(Nosql)列式存储是什么?
首先nosql可以被理解为not only sql 泛指非关系型数据库,也就是说不仅仅是sql,所以它既包含了sql的一些东西,但是又和sql不同,并在其的基础上改变或者说扩展了一些东西。
提到nosql,首先我们就要分析一下关系型数据库的行式存储和非关系型数据库的列式存储区别在哪?
行式存储我们都很熟悉,不论是mysql数据表还是我们熟悉的excel表,这些表里每一行都是完整的一条数据,它们彼此关联,彼此有关系。
以核酸检测的数据为例:
行式存储
一般核酸检测需要以下几个字段:姓名、身份证号、检测机构、检测时间、结果、价格
比如是这样的:
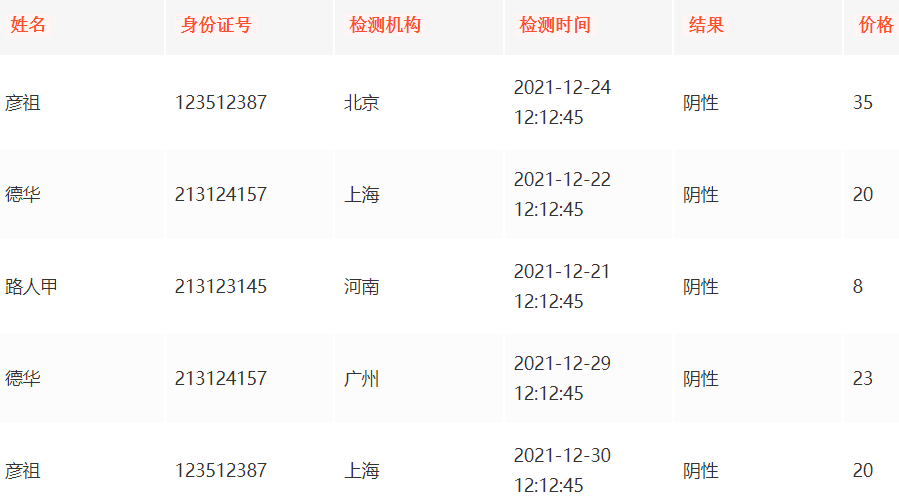

行存储优点分析
- 在这样的物理结构下,因为是连续空间,所以插入一条数据只需要追加到当前数据之后即可,很方便
- 对于按记录查询也很方便,例如:我们要查询彦祖的所有核酸记录,页面应用的话应该是通过彦祖的身份证号
- 对应的sql如下:
select * from 核酸记录表 where 身份证号='彦祖的身份证号'
- 这个sql的执行流程比较清晰
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
- 这样就可以快速得到彦祖的核酸记录
行存储缺点分析
- 这时候,业务方提了一个需求,他要统计彦祖做核酸总共花了多少钱
- 对于这个需求,sql实现也很简单,通过对
价格列sum就可以实现,sql如下:
select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
- 这个sql的执行流程也比较清晰
1.先从索引查询出来彦祖的记录存储的物理地址
2.在通过物理地址去表的物理存储中查询对应地址中的数据
3.拿到所有数据时候,再通过对于价格列sum聚合得到结果
- 分析下,因为行存储使用的是连续空间,即使需求里面只需要
select sum(价格),但是读取物理存储时候,还是读取出来了所有的字段
行存储优缺点总结
- 通过上面的分析,总结一下行存储的优缺点
优点:
1.连续空间对于插入/更新很方便
2.对于记录查询很方便
缺点
1.会查询出来很多不需要的列
列式存储
- 在列存储中,对于同样的核酸记录表,存储的物理结构如下:

- 在列式存储中,会把每一列存储到一起,如
姓名列,是把所有记录中的姓名这列的值使用连续空间存放到一起 - 而对于各个列之间,是没有必要使用连续空间存放到一起的,所以很多列式数据库都使用了分布式存储的方式,存储各个列
- 下面我们来分析下列存储的
数据压缩和查询执行流程
列存储的数据压缩
- 很多列式数据库都是通过
字典表的方式进行数据压缩 - 因为是把每一列存放到一起的,所以很容易通过对于每一列进行去重,来构建一个字典表,例如:
- 对于
姓名列,这列的所有数据如下:
彦祖|德华|路人甲|德华|彦祖
对这列值去重以后,构建一张
姓名列字典表,构建算法忽略,就使用自增id的方式,如下:id姓名列1 彦祖 2 德华 3 路人甲 这样构建字典表,对于列存储的物理存储结构,就可以执行存储字典表中的id,而不用存储具体的值,有了字典表以后
姓名列存储如下:
1|2|3|2|1
- 同样对于
价格列,这列的所有数据如下:
35|20|8|23|20
对这列值去重以后,构建一张
价格列字典表,构建算法忽略,就使用自增id的方式,如下:id价格列1 35 2 20 3 8 4 23 有了字典表以后
价格列存储如下:
1|2|3|4|2
- 这样通过一些数据压缩算法等,可以对数据存储进行压缩
列存储的查询执行过程
- 有字典表以后,我们来看下,列存储一般是如何进行查询的
- 业务需求查询
彦祖,20块钱做的核酸记录:
select * from 核酸记录表 where 姓名=彦祖 and 价格=20
- 对于该sql,执行过程如下:
1.对于where 姓名=彦祖
首先查询姓名字典表,查询到彦祖的id=1
id |
姓名列 |
|---|---|
| 1 | 彦祖 |
| 2 | 德华 |
| 3 | 路人甲 |
2.通过查询到彦祖的id,对于性名列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
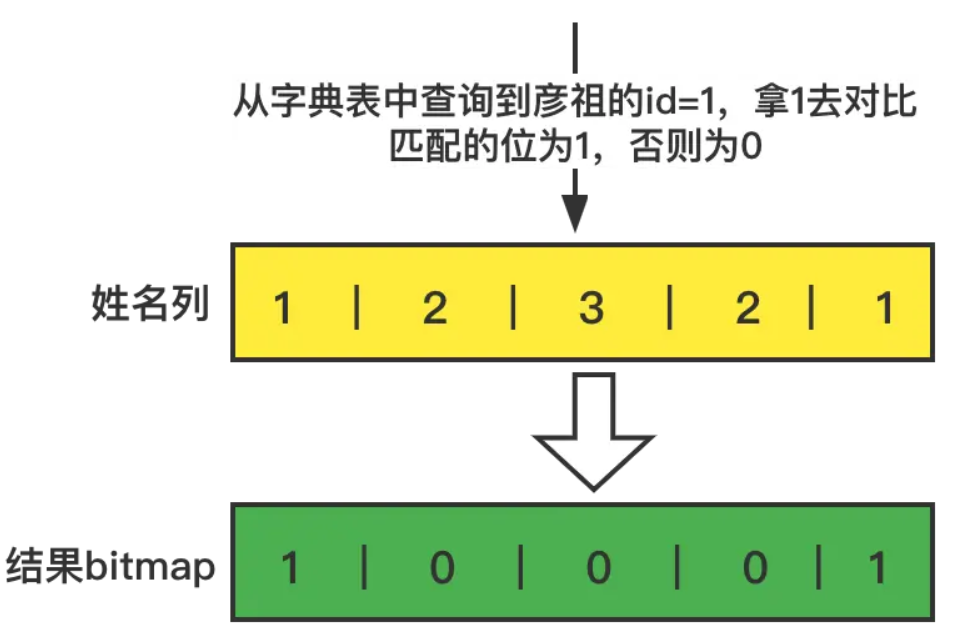
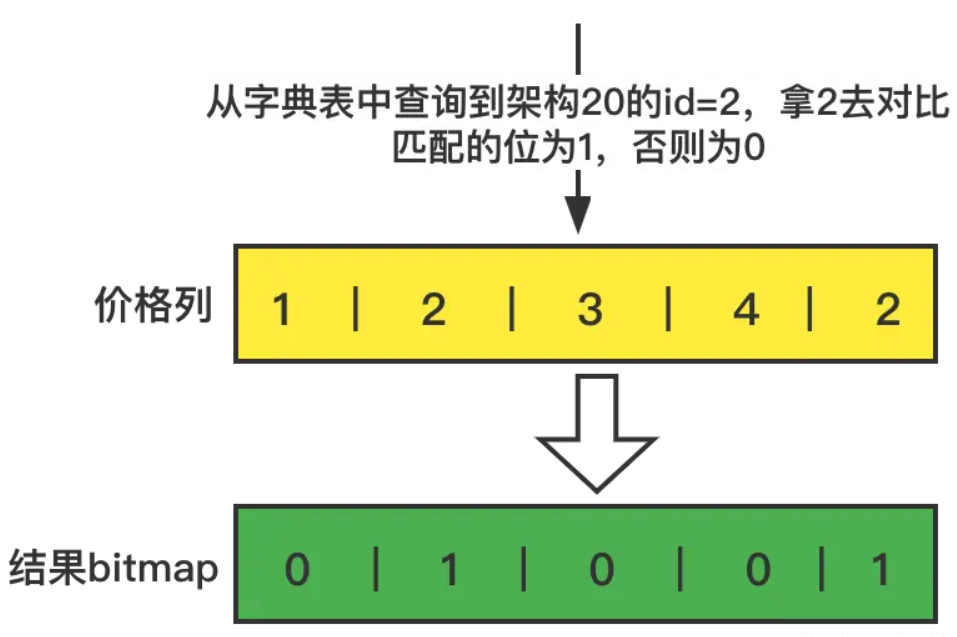
3.对于where 价格=20 和上面一样的操作,先查询价格字段表,20 的id=2
id |
价格列 |
|---|---|
| 1 | 35 |
| 2 | 20 |
| 3 | 8 |
| 4 | 23 |
4.通过查询到价格20的id,对于价格列进行对比,构建一个bitmap,把匹配的要的列的索引位设置为1,否则为0
5.对于两个where条件的结果bitmap做与运算,bitmap中,位为1的索引就是要查询数据的所有列的索引,如该例子中,两个结果bitmap与运算后的结果是00001,所以所有列的第5个值,拼接起来就是我们要查询的数据。
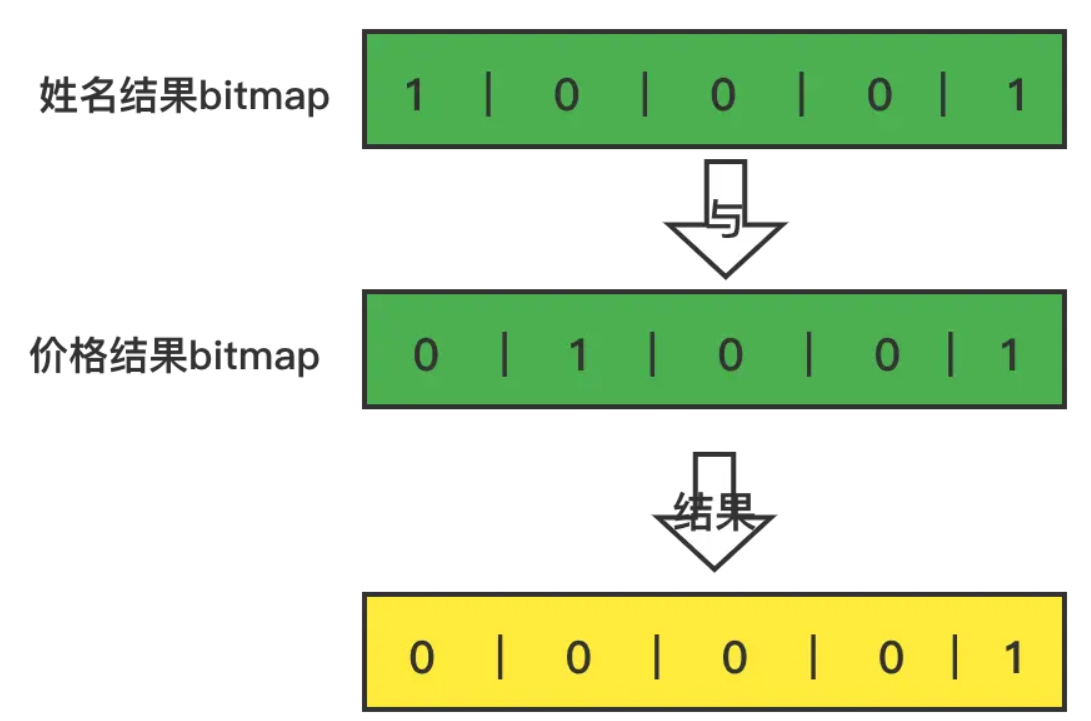
6.所以我们把所有列的第五个值拿出来组装后就是我们需要的数据
列存储优点分析
- 上面讲了列存储的
数据压缩,在数据压缩上列存储有一定的优势 - 每一列都可以天然做索引,不需要额外的数据结构来对各个列构建索引,所以不用在意每一列的数据类型,都可以做索引
- 对于统计彦祖做核酸总共花了多少钱这种需求
select sum(价格) from 核酸记录表 where 身份证号='彦祖的身份证号'
- 因为列是
分开存储的,按照上面讲的查询流程,其实最后我们得到的结果bitmap,拿到位=1的索引后,我们不需要查询所有的列,只需要拿着索引去价格列中获取相应位置的值,然后在进行sum聚合
列存储缺点分析
- 因为各个列是分开存储的,所以在插入、更新时,需要对于
每一个列进行操作,没有行存储连续空间那么方便 - 还是看上面说的查询过程,每次查询过后,都需要对查询到的需要的列进行一个数据组装
列存储优缺点总结
- 通过上面的分析,总结一下列存储的优缺点
优点:
1.数据压缩比较有优势
2.任何列都可以做索引
3.查询时只有涉及到的列会被读取
缺点
1.每次查询时,都需要对查询到的列进行数据重新组装
2.插入/更新操作比较困难
参考自:https://juejin.cn/post/7056820168239874062
(Nosql)列式存储是什么?的更多相关文章
- 列式存储(三)JFinal DB.tx()事务
上一篇中说道了列式存储中新增表单时后台接收数据问题,在存入数据库时一次插入多条数据,就要用到事务. JFinal中有个封装好的事务应用,用起来非常方便简单. 写法1: Db.tx(new IAtom( ...
- 列式存储(二)JFinal如何处理从前台传回来的二维数组
上一篇说到了列式存储,这一篇说它的存储问题,将每个模块的所有属性字段单独存到一张表中,新增页面时,所有的字段都去数据库请求,这样多个模块的新增功能可以共用一个jsp.由于每个模块的字段个数不一样,有的 ...
- 列式存储 V.S. 行式存储
列式数据库 http://zh.wikipedia.org/wiki/%E5%88%97%E5%BC%8F%E6%95%B0%E6%8D%AE%E5%BA%93 列式存储与行式存储 http://my ...
- HBase 是列式存储数据库吗
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库. 行式数据库和列式数据库 在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行 ...
- 开源列式存储引擎Parquet和ORC
转载自董的博客 相比传统的行式存储引擎,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐(注:列式存储不是万能高效的,很多场景下行式存储仍更加高效),尤其是在数据列(column)数很多,但每次 ...
- oracle 12c 列式存储 ( In Memory 理论)
随着Oracle 12c推出了in memory组件,使得Oracle数据库具有了双模式数据存放方式,从而能够实现对混合类型应用的支持:传统的以行形式保存的数据满足OLTP应用:列形式保存的数据满足以 ...
- 【HBase】与关系型数据库区别、行式/列式存储
[HBase]与关系型数据库区别 1.本质区别 mysql:关系型数据库,行式存储,ACID,SQL,只能存储结构化数据 事务的原子性(Atomicity):是指一个事务要么全部执行,要么不执行,也就 ...
- 为什么列式存储会被广泛用在 OLAP 中?
大家好,我是大D. 不知是否有小伙伴们疑问,为什么列式存储会广泛地应用在 OLAP 领域,和行式存储相比,它的优势在哪里?今天我们一起来对比下这两种存储方式的差别. 其实,列式存储并不是一项新技术,最 ...
- 【大数据面试】sqoop:空值、数据一致性、列式存储导出、数据量、数据倾斜
一.有没有遇到过问题,怎么进行解决的 1.空值问题 本质:hive底层存储空数据使用\n<==>MySQL存储空数据使用null 解决:双向导入均分别使用两个参数☆,之前讲过 2.数据一致 ...
- [转载] 【每周推荐阅读】C-Store:列式存储数据库
Record-based与column-based是数据库和存储系统里面两种不同的data layout.我们的思维逻辑是基于行记录的,即Record-based data layout,数据记录都是 ...
随机推荐
- SpringBoot+MyBatisPlus+Thymeleaf+AdminLTE增删改查实战
说明 AdminLTE是网络上比较流行的一款Bootstrap模板,包含丰富的样式.组件和插件,非常适用于后端开发人员做后台管理系统. 因为最近又做了个后台管理系统,这次就选的是AdminLTE做主题 ...
- 开源开发者的狂欢,STRK开了一个好头!附领取价值800元的web3空投教程
这两天在Github和推特上最热闹的事情便是知名ETH(以太坊)二层公链项目STRK给所有gtihub上排名前5000的开源项目的项目贡献者提供了价值800元的代币空投,其中不乏前端程序员.大学生等w ...
- SpringBoot整合Groovy脚本,实现动态编程
Groovy简介 Groovy 是增强 Java 平台的唯一的脚本语言.它提供了类似于 Java 的语法,内置映射(Map).列表(List).方法.类.闭包(closure)以及生成器.脚本语言不会 ...
- 【Android逆向】破解看雪test3.apk方案二
方案二就是要hook那三个条件,不让追加字符串变成false v20 = "REAL"; clazz = _JNIEnv::FindClass(env, "android ...
- 【架构师视角系列】QConfig配置中心系列之Client端(二)
目录 声明 配置中心系列文章 一.架构 一.客户端架 1.Server 职责 (1)配置管理 (2)配置发布 (3)配置读取 2.Client 职责 (1)配置拉取 (2)配置注入 (3)配置变更监听 ...
- Vue 3 的 setup语法糖到底是什么东西?
前言 我们每天写vue3项目的时候都会使用setup语法糖,但是你有没有思考过下面几个问题.setup语法糖经过编译后是什么样子的?为什么在setup顶层定义的变量可以在template中可以直接使用 ...
- 【Docker】.Net Core 结合Nlog集成ELK框架(Elasticsearch , Logstash, Kibana) (五)
之前有项目有用过ELK做过日志架构,不过是非docker形式安装的,今天来探究一下ELK的容器化技术 Elasticsearch 是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动 ...
- 【LeetCode链表#8】翻转链表(双指针+递归)/K个一组翻转
翻转链表 力扣题目链接(opens new window) 题意:反转一个单链表. 示例: 输入: 1->2->3->4->5->NULL 输出: 5->4-> ...
- 【Azure Function】开启Azure Function输出详细Debug日志 ( --verbose)
When func.exe is run from VS, it suggests "For detailed output, run func with --verbose flag.&q ...
- 【Azure 环境】当本地网络通过ER专线与Azure云上多个虚拟网络打通,如何通过特定的网络策略来限制本地部分网段访问云上虚拟机22端口?
问题描述 当本地网络通过ER专线与Azure云上多个虚拟网络打通,如何通过特定的网络策略来限制本地部分网段访问云上虚拟机22端口? 问题回答 根据文档调研,在ER线路服务的层面,是无法做网络策略来限制 ...