SpringBoot快速插入Mysql 1000万条数据
导读
有时候为了验证系统瓶颈,需要往数据库表中插入大量数据,可以写sheel脚本插入,前几天为了插入100万条数据,走的sheel脚本(点我直达),插入速度简直无法直视,花了3小时,才插入了10万条,后来没辙了,多跑几次sheel脚本(算是多线程操作吧),最终花了4个多小时才插入100万条记录。今天使用java程序快速插入1000万条数据,最终只需要3分钟多一点就搞定了,好了下面开始吧~
添加依赖
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--mybatis plus和spring boot整合-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
<!--Druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<!-- guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>
application.properties
# 端口号
server.port=9999
#===========数据库相关=============
#spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
#spring.datasource.url=jdbc:mysql://127.0.0.1/shop?useUnicode=true&characterEncoding=utf-8&useSSL=false
#spring.datasource.username=root
#spring.datasource.password=root
# mybatis plus下划线转驼峰
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 配置mybatis plus打印sql日志
#mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.datasource.name=mysql_test
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# druid配置
# 监控统计拦截的filters
spring.datasource.druid.filters=stat
spring.datasource.druid.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.druid.url=jdbc:mysql://127.0.0.1/yb_mysql?useUnicode=true&characterEncoding=utf-8&useSSL=false
spring.datasource.druid.username=root
spring.datasource.druid.password=root
#配置初始化大小/最小/最大
spring.datasource.druid.initial-size=1
spring.datasource.druid.min-idle=1
spring.datasource.druid.max-active=20
#获取连接等待超时时间
spring.datasource.druid.max-wait=60000
#间隔多久进行一次检测,检测需要关闭的空闲连接
spring.datasource.druid.min-evictable-idle-time-millis=300000
spring.datasource.druid.validation-query= SELECT 'x'
spring.datasource.druid.test-while-idle=true
spring.datasource.druid.test-on-borrow=true
spring.datasource.druid.test-on-return=false
数据库表结构
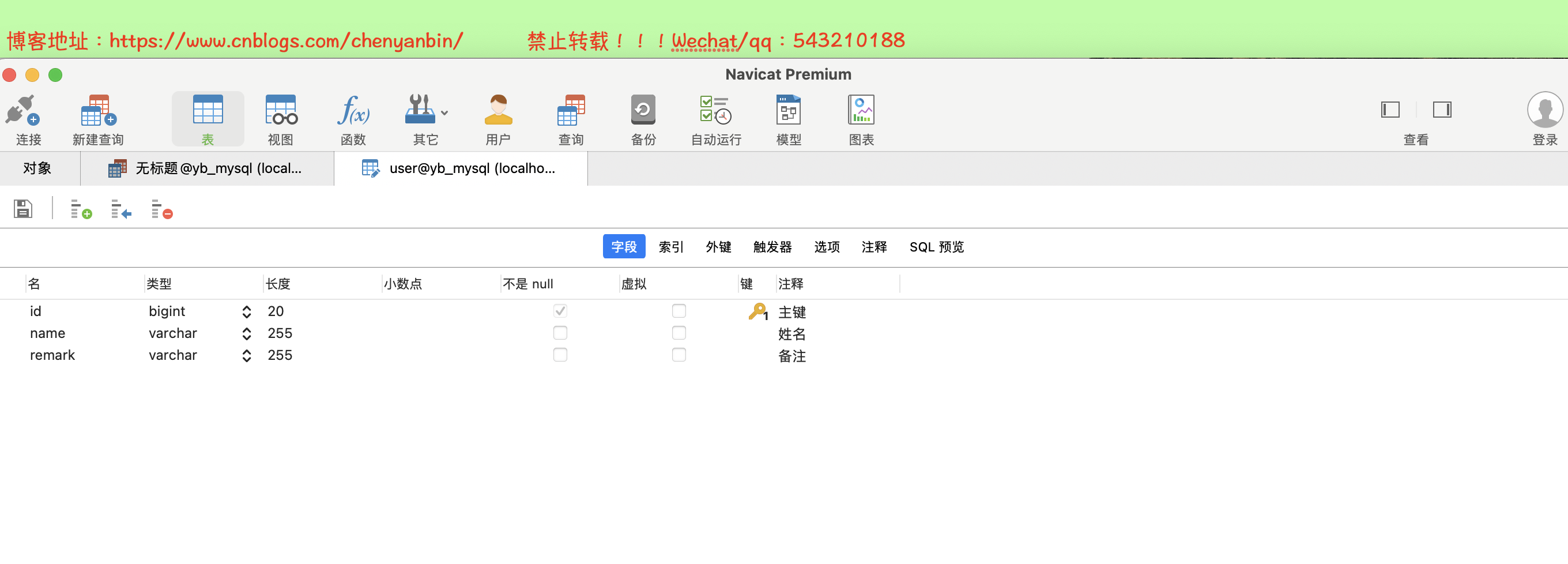
实体类
package com.ybchen.domain; import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.EqualsAndHashCode; import java.io.Serializable; /**
* <p>
* 用户表
* </p>
*
* @author chenyanbin
* @since 2021-11-07
*/
@Data
@EqualsAndHashCode(callSuper = false)
@TableName("user")
public class UserDO implements Serializable { private static final long serialVersionUID = 1L; /**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id; /**
* 姓名
*/
private String name; /**
* 备注
*/
private String remark; }
Mapper
package com.ybchen.mapper; import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.ybchen.domain.UserDO;
import org.apache.ibatis.annotations.Param; import java.util.List; public interface UserMapper extends BaseMapper<UserDO> {
/**
* 批量插入
* @param userList
* @return
*/
int batchInsert(@Param("listUser") List<UserDO> userList);
}
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ybchen.mapper.UserMapper"> <!-- 通用查询映射结果 -->
<resultMap id="BaseResultMap" type="com.ybchen.domain.UserDO">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="remark" property="remark"/>
</resultMap> <!-- 通用查询结果列 -->
<sql id="Base_Column_List">
id, name, remark
</sql> <!-- 批量插入 -->
<insert id="batchInsert">
insert into user (`name`,`remark`)
values
<foreach collection="listUser" item="item" separator=",">
(#{item.name},#{item.remark})
</foreach>
</insert>
</mapper>
Controller
package com.ybchen.controller; import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.google.common.collect.Lists;
import com.ybchen.domain.UserDO;
import com.ybchen.mapper.UserMapper;
import com.ybchen.utils.JsonData;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController; import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch; /**
* @Author:chenyanbin
*/
@RestController
public class UserController {
@Autowired
UserMapper userMapper; @GetMapping("batchInsert")
public JsonData batchInsert() {
int num = 2000;
CountDownLatch latch = new CountDownLatch(1);
List<UserDO> userList = new ArrayList<>();
new Thread(() -> {
for (int i = 0; i < 10000000; i++) {
UserDO userDO = new UserDO();
userDO.setName("陈彦斌====》" + i);
userDO.setRemark("博客地址:https://www.cnblogs.com/chenyanbin/");
userList.add(userDO);
}
latch.countDown();
}).start();
try {
latch.await();
} catch (InterruptedException e) {
}
//2000条为一批,插入1000万条
List<List<UserDO>> partition = Lists.partition(userList, num);
partition.stream().forEach(user -> {
int rows = userMapper.batchInsert(user);
System.err.println("插入数据成功,rows:" + rows);
});
return JsonData.buildSuccess();
} @GetMapping("all")
public JsonData all(){
return JsonData.buildSuccess(userMapper.selectList(new LambdaQueryWrapper<>()));
}
}
项目结构

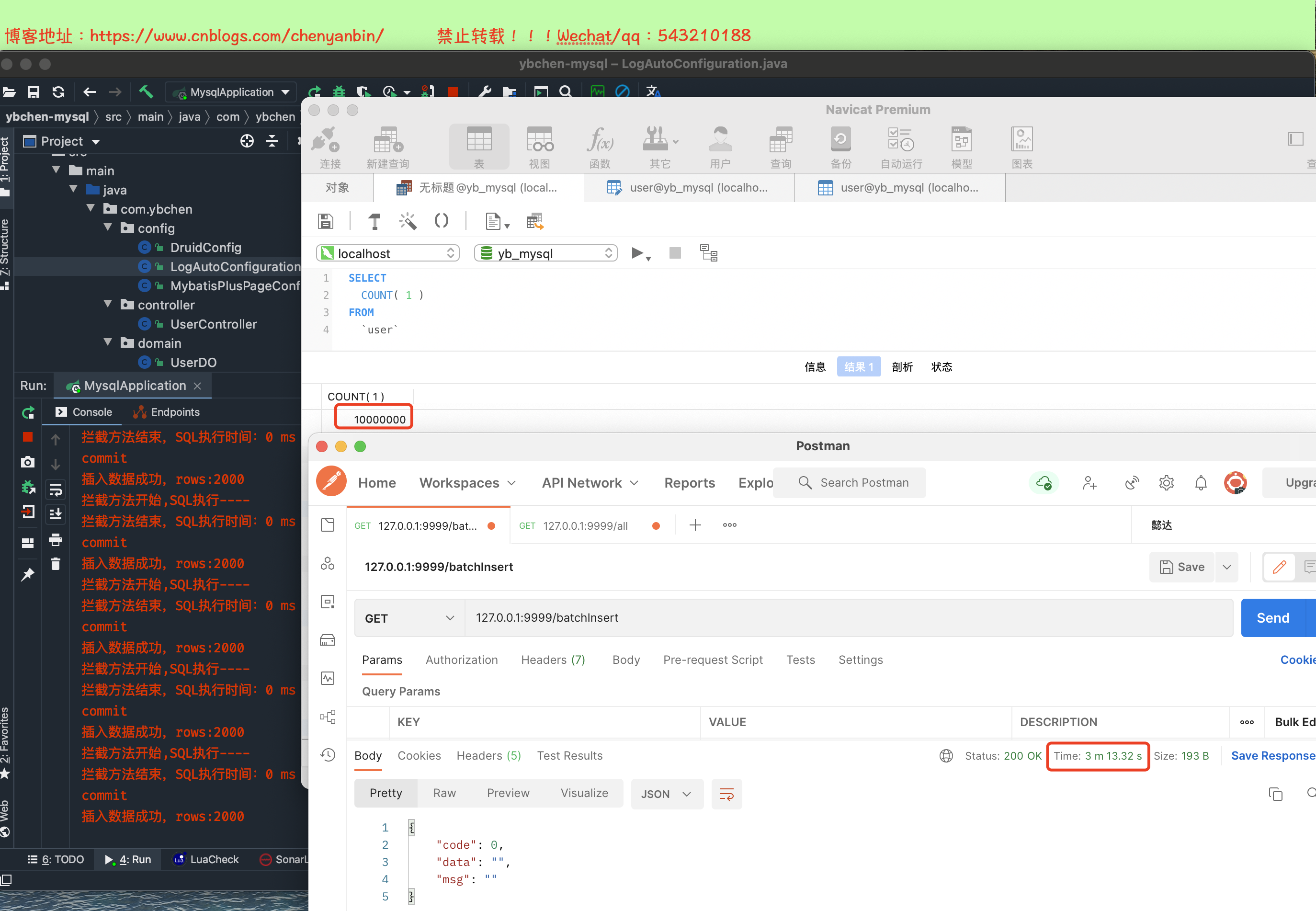
演示

最终耗时
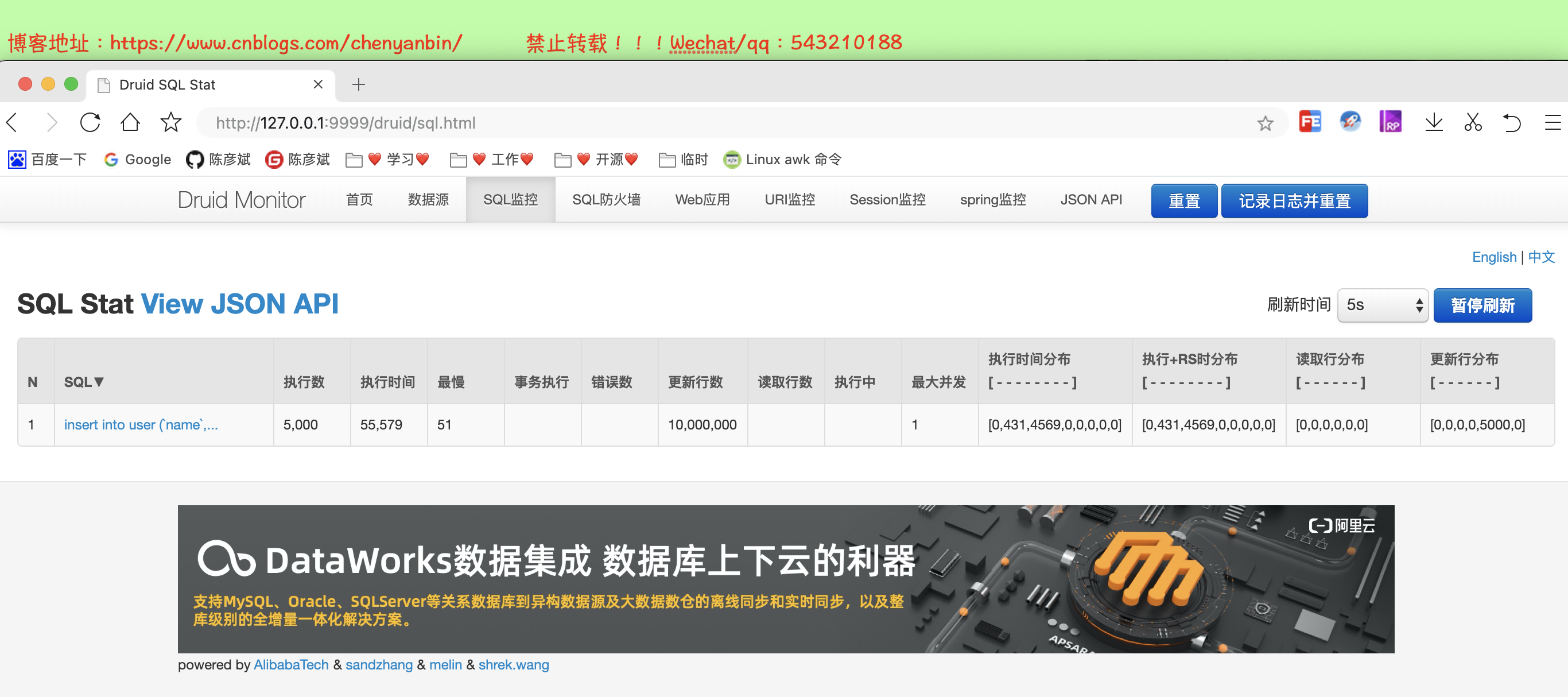
存储过程方式
delimiter ;;
create procedure chenyanbin()
begin
declare i int;
set i=1;
while(i<=3000000)do
insert into test_excel (name1,name2,name3,name4,name5,name6,name7,name8,name9,name10,name11,name12,name13,name14,name15)
values(concat('列1-:',i), concat('列2-:',i), concat('列3-:',i), concat('列4-:',i), concat('列5-:',i), concat('列6-:',i), concat('列7-:',i), concat('列8-:',i), concat('列9-:',i), concat('列10-:',i), concat('列11-:',i), concat('列12-:',i), concat('列13-:',i), concat('列14-:',i), concat('列15-:',i));
set i=i+1;
end while;
end;;
delimiter ;
call chenyanbin();
SpringBoot快速插入Mysql 1000万条数据的更多相关文章
- 绝对干货,教你4分钟插入1000万条数据到mysql数据库表,快快进来
我用到的数据库为,mysql数据库5.7版本的 1.首先自己准备好数据库表 其实我在插入1000万条数据的时候遇到了一些问题,现在先来解决他们,一开始我插入100万条数据时候报错,控制台的信息如下: ...
- 插入1000万条数据到mysql数据库表
转自:https://www.cnblogs.com/fanwencong/p/5765136.html 我用到的数据库为,mysql数据库5.7版本的 1.首先自己准备好数据库表 其实我在插入100 ...
- 1000万条数据导入mysql
今天需要将一个含有1000万条数据的文本内容插入到数据库表中,最初自然想到的是使用Insertinto '表名'values(),(),()...这种插入方式,但是发现这种方式对1000万条数据量的情 ...
- QTreeView处理大量数据(使用1000万条数据,每次都只是部分刷新)
如何使QTreeView快速显示1000万条数据,并且内存占用量少呢?这个问题困扰我很久,在网上找了好多相关资料,都没有找到合理的解决方案,今天在这里把我的解决方案提供给朋友们,供大家相互学习. 我开 ...
- Oracle 快速插入1000万条数据的实现方式
1.使用dual配合connect by level create table BigTable as select rownum as id from dual connect by level & ...
- (C#版本)提升SQlite数据库效率——开启事务,极速插入数据,3秒100万,32秒1000万条数据
SQLite插入数据效率最快的方式就是:开启事务 + insert语句 + 关闭事务(提交) 利用事务的互斥性,如果在批量的插入操作前显式地开启一次事务,在插入操作结束后,提交事务,那么所有 ...
- 教你如何6秒钟往MySQL插入100万条数据!然后删库跑路!
教你如何6秒钟往MySQL插入100万条数据!然后删库跑路! 由于我用的mysql 8版本,所以增加了Timezone,然后就可以了 前提是要自己建好库和表. 数据库test, 表user, 三个字段 ...
- mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式)
mysql快速导入5000万条数据过程记录(LOAD DATA INFILE方式) 首先将要导入的数据文件top5000W.txt放入到数据库数据目录/var/local/mysql/data/${d ...
- Mysql慢查询开启和查看 ,存储过程批量插入1000万条记录进行慢查询测试
首先登陆进入Mysql命令行 执行sql show variables like 'slow_query%'; 结果为OFF 说明还未开启慢查询 执行sql show varia ...
- 使用hibernate在5秒内插入11万条数据,你觉得可能吗?
需求是这样的,需要查询某几个表的数据,然后插入到另外一个表. 一看到需求,很多人都会用hibernate去把这些数据都查询出来,然后放到list中, 然后再用for循环之类的进行遍历,一条一条的取出数 ...
随机推荐
- openstack的用户(user), 租户(tenant), 角色(role)概念区分
用户身份管理有三个主要的概念: 用户Users租户Tenants角色Roles1. 定义 这三个概念的openstack官网定义(点击打开链接) 1.1 用户(User) openstack官网定义U ...
- Linux安装ElastSearch
Linux安装ES 准备好Linux系统,软件安装前需要对当前系统做一些优化配置 系统配置修改 一.内存优化 在/etc/sysctl.conf添加如下内容: fs.file-max=655360 系 ...
- Spring 对 Junit4,Junit5 的支持上的运用
1. Spring 对 Junit4,Junit5 的支持上的运用 @ 目录 1. Spring 对 Junit4,Junit5 的支持上的运用 每博一文案 2. Spring对Junit4 的支持 ...
- winform 关于无边框和拖动窗体边缘改变尺寸的 踩坑笔记
在做美化winform窗体,实现自定义窗体标题栏,圆角边框,并且支持拖拽窗体,最后还要能拖动窗体左.右.下边缘时,改变窗体的宽和高. 一般网上的都有代码,窗体设成无边框,自己加个panel就能实现自定 ...
- CSS——基本选择器
例子: <head> <meta charset="UTF-8"> <title>Title</title> <style&g ...
- 为什么SwiftUI使用struct, 限制使用class
前言 在学习SwiftUI所有的地方,视图元素都定义一个struct并实现View协议,该协议定义body变量返回View类型. 但是为什么,这里一直是指定的struct, 而不是class呢? 尝试 ...
- Xcode 最近使用的一些问题
1.上架的App如何测试推送? 苹果的证书分为开发证书和发布证书,上架AppStore的App应该使用发布证书进行配置,但是发布证书编译出包的App无法安装到手机上 只有一种方式,采用Ad hoc p ...
- C++笔记(12) 标准模板库STL
STL提供了一组表示容器.迭代器.函数.函数对象和算法的模板.STL不是面向对象的编程,而是一种不同的编程模式--泛型编程. 容器:与数组类似的单元,可以存储若干个值,存储的值的类型相同: 算法:完成 ...
- java中以字符分隔的字符串与字符串数组的相互转换
1.字符串数组拼接成一个以指定字符(包括空字符)分隔的字符串--String.join(),JDK8的新特性 String[] strArray = {"aaa","bb ...
- css球体
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8 ...