗(这句话尤其不具有实操性)。
- 抽样降维,传统抽样方法为pooling+卷积操作,为了防止出现特征表示的瓶颈,往往需要更多的卷积核,例如输入为n个d×d的feature map,共有k个卷积核,pooling时stride=2,为不出现特征表示瓶颈,往往k的取值为2n,通过引入inception module结构,即降低计算复杂度,又不会出现特征表示瓶颈,实现上有如下两种方式:
平滑样本标注
对于多分类的样本标注一般是one-hot的,例如[0,0,0,1],使用类似交叉熵的损失函数会使得模型学习中对ground truth标签分配过于置信的概率,并且由于ground truth标签的logit值与其他标签差距过大导致,出现过拟合,导致降低泛化性。一种解决方法是加正则项,即对样本标签给个概率分布做调节,使得样本标注变成“soft”的,例如[0.1,0.2,0.1,0.6],这种方式在实验中降低了top-1和top-5的错误率0.2%。
网络结构
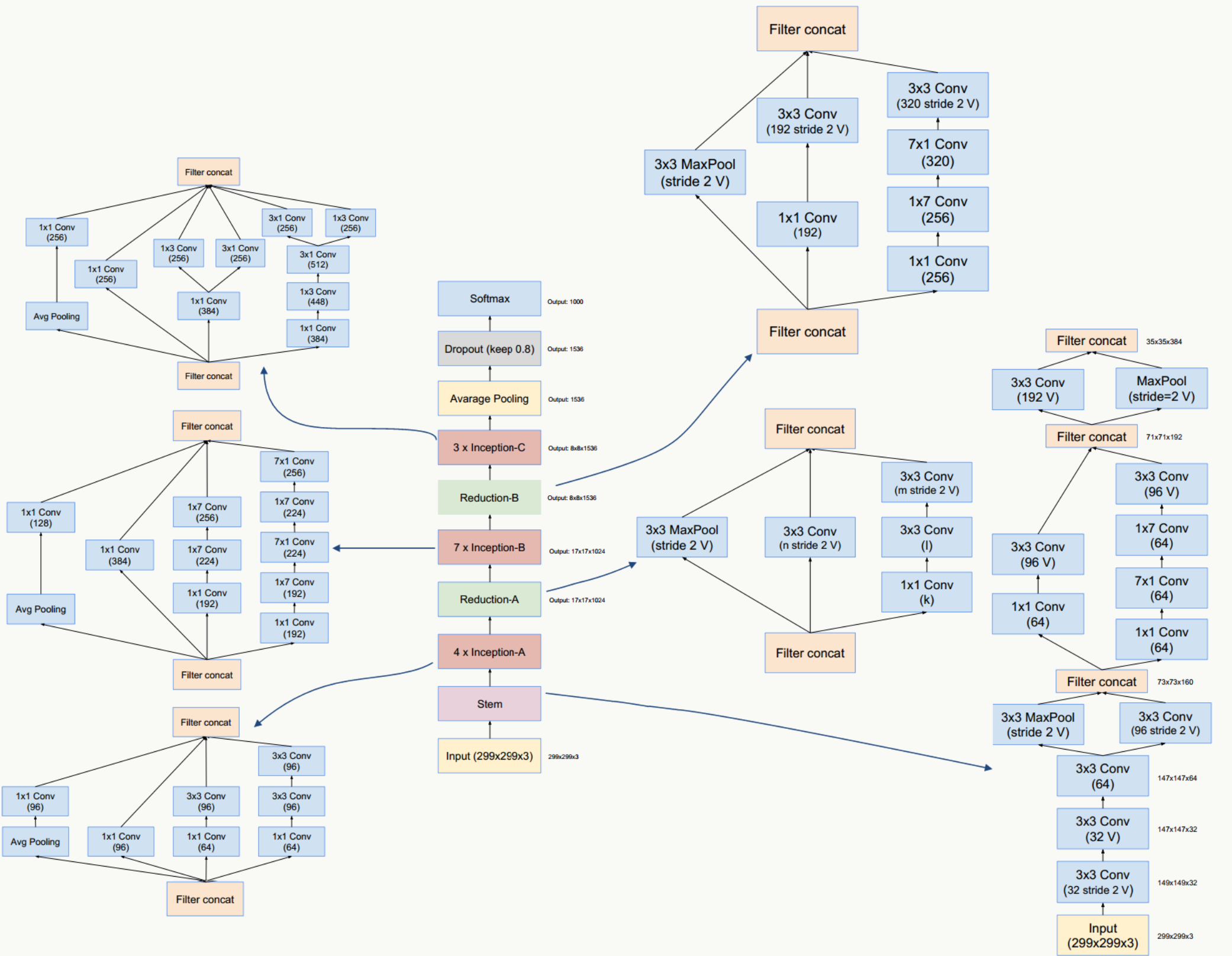
GoogLeNet Inception V4
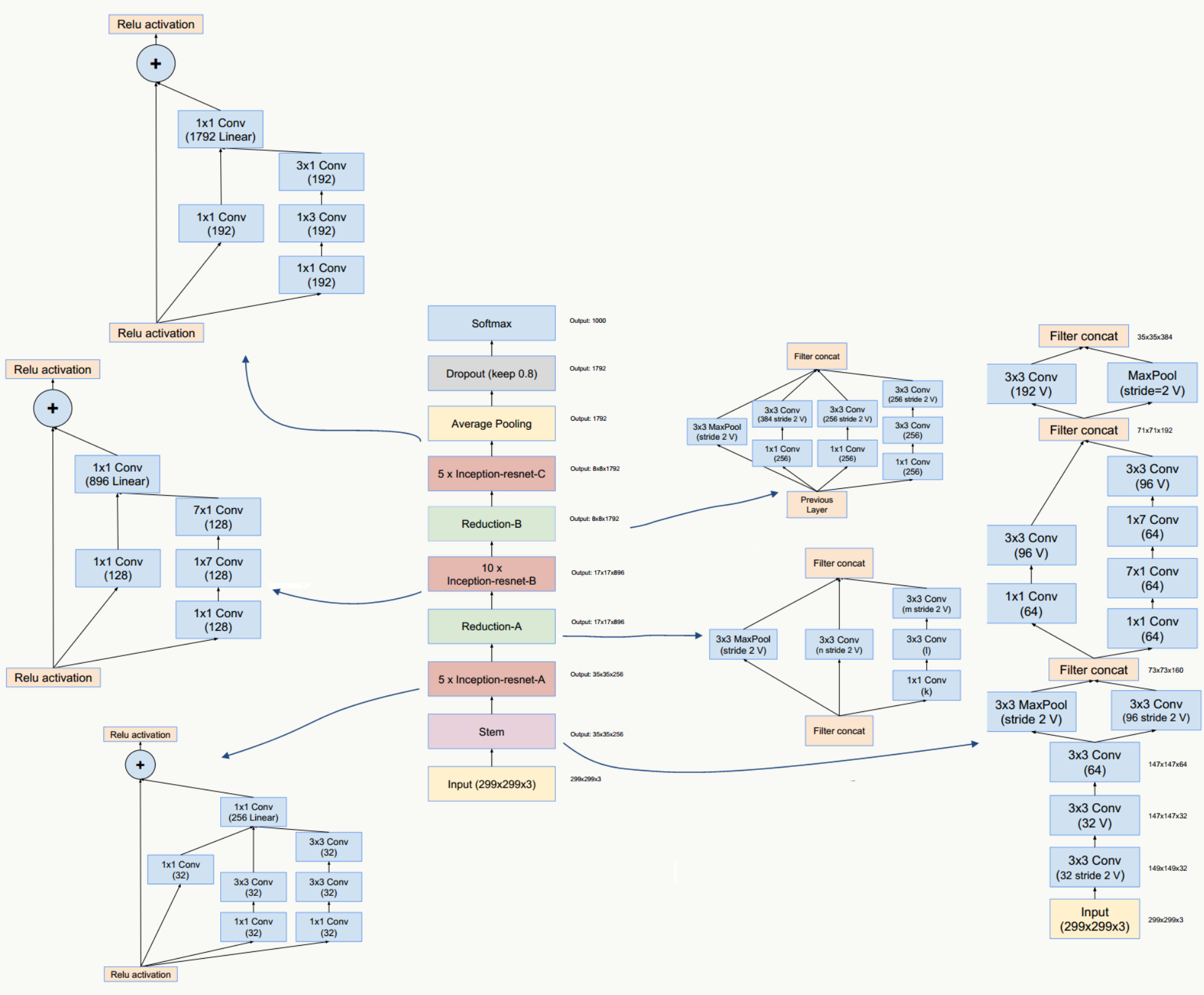
GoogLeNet Inception V4/和ResNet V1/V2这三种结构在《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》一文中提出,论文的亮点是:提出了效果更好的GoogLeNet Inception v4网络结构;与残差网络融合,提出效果不逊于v4但训练速度更快的结构。
GoogLeNet Inception V4网络结构
GoogLeNet Inception ResNet网络结构
代码实践
Tensorflow的代码在slim模块下有完整的实现,paddlepaddle的可以参考上篇文章中写的inception v1的代码来写。
总结
这篇文章比较偏理论,主要讲了GoogLeNet的inception模块的发展,包括在v2中提出的batch normalization,v3中提出的卷积分级与更通用的网络结构准则,v4中的与残差网络结合等,在实际应用过程中可以可以对同一份数据用不同的网络结构跑一跑,看看结果如何,实际体验一下不同网络结构的loss下降速率,对准确率的提升等。
GoogLeNet InceptionV2/V3/V4的更多相关文章
- 【深度学习系列】用PaddlePaddle和Tensorflow实现GoogLeNet InceptionV2/V3/V4
上一篇文章我们引出了GoogLeNet InceptionV1的网络结构,这篇文章中我们会详细讲到Inception V2/V3/V4的发展历程以及它们的网络结构和亮点. GoogLeNet Ince ...
- GoogLeNet 之 Inception v1 v2 v3 v4
论文地址 Inception V1 :Going Deeper with Convolutions Inception-v2 :Batch Normalization: Accelerating De ...
- GoogLeNet 改进之 Inception-v2/v3 解读
博主在前一篇博客中介绍了GoogLeNet 之 Inception-v1 解读中的结构和思想.Inception的计算成本也远低于VGGNet.然而,Inception架构的复杂性使得更难以对网络进行 ...
- 从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2
from:https://blog.csdn.net/qq_14845119/article/details/73648100 Inception v1的网络,主要提出了Inceptionmodule ...
- 51nod Bash游戏(V1,V2,V3,V4(斐波那契博弈))
Bash游戏V1 有一堆石子共同拥有N个. A B两个人轮流拿.A先拿.每次最少拿1颗.最多拿K颗.拿到最后1颗石子的人获胜.如果A B都很聪明,拿石子的过程中不会出现失误.给出N和K,问最后谁能赢得 ...
- 深度学习面试题29:GoogLeNet(Inception V3)
目录 使用非对称卷积分解大filters 重新设计pooling层 辅助构造器 使用标签平滑 参考资料 在<深度学习面试题20:GoogLeNet(Inception V1)>和<深 ...
- td-agent的v2,v3,v4版本区别
官方地址:https://docs.fluentd.org/quickstart/td-agent-v2-vs-v3-vs-v4
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络GoogLeNet
前面讲了LeNet.AlexNet和Vgg,这周来讲讲GoogLeNet.GoogLeNet是由google的Christian Szegedy等人在2014年的论文<Going Deeper ...
- GPU端到端目标检测YOLOV3全过程(上)
GPU端到端目标检测YOLOV3全过程(上) Basic Parameters: Video: mp4, webM, avi Picture: jpg, png, gif, bmp Text: doc ...
随机推荐
- IEEE1588精密网络同步协议(PTP)
1 引言 以太网技术由于其开放性好.价格低廉和使用方便等特点,已经广泛应用于电信级别的网络中,以太网的数据传输速度也从早期的10M提高到100M,GE,10GE.40GE,100GE正式产品也于20 ...
- Surface Pro 4远程桌面分辨率问题
Surface Pro 4是非常收欢迎的笔记本电脑.但我们这些技术人员在使用中有一点非常不方便: Surface Pro 4的分辨率非常高,如果用Surface Pro 4远程桌面到远端的一台机器,因 ...
- FMDB是iOS平台的SQLite数据库框架
1.FMDB简介 什么是FMDBFMDB是iOS平台的SQLite数据库框架 FMDB以OC的方式封装了SQLite的C语言API 为什么使用FMDB使用起来更加面向对象,省去了很多麻烦.冗余的C语言 ...
- 环形缓冲区的应用ringbuffer
在嵌入式开发中离不开设备通信,而在通信中稳定性最高的莫过于环形缓冲区算法, 当读取速度大于写入速度时,在环形缓冲区的支持下不会丢掉任何一个字节(硬件问题除外). 在通信程序中,经常使用环形缓冲区作为数 ...
- Java 的基本语法
Java 语言严格区分大小写 一个 Java 源文件里可以定义多个类,但其中只能有一个类被定义为 public 类 如果源文件中包含了 public 类,源文件的名称必须和该 public 类同名 p ...
- java反射专题二
一丶Class中常用方法详解 1)getFields() 只能获取到运行时类中及其父类中声明为public的属性 2)getDeclaredFields() 获取运行时类本身声明的所有属性 3)get ...
- 部署和调优 1.3 pureftp部署和优化-1
FTP 是 File Transfe Protocol(文件传输协议)的英文简称,而中文简称为 “文传协议” 用于 Internet 上的控制件的双向传输. 可以访问 www.pureftpd. ...
- Caused by: java.lang.IllegalStateException: Immutable bitmap passed to Canvas constructor
Bitmap bmp =BitmapFactory.decodeResource(getResources(), R.drawable.ic_launcher); Paint paint = new ...
- jQuery选择器大全整理
一.选择网页元素 $(document) //选择整个文档对象 $('#myId') //选择ID为myId的网页元素 $('div.myClass') // 选择class为myClass的div元 ...
- Hbuilder实用技巧(转)
Hbuilder实用技巧 原创 2016年05月19日 10:25:42 标签: hbuilder 操作 16551 1. Q:怎么实现代码追踪? A:在编辑代码时经常会出现需要跳转到引用文件或者变量 ...