Scrapy(爬虫应用框架)安装配置
运行平台:Windows
Python版本:Python3.x
一、Scarpy 简介
Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中。Scrapy最初就是为了网络爬取而设计的。
学习Scrapy,它能我们更好的完成爬虫任务,自己写Python爬虫程序好比孤军奋战,而使用了Scrapy就好比手底下有了千军万马。Scrapy可以起到事半功倍(甚至好几倍*.*)的效果。所以,学习Scrapy也就显得很有必要了。
二、Scrapy安装
1、直接在dos中使用命令‘pip3 install scrapy’,可能会报多种错误,例如图示,就是本人在安装过程中碰到的错误
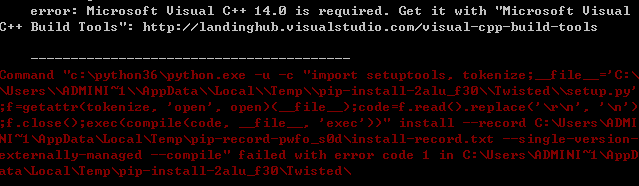
2、解决方法
查阅了很多网上的资料,是因为直接安装scrapy时,好多库在windows上并没有安装,所以只能一步步安装第三方库了,还好python有很多编译好的第三方库:http://www.lfd.uci.edu/~gohlke/pythonlibs/
安装scrapy需要的第三方库Lxml、Twisted、Scrapy
(1)首先在cmd中输入python,查看自己电脑对应的python版本

图上可以看到我自己电脑上安装的是python3.6.0
(2)登录第三方库地址下载对应python版本的Lxml、Twisted、Scrapy文件
Scrapy-1.5.1-py2.py3-none-any.whl
Twisted-18.9.0-cp36-cp36m-win32.whl
lxml-4.2.5-cp36-cp36m-win32.whl


(3)在cmd中输入命令,进入到下载好的whl文件中,安装文件,例如我将三个文件放在‘G:\Scrapy32’中

(4)依次执行下列命令
a、pip3 install wheel

b、pip3 install lxml-4.2.5-cp36-cp36m-win32.whl

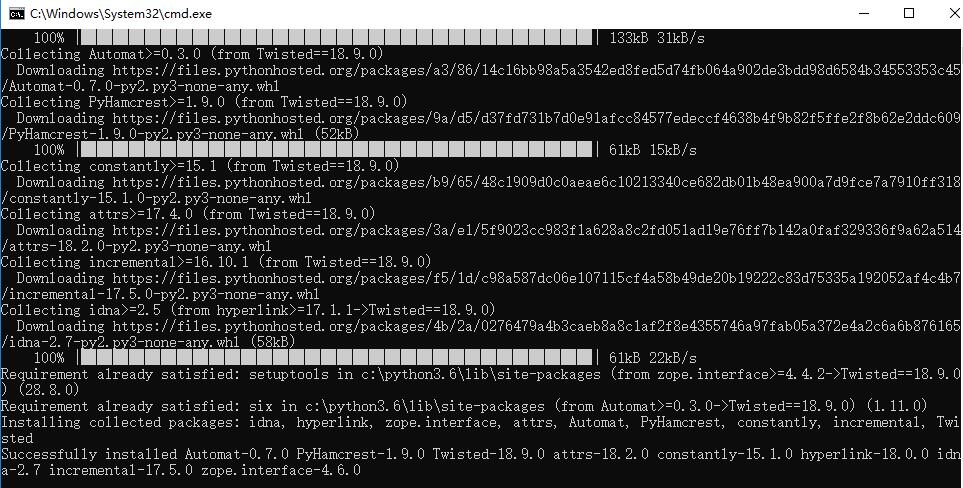
c、pip3 install Twisted-18.9.0-cp36-cp36m-win32.whl
d、pip3 install Scrapy-1.5.1-py2.py3-none-any.whl
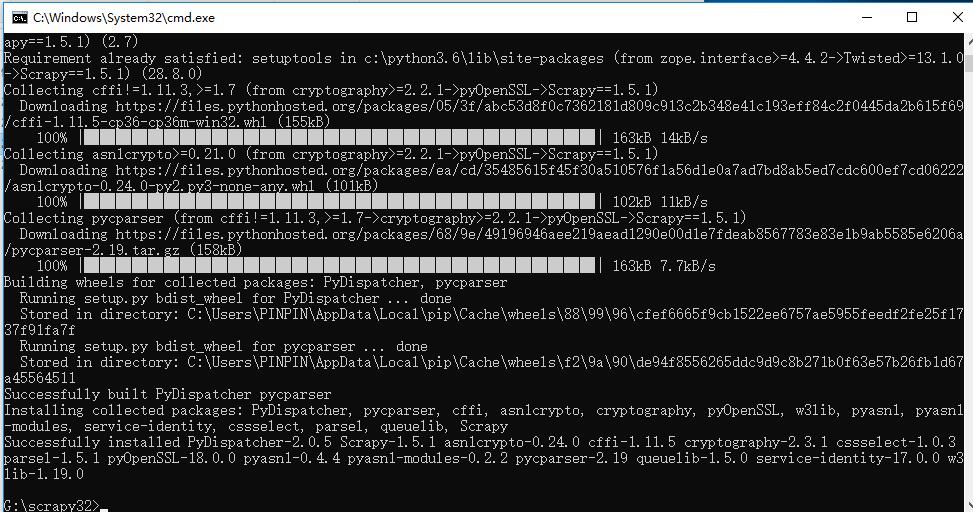
这样Scrapy的安装就完成了
(5)Srapy已经安装成功,还要下载pywin32,找到对应版本下载,一路下一步安装即可。安装完成后,就可以正常使用Scrapy了。
pywin32下载地址:https://sourceforge.net/projects/pywin32/files/pywin32/Build%20220/
至此,大功告成,我们可以愉快的使用Scrapy了。
注意:在cmd中输入Scrapy可以查看是否安装完成,很好高兴,我一次安装成功了,如果有warning,查看是那个库没有装,然后使用pip3 install XX(库名)安装即可
Scrapy(爬虫应用框架)安装配置的更多相关文章
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫进阶之Scrapy框架安装配置
Python爬虫进阶之Scrapy框架安装配置 初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此 ...
- drf框架安装配置及其功能概述
0902自我总结 drf框架安装配置及其功能概述 一.安装 pip3 install djangorestframework 二.配置 # 注册drf app NSTALLED_APPS = [ # ...
- Python3 爬虫之 Scrapy 框架安装配置(一)
博客地址:http://www.moonxy.com 基于 Python 3.6.2 的 Scrapy 爬虫框架使用,Scrapy 的爬虫实现过程请参照本人的另一篇博客:Python3 爬虫之 Scr ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 自动化测试平台(Vue前端框架安装配置)
Vue简介: 通俗的来说Vue是前端框架,用来写html的框架,可轻量级也可不轻量级 Vue特性: 绑定性,响应性,实时性,组件性 安装软件以及控件: 控件库:element-ui node.js ( ...
- 芝麻HTTP:Python爬虫进阶之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- python爬虫框架(3)--Scrapy框架安装配置
1.安装python并将scripts配置进环境变量中 2.安装pywin32 在windows下,必须安装pywin32,安装地址:http://sourceforge.net/projects/p ...
- scrapy框架安装配置
scrapy框架 scrapy安装(win) 1.pip insatll wheel 2.下载合适的版本的twisted:http://www.lfd.uci.edu/~gohlke/pythonli ...
- Python爬虫进阶二之PySpider框架安装配置
关于 首先,在此附上项目的地址,以及官方文档 PySpider 官方文档 安装 1. pip 首先确保你已经安装了pip,若没有安装,请参照 pip安装 2. phantomjs PhantomJS ...
随机推荐
- [转] 更新Flash CS6发布设置的目标播放器版本
目前Aodbe发布的最新版的Flash CS6,都不支持将Flash Player 11作为目标播放器版本发布.这个问题很容易解决,但涉及到的东西却比较多,我在这里将一一讲解.首先来个Setp by ...
- File:isctype.c Line 68
刚接触DSP,拿来别人的代码,编译时,发现如下错误: 百思不得琪姐,一番调查之后,发现自己的工程worksapce中有中文路径,怎一个fuck了得.
- linux普通用户home目录锁定
- C语言学习笔记--接续符和转义符
1.C语言中的接续符 (1)编译器将反斜杠剔除,跟在反斜杠后面的字符自动接续到前一行 (2)在接续单词时,反斜杠之后不能有空格,反斜杠下一行之前也不能有空格 (3)接续符适合在宏定义代码块时使用 #i ...
- mysql软文
常用的MySQL复杂查询语句写法 http://www.blogjava.net/bolo/archive/2015/02/02/422649.html mysql sql常用语句大全 http: ...
- [HDU1711]KMP模板
解题关键:1.直接套kmp模板即可,注意最后输出的位置,需要在索引的位置+1. 2.next用作数组名在oj中会编译错误, 3.选用g++,只有g++才会接受bits/stdc++.h OJ中g++和 ...
- MQTT,XMPP,STOMP,AMQP,WAMP适用范围优缺点比较
想要向服务器发送请求并获得响应?直接使用 HTTP 吧!非常简单.但是当需要通过持久的双向连接来通信时,如 WebSockets,当然你也有其它的选择. 这篇文章会简单扼要的解释 MQTT,XMPP, ...
- leetcode:7. Reverse Integer
这题简单,也花了我好长时间,我自己写的code比较麻烦,也没啥技巧:按正负性分类执行,先转化成字符串,用stringbuilder进行旋转,如果超出范围了就用try catch public int ...
- Win7环境下Sublime Text 3下安装NodeJS插件
1.首先下载安装Node.JS,配置好环境变量(安装好Node.JS默认是配置好了环境变量的). 2.Sublime Text 3下安装NodeJS插件. 参考的两篇文章:http://www.cnb ...
- 28.【转载】挖洞技巧:APP手势密码绕过思路总结
说到APP手势密码绕过的问题,大家可能有些从来没接触过,或者接触过,但是思路也就停留在那几个点上,这里我总结了我这1年来白帽子生涯当中所挖掘的关于这方面的思路,有些是网上已经有的,有些是我自己不断摸索 ...