sqoop简单import使用
一、sqoop作用?
sqoop是一个数据交换工具,最常用的两个工具是导入导出。
导入导出的参照物是hadoop,向hadoop导数据就是导入。
二、sqoop的版本?
sqoop目前有两个版本,1.4.X为sqoop1;1.99.X为sqoop2。两个版本不兼容。
三、使用sqoop列出mysql下的所有数据库
(my_python_env)[root@hadoop26 ~]# sqoop list-databases --connect jdbc:mysql://localhost:3306 --username root --password 123456
information_schema
hive
mysql
test
四、Import工具的使用
4.1将mysql中的某张表导入到hdfs上,现在test下有一张person表
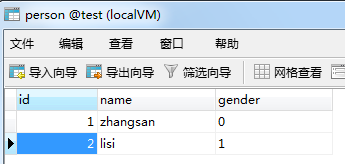
4.2执行sqoop语句
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 -table person
4.3在hdfs用户的家目录下,产生了一个person文件夹
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls
Found items
drwx------ - root supergroup -- : .Trash
drwxr-xr-x - root supergroup -- : person
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person
Found items
-rw-r--r-- root supergroup -- : person/_SUCCESS
-rw-r--r-- root supergroup -- : person/part-m-
-rw-r--r-- root supergroup -- : person/part-m-
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person/part-*
,zhangsan,false
,lisi,true
4.4delete-target-dir参数
当再次执行sqoop语句的时候,会报错,因为person文件夹已经存在了,我们需要先删除这个文件夹再运行sqoop语句。
也可以使用sqoop提供的delete-target-dir参数
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 -table person --delete-target-dir
4.5append参数
如果目标文件夹在hdfs上已经存在,那么再次运行就会报错。可以使用--delete-target-dir来先删除目录。也可以使用append来往目录下追加数据。append和delete-target-dir是相互冲突的。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --append
执行完成后,查看hdfs上的文件
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person
Found items
-rw-r--r-- root supergroup -- : person/_SUCCESS
-rw-r--r-- root supergroup -- : person/part-m-
-rw-r--r-- root supergroup -- : person/part-m-
-rw-r--r-- root supergroup -- : person/part-m-
-rw-r--r-- root supergroup -- : person/part-m-
4.6target-dir参数
上述的所有操作都是吧mysql中的数据写到一个默认的目录下,可以使用target-dir来指定hdfs的目录名
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --table person --append --target-dir person-mysql
查看hdfs上的目录
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls
Found items
drwx------ - root supergroup -- : .Trash
drwxr-xr-x - root supergroup -- : _sqoop
drwxr-xr-x - root supergroup -- : person
drwxr-xr-x - root supergroup -- : person-mysql
4.7map的个数
现在mysql表person中的数据增加到了11条
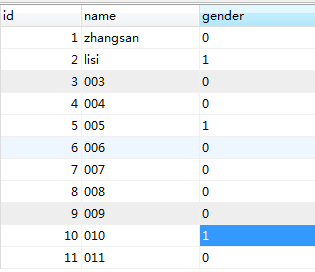
再次执行sqoop语句来导入
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql
查看hdfs上的目录
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found items
-rw-r--r-- root supergroup -- : person-mysql/_SUCCESS
-rw-r--r-- root supergroup -- : person-mysql/part-m-
-rw-r--r-- root supergroup -- : person-mysql/part-m-
-rw-r--r-- root supergroup -- : person-mysql/part-m-
-rw-r--r-- root supergroup -- : person-mysql/part-m-
从上面的结果可以发现,这个作业启动了4个map任务,所以sqoop默认配置就是4个map,用户也可以通过-m参数,自己指定map的数量
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql -m 1
查看hdfs上的目录发现,这次只启动了一个map任务
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found items
-rw-r--r-- root supergroup -- : person-mysql/_SUCCESS
-rw-r--r-- root supergroup -- : person-mysql/part-m-
4.8where参数
where参数可以进行一些简单的筛选
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --table person --target-dir person-mysql -m 1 --where "gender=0"
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
,zhangsan,false
,,false
,,false
,,false
,,false
,,false
,,false
,,false
4.9query参数
query参数就可以让用户随意写sql语句来查询了。query和table参数是互斥的。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --query "select * from person where name='003' and gender=0 and \$CONDITIONS"
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part-*
,,false
4.10压缩
如果想要使得导入到hdfs上的数据被压缩,就可以使用-z或者--compression-codec来进行压缩,-z压缩方式是gzip压缩,--compression-codec可以自定义压缩方式
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person -z
查看hdfs上的结果:
(my_python_env)[root@hadoop26 ~]# hadoop fs -ls person-mysql
Found items
-rw-r--r-- root supergroup -- : person-mysql/_SUCCESS
-rw-r--r-- root supergroup -- : person-mysql/part-m-.gz
使用Snappy方式压缩
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person --compression-codec org.apache.hadoop.io.compress.SnappyCodec
4.11空值处理
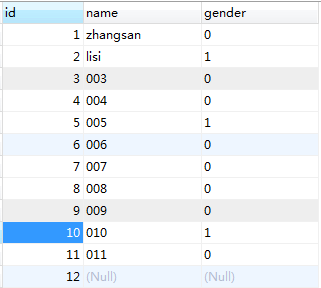
像如图id=12的记录是没有name和gender的,如果不加处理,导入到hdfs上是这样子的:
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
,zhangsan,false
,lisi,true
,,false
,,false
,,true
,,false
,,false
,,false
,,false
,,true
,,false
,null,null
sqoop提供了--null-string来处理字符类型的空值,提供了--null-non-string来处理非字符类型的空值。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --delete-target-dir --target-dir person-mysql -m 1 --table person --null-string "" --null-non-string "false"
执行结果是:
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part*
,zhangsan,false
,lisi,true
,,false
,,false
,,true
,,false
,,false
,,false
,,false
,,true
,,false
,,false
4.12增量传输
增量导入的一个场景就是昨天导入了一批数据,今天又增加了部分数据,现在要把这部分数据也导入到hdfs中。
sqoop import --connect jdbc:mysql://localhost:3306/test --username root --password 123456 --target-dir person-mysql -m 1 --table person --null-string "" --null-non-string "false" --check-column "id" --incremental append --last-value 5
执行结果是:
(my_python_env)[root@hadoop26 ~]# hadoop fs -cat person-mysql/part-m-
,,false
,,false
,,false
,,false
,,true
,,false
,,false
sqoop简单import使用的更多相关文章
- how to use Sqoop to import/ export data
Sqoop is a tool designed for efficiently transferring data between RDBMS and HDFS, we can import dat ...
- hive sqoop,sqoop-hive import data
https://segmentfault.com/a/1190000002532293 https://www.zybuluo.com/aitanjupt/note/209968 create tab ...
- sqoop简单配置与使用
sqoop(sql-to-hadoop) Apache Sqoop是用来实现结构型数据(如关系数据库)和Hadoop之间进行数据迁移的工具.它充分利用了MapReduce的并行特点以批处理的方式加快数 ...
- sqoop简单介绍
一简介 Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS ...
- sqoop简单使用
一,通过sqoop将MySQL里面的数据加载到HDFS 先查看有哪些数据库 查看表person sqoop list-databases --connect jdbc:mysql://ly-p2p4: ...
- Sqoop学习笔记_Sqoop的基本使用二(sqoop的import与export)
Sqoop抽取从mysql抽取到hive sqoop抽取到mysql一样有两种方式一种是用command line的方式,一种是用sqoop opt文件调用的方式.(由于两种sqoop一已经记录了,现 ...
- Using Sqoop to import from db2 to hadoop
参考 : https://stackoverflow.com/questions/23933481/db2-data-import-into-hadoop sqoop import - ...
- Sqoop Import原理和详细流程讲解
Sqoop Import原理 Sqoop Import详细流程讲解 Sqoop在import时,需要指定split-by参数.Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域 ...
- sqoop import mysql to hive table:GC overhead limit exceeded
1. Scenario description when I use sqoop to import mysql table into hive, I got the following error: ...
随机推荐
- 判断DataTable是否为空
DataTable: ) { //为空的操作 } DataRow: if(!DataRow.IsNull("列名")) { //不为空的操作 }
- Oracle 数据类型映射C#
Oracle 数据类型映射 下表列出 Oracle 数据类型及其与 OracleDataReader 的映射. Oracle 数据类型 由 OracleDataReader.GetValue 返回的 ...
- [HDU 5113] Black And White (dfs+剪枝)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5113 题目大意:给你N*M的棋盘,K种颜色,每种颜色有c[i]个(sigma(c[i]) = N*M) ...
- AdapterView的相关知识。
AdapterView集成自ViewGroup,他的主要子类有AbsListView(Listview,GridView),AbsSpinner(Spinner,Gallery). AdapterVi ...
- sql 获取filename
select Substring(ORIGINAL_IMAGE,len(ORIGINAL_IMAGE)-charindex('/',reverse(ORIGINAL_IMAGE))+2,len(ORI ...
- blocksit
<!DOCTYPE html> <html> <head> <title>Sc.Chinaz.Com</title> & ...
- php 通过PATH_SEPARATOR判断当前服务器系统类型
PATH_SEPARATOR是php中的一个预定义常量,我们可以直接echo这个常量,在linux系统中,该常量输出":",在windows系统中,该常量输出";&quo ...
- 剑指Offer:面试题12——打印1到最大的n位数(java实现)
问题描述: 输入数字n,按顺序打印出从1到最大的n位十进制数,比如输入3,则打印出1,2,3一直到最大的3位数即999. 思路1:最简单的想法就是先找出最大的n位数,然后循环打印即可. public ...
- Objective-C的内存管理
一.Objective-C内存管理的对象 1. 值类型:比如int.float.struct等基本数据类型. 值类型会被放入栈中,在内存中占有一块连续的内存空间,遵循先进后出的原则,故不会产生碎片. ...
- JavaScript数据结构,队列和栈
在JavaScript中为数组封装了大量的方法,比如:concat,pop,push,unshift,shift,forEach等,下面我将使用JavaScript提供的这些方法,实现队列和栈的操作. ...