【论文阅读】RAL 2022: Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions
参考与前言
Status: Finished
Type: RAL
Year: 2022
论文链接:https://www.ipb.uni-bonn.de/wp-content/papercite-data/pdf/mersch2022ral.pdf
代码链接:https://github.com/PRBonn/4DMOS
1. Motivation
在自动驾驶导航中 dynamics obstacle 对于轨迹规划很重要,所以如何识别动态障碍物是一个比较重要的问题
问题场景
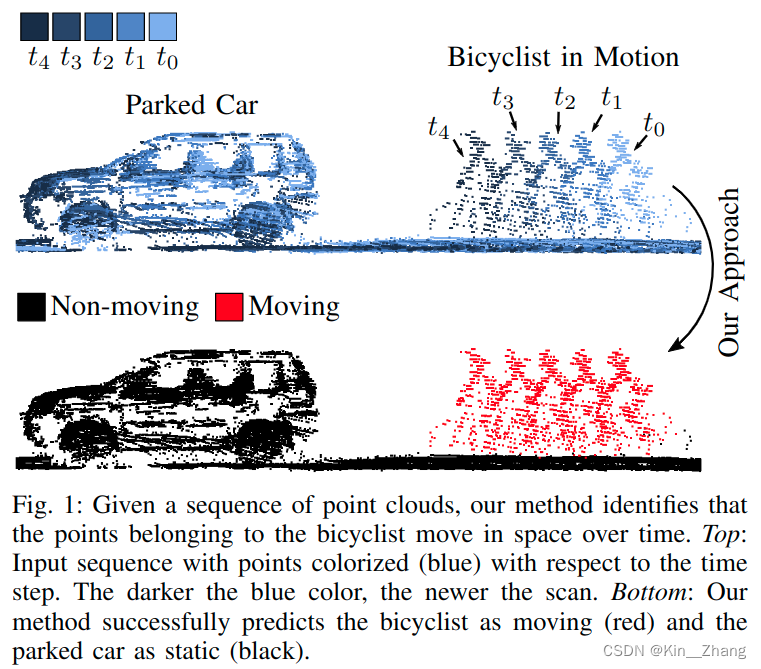
现有方法:
- 使用BEV角度的LiDAR Image进入2D Conv CNN进行提取 temporal info,通常这种 projection 2D表示 是从3D里聚类 比如 kNN
- 在建图过程中,根据聚类和tracking进行检测 运动点云
以上方法都是offline 需要时间内所有的LiDAR;其他方法也有对比两相邻帧点云的
本文方法主要focus on object that in a limited time horizon
Contribution
可以通过short sequence的LiDAR信息预测moving objects
exploit sparse 4D Conv 从LiDAR点云中提取时空特征。方法输出:每个点云是否是动态物体的confidence scores,设计了一个一定大小的滑动窗口,超过一定删除旧frame
- 比现有方法 更精准的识别动态物体
- 对于unseen的场景有好的泛化性
- 通过在线新的观测输入,改进已知结果
2. Method
前提假设:已知所有帧帧之间的translation matrix \(\boldsymbol T\),point点表示 \(\boldsymbol{p}_{i}=\left[x_{i}, y_{i}, z_{i}, t_i\right]^{\top}\) ,因为室外的点云较为稀疏,所以将4D点云到sparse voxel grid,时间和空间的resolution分别为 \(\Delta t, \Delta s\)
使用一个稀疏的tensor保存voxel grid的indices和相关features
2.1 框架
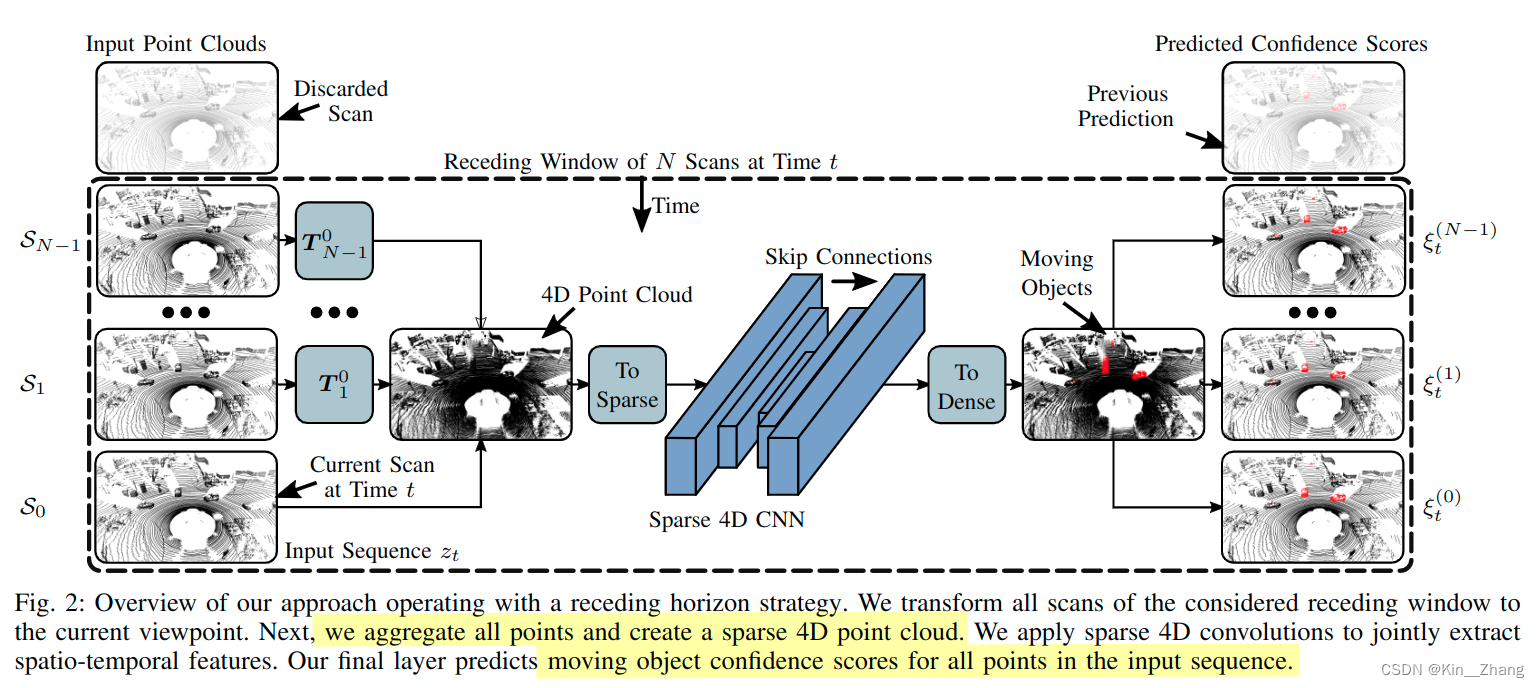
2.2 Sparse 4D
稀疏4D卷积使用的是:Minkowski engine, NVIDIA做的一款开源的稀疏张量的自动微分库,比起dense conv,主要是为了加速
使用的是修改后的 MinkUNet14 [8],a sparse equivalent of a residual bottleneck architecture with strided sparse convolutions for downsampling the feature maps and strided sparse transpose convolutions for upsampling
不同于4D分割使用RGB作为input features,本文首先初始化voxels,被至少一个点占据时constant feature是0.5;因此我们的输入仅保存有点占据的voxel
这样部署到新环境下,不需要再考虑coordinates distribution或是通过intensity value对输入数据进行标准化了
下面为源码抽取的代码 进行的数据处理和sparse:
quantization = self.quantization.type_as(past_point_clouds[0])
past_point_clouds = [
torch.div(point_cloud, quantization) for point_cloud in past_point_clouds
]
features = [
0.5 * torch.ones(len(point_cloud), 1).type_as(point_cloud)
for point_cloud in past_point_clouds
]
coords, features = ME.utils.sparse_collate(past_point_clouds, features)
tensor_field = ME.TensorField(
features=features, coordinates=coords.type_as(features)
)
sparse_tensor = tensor_field.sparse()
predicted_sparse_tensor = self.MinkUNet(sparse_tensor)
2.3 Receding Horizon
经过上面的步骤后,网络会输出每个输入序列点上的confidence score。在实际运行网络时 inference time,避免重复输出同一帧的,一般是选择将输入数据进行切分固定;本文则是采取receding horizon,接收新的 就扔旧的 如上框架图
2.4 Binary Bayes Filter
本文的方法是直接预测的N个scan的输入,输出一个结果,receding horizon则可以通过接收新的一帧,re-estimate 前N-1的scans;对于多次预测结果我们使用binary bayes filter进行融合
贝叶斯融合层可以减少因为传感器噪音或被遮挡住时,输出错误的 false positive和negatives的数量

我们想预测的是 所有点在整个时间内对 motion state \(m^{(j)}\) 的联合概率:
\]
\(m^{(j)} \in \{0,1\}\) 表示 点 \(p_i \in S_j\)的状态是否是moving,\(S_j\)为第j次扫描的LiDAR输入,后面的公式为了简洁点 把j就省去了哈
我们使用bayes’ rule在公式2上,然后follow standard derivation of the recursive binary bayes filter [36],下面的l为\(l(x)=\log \frac{p(x)}{1-p(x)}\) 通常在占用栅格地图上使用,如下进行更新:
\]
prior probability \(p_0 \in (0,1)\) provides a measure of the innovation introduced by a new prediction. 这个值同样决定了how much 在单帧内的一个 predicted moving point 对于最后的prediction造成的影响
为网络输出的scores对应到上面moving的概率
\]
则log-odds confidence的指数为:
\]
然后经过公式3等,取回概率 \(p(x)=\log \frac{l(x)}{1+l(x)}\) 如果这个confidence score大于0.5 则认为这个点是移动的 反之是静止
代码对应
# Bayesian Fusion
elif strategy == "bayes":
for pred_idx, confidences in tqdm(dict_confidences.items(), desc="Scans"):
confidence = np.load(confidences[0])
log_odds = prob_to_log_odds(confidence)
for conf in confidences[1:]:
confidence = np.load(conf)
log_odds += prob_to_log_odds(confidence)
log_odds -= prob_to_log_odds(prior * np.ones_like(confidence))
final_confidence = log_odds_to_prob(log_odds)
pred_labels = to_label(final_confidence, semantic_config)
pred_labels.tofile(pred_path + "/" + pred_idx.split(".")[0] + ".label")
verify_predictions(seq, pred_path, semantic_config)
def to_label(confidence, semantic_config):
pred_labels = np.ones_like(confidence)
pred_labels[confidence > 0.5] = 2
pred_labels = to_original_labels(pred_labels, semantic_config)
pred_labels = pred_labels.reshape((-1)).astype(np.int32)
return pred_labels
3. 实验及结果
消融实验做的挺多,很仔细的,metric主要是针对运动物体所在的点的IoU
\]
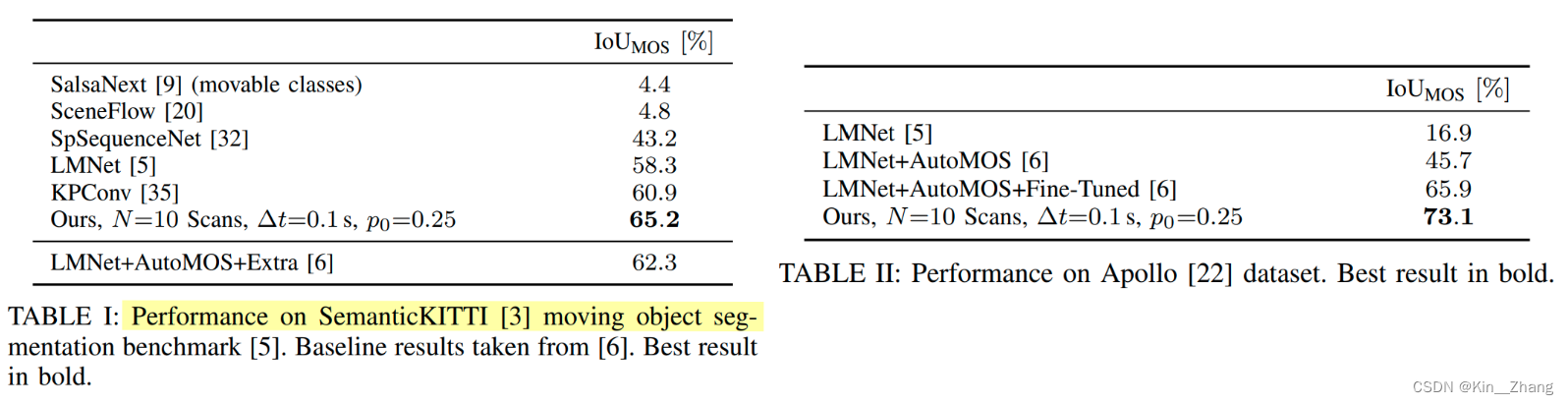
上面提到的\(p_0\)的赋值会产生IoU值的不同
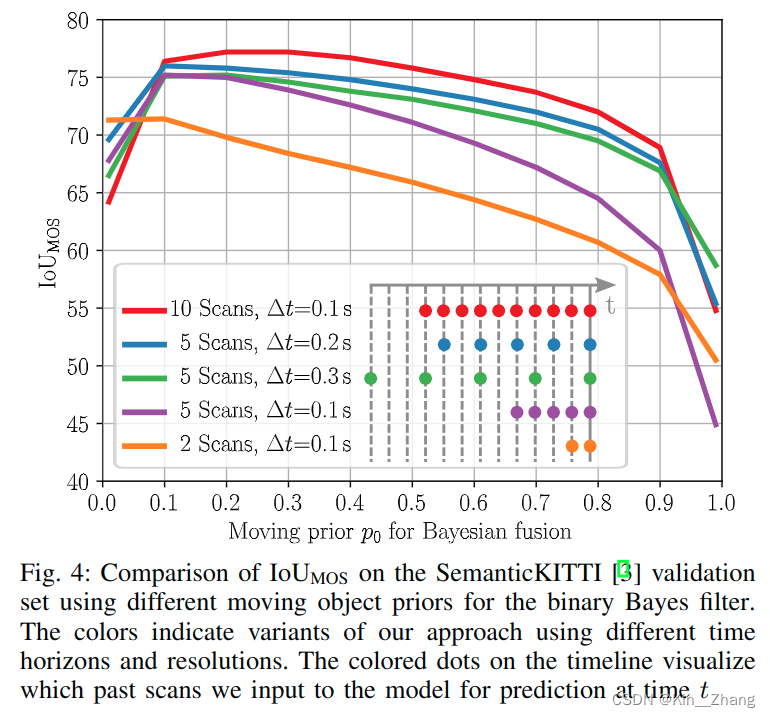

其中表三的\(\Delta t\) 为不同的时间分辨率下
对于运行的时间也有讨论,Python运行,整个网络如果是10次scans的话平均是0.078s,5次scans的话0.047s 在NVIDIA RTX A5000;bayes filter分别需要0.008s 0.004s对于10和5次
4. Conclusion
重复一下方法和contribution部分:
使用receding horizon对输入序列进行动态障碍物的预测,同时结合了binary bayes filter在时间维度上对预测结果进行融合,增加鲁棒性
未来工作可以在于里程计上的优化,因为在本文讨论时,里程计设置为已知状态。
赠人点赞 手有余香 ;正向回馈 才能更好开放记录 hhh
【论文阅读】RAL 2022: Receding Moving Object Segmentation in 3D LiDAR Data Using Sparse 4D Convolutions的更多相关文章
- 论文阅读之 DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation
DECOLOR: Moving Object Detection by Detecting Contiguous Outliers in the Low-Rank Representation Xia ...
- 论文阅读 | FCOS: Fully Convolutional One-Stage Object Detection
论文阅读——FCOS: Fully Convolutional One-Stage Object Detection 概述 目前anchor-free大热,从DenseBoxes到CornerNet. ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记九:SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS (DeepLabv1)(CVPR2014)
论文链接:https://arxiv.org/abs/1412.7062 摘要 该文将DCNN与概率模型结合进行语义分割,并指出DCNN的最后一层feature map不足以进行准确的语义分割,DCN ...
- 论文阅读笔记二十四:Rich feature hierarchies for accurate object detection and semantic segmentation Tech report(R-CNN CVPR2014)
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn 摘要 在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
- 论文阅读 | FoveaBox: Beyond Anchor-based Object Detector
论文阅读——FoveaBox: Beyond Anchor-based Object Detector 概述 这是一篇ArXiv 2019的文章,作者提出了一种新的anchor-free的目标检测框架 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文笔记:Capsules for Object Segmentation
Capsules for Object Segmentation 2018-04-16 21:49:14 Introduction: ----
- DeconvNet 论文阅读理解
学习语义分割反卷积网络DeconvNet 一点想法:反卷积网络就是基于FCN改进了上采样层,用到了反池化和反卷积操作,参数量2亿多,非常大,segnet把两个全连接层去掉,效果也能很好,显著减少了参数 ...
随机推荐
- 学会使用 NumPy:基础、随机、ufunc 和练习测试
NumPy NumPy 是一个用于处理数组的 Python 库.它代表"Numerical Python". 基本 随机 ufunc 通过测验测试学习 检验您对 NumPy 的掌握 ...
- 钉消息Markdown语法
支持的Markdown语法 1 标题 2 # 一级标题 3 ## 二级标题 4 ### 三级标题 5 #### 四级标题 6 ##### 五级标题 7 ###### 六级标题 8 9 引用 10 &g ...
- Dash 2.17版本新特性介绍
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/dash-master 大家好我是费老师,不久前Dash发布了其2.17.0版本,执行下面的命令进行最 ...
- Canvas简历编辑器-我的剪贴板里究竟有什么数据
Canvas图形编辑器-我的剪贴板里究竟有什么数据 在这里我们先来聊聊我们究竟应该如何操作剪贴板,也就是我们在浏览器的复制粘贴事件,并且在此基础上聊聊我们在Canvas图形编辑器中应该如何控制焦点以及 ...
- 莫队算法(基础莫队)小结(也做markdown测试)
莫队 基础莫队 本质是通过排序优化了普通尺取法的时间复杂度. 考虑如果某一列询问的右端点是递增的,那么我们更新答案的时候,右指针只会从左往右移动,那么i指针的移动次数是$O(n)$的. 当然,我们不可 ...
- 如果win报错无法加载文件 C:\Users\xx\AppData\Roaming\npm\pnpm.ps1,因为在此系统上禁止运行脚本
点击查看代码 Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
- Vue 3指令与事件处理
title: Vue 3指令与事件处理 date: 2024/5/25 18:53:37 updated: 2024/5/25 18:53:37 categories: 前端开发 tags: Vue3 ...
- Maven到底是什么
Maven 是一个项目管理工具,它最主要的两个功能就是:依赖管理和项目构建. 何为依赖管理 在传统项目中,我们的项目如果需要第三方提供的库就必须得去官网上下载,有了Maven我们只需要在pom文件 ...
- Django中的ORM转换为SQL语句日志
如果想打印ORM转换过程中的SQL,需要在settings中进行如下配置: LOGGING = { 'version': 1, 'disable_existing_loggers': False, ' ...
- RDP 端口转发 多窗口运行
需要设置本机的默认端口进行修改 优点:(1)部署简单.Windows自带,支持IPv4和IPv6(2)不用重启机器,还长记性.命令即时生效,重启系统后配置仍然存在.缺点:(1)不支持UDP(2)XP/ ...