Colocate Join :ClickHouse的一种高性能分布式join查询模型
摘要:本文将介绍业界MPP分布式数据库join查询模型,以及ClickHouse的分布式查询原理解析和Colocate join性能表现。
本文分享自华为云社区《ClickHouse一种高性能分布式join查询模型(Colocate Join)》,作者:tiantangniao 。
ClickHouse是一款开源的面向联机分析处理的列式数据库,具有极致的压缩率和极速查询性能。ClickHouse支持SQL查询,基于大宽表的聚合分析查询性能非常优异,在特定场景下ClickHouse也具备较优的join性能。本文将介绍业界MPP分布式数据库join查询模型,以及ClickHouse的分布式查询原理解析和Colocate join性能表现。
1. ClickHouse分布式join
ClicHouse分布式join通常涉及到左右表为分布式表,分布式执行过程中需要将数据在节点间进行交换,我们将数据在节点间交换的动作在分布式执行计划中称为数据的流动streaming算子,ClickHouse支持的streaming算子有如下三种:
- Broadcast Join
- Shuffer Join
- Colocate Join
以上第一种其实是数据广播算子,第二种为数据重分布算子,第三种为数据在本地不需要分布式交换。其实对于ClickHouse来说,说是实现了Shuffle JOIN比较勉强,其只实现了类Broadcast JOIN类型,ClickHouse的当前的分布式join查询框架更多的还是实现了两阶段查询按任务(这里不详细讲解,后续几个章节分别进行展开讲解,大家可以体会),业界MPP数据库分布式join查询框架模型的数据在节点间交换Streaming算子通常为以下几种:
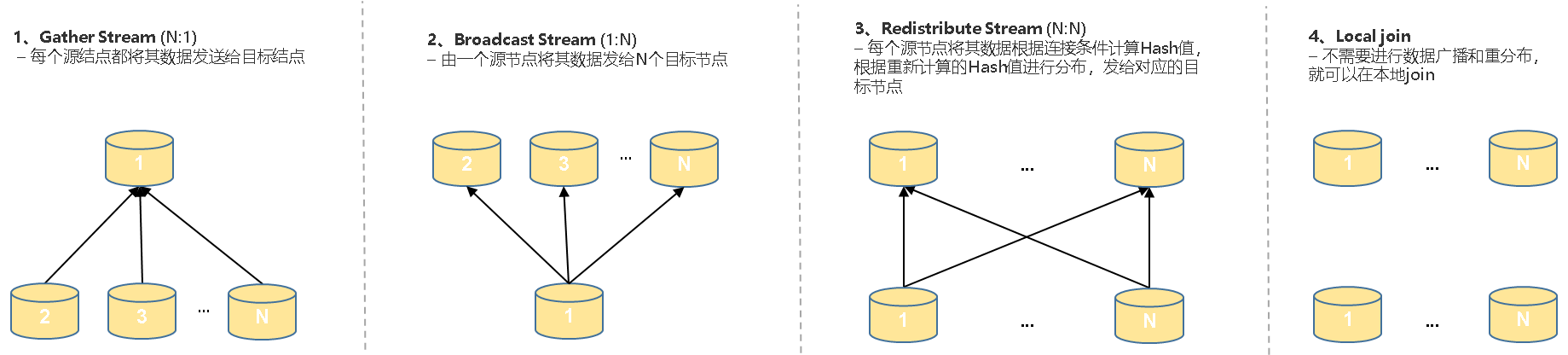
第一种Gather算子类似于在ClickHouse中的SQL发起initiator节点,第一阶段在各个节点完成本地join后,会将各节点结果发送给initiator节点进行第二阶段的汇总工作,initiator节点再讲结果发送给客户端;第二种为数据广播,单个节点将自己拥有的数据发送给目标节点,对应到ClickHouse为Broadcast JOIN;第三种为数据重分布,数据重分布会将数据按照一定的重分布规则发送到对应的目标节点,对应到ClickHouse为Shuffer JOIN;最后一种数据会在本地进行join,对应到ClickHouse为Colocate join,其不需要数据重分布或广播,节点间和网络上无数据交换和传播,此实现方式的join性能也最佳。以下分别将几种join方式在ClickHouse中实现方式进行介绍。
1.1 Shuffer Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
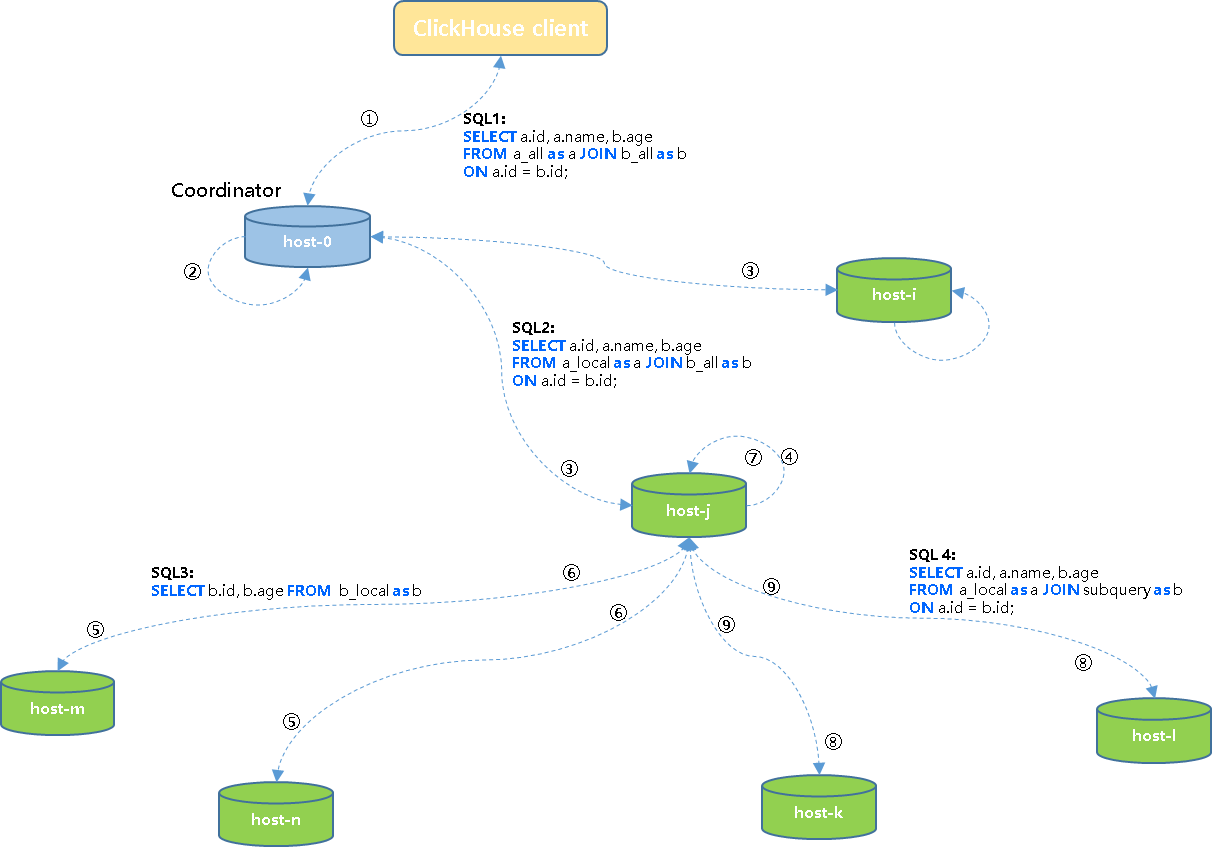
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2查询任务;
③ Coordinator节点将SQL2查询任务下发到集群各个节点执行;
④ 各节点将SQL2解析为SQL3子查询;
⑤ 子查询被下发到所有节点执行;
⑥ 子查询执行完成后将结果集返回到协调节点,如:host-j;
⑦ 协调节点将各个子结果集汇总为一个结果集;
⑧ 协调节点将结果集发送到集群各个节点,同时将SQL4任务下发到各个节点执行;
⑨ 各节点在本地将左表的分片和右表子查询结果集进行join计算,然后将结果返回到客户端。
3)总结:
- ClickHouse 普通分布式JOIN查询并未按JOIN KEY去Shuffle数据,而是每个节点全量拉取右表数据跟左表分片进行join计算;
- 如果右表为分布式表,则集群中每个节点会去执行分布式查询,查询会存在一个非常严重的读放大现象。假设集群有N个节点,右表查询会在集群中执行N*N次;
- ClickHouse 的这种join方式和业界MPP的区别:虽然是叫做Shuffle join/redistribute join,但是从根本来说不是真正的redistribute join,存在查询放大问题,也是性能较差的一种查询方式。
1.2 Broadcast Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
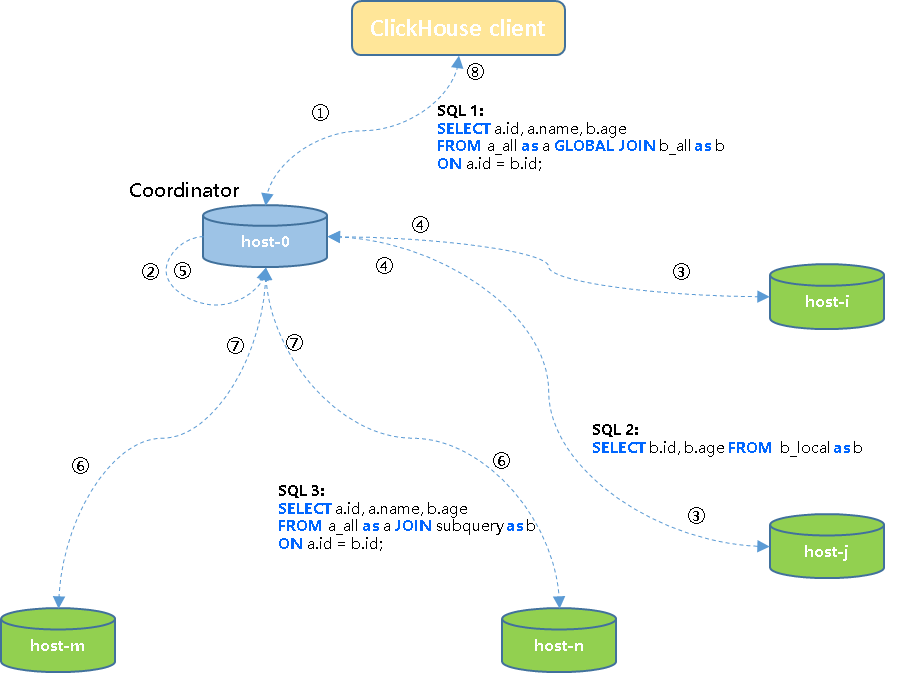
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2子查询任务;
③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
④ 各子节点任务执行完成之后将结果发回到协调节点;
⑤ 协调节点将上一步接收到的结果汇总为结果集;
⑥ 协调节点将结果集发送到集群各个节点,同时将SQL3任务下发到各个节点;
⑦ 各节点在本地将左表的分片和右表子查询结果集进行join计算,然后将结果及发回到协调节点;
⑧ 协调节点将最终结果返回给客户端。
3)总结:
- 右表的查询在initiator节点完成后,通过网络发送到其他节点,避免其他节点重复计算,从而避免查询放大问题;
- GLOBAL JOIN 可以看做一个不完整的Broadcast JOIN实现。如果JOIN的右表数据量较大,就会占用大量网络带宽,导致查询性能降低;
- ClickHouse的global join方式和业界MPP的区别:
- ClickHouse会将右表过滤结果汇总到一个节点,然后又发送到所有节点,对单节点内存/磁盘空间占用较大,全量数据发送到所有节点,对网络带宽消耗也较大;
- 而业界MPP数据库每个节点并行的将自己一部分数据广播发到所有节点,之后就可以直接进行下一阶段的本地join动作,多个节点都能并行执行,同时数据也不需要从一个节点发送到所有节点,对网络和单节点磁盘及内存消耗较少。
1.3 Colocate Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
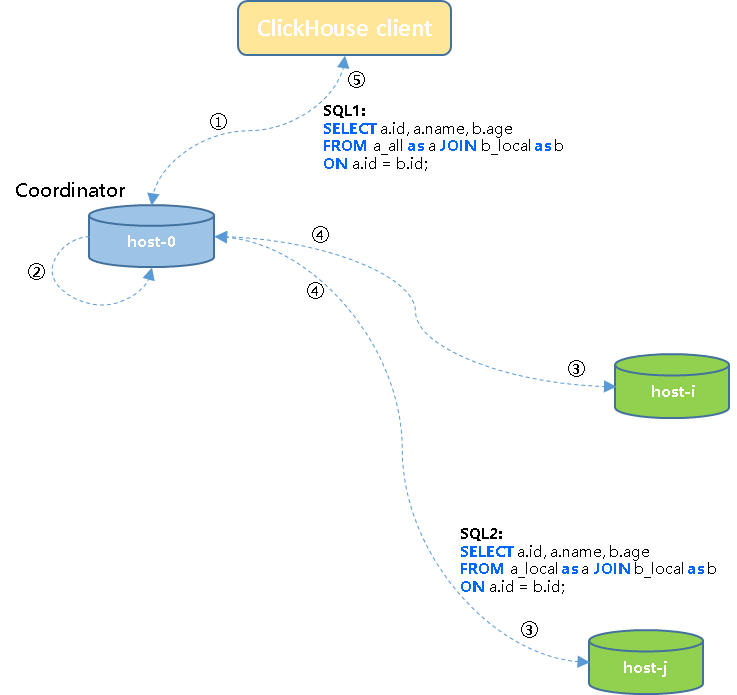
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2子查询任务;
③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
④ 各子节点任务执行完成之后将结果发回到协调节点;
⑤ 协调节点将上一步接收到的结果汇总为结果集返回给客户端。
3)总结:
- 由于数据已经进行了预分区/分布,相同的JOIN KEY对应的数据一定存储在同一个计算节点,join计算过程中不会进行跨节点的数据交换工作,所以无需对右表做分布式查询,也能获得正确结果,并且性能较优。
2. ClickHouse Colocate join
2.1 Colocate JOIN原理:
- 根据“相同JOIN KEY必定相同分片”原理,我们将涉及JOIN计算的表,按JOIN KEY在集群维度作分片。将分布式JOIN转为节点的本地JOIN,极大减少了查询放大问题。按如下操作:
1)将涉及JOIN的表字段按JOIN KEY用同样分片算法进行分片;
2)将JOIN SQL中右表换成相应的本地表名称进行join。
2.2 Colocate JOIN性能:
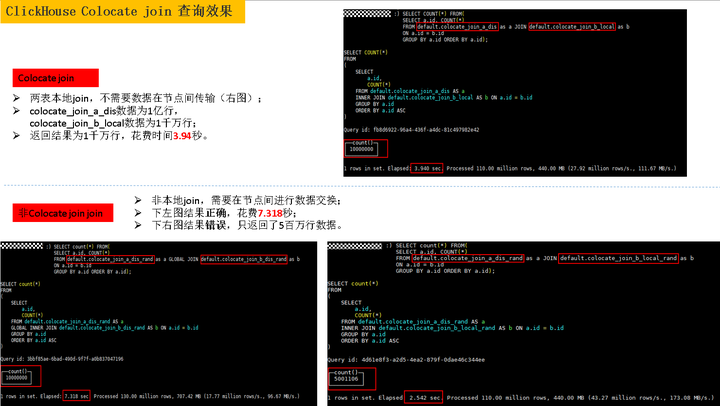
- 数据和用例准备
1)环境:准备2 shard,2副本共4个节点的ClickHouse计算节点集群;
2)用例:分别创建join字段按id % 2(2为shard个数,可根据实际集群环境进行调整)取余数据分布方式(相同id数据分布到同一个节点),以及RandRowbin (数据随机rand分布)数据分布方式分布式表和本地表,分布式表指定分布方式,本地表为Replicated表,具体用例如下:
- colocate_join_a_local数据按照2分片(id % 2或哈希取模)进行数据分布;
- 相同分布列的字段key的数据会分布到同一个节点;
- 数据通过分布式表colocate_join_a_dis把数据写入分布到各数据节点。

- colocate_join_a_local_rand数据(rand())随机分布;
- 相同分布列的字段key数据会随机分布到各节点;
- 数据通过分布式表colocate_join_a_dis_rand写入进行分布。

- 结果对比
2.3 Colocate Join场景约束
1)数据写入
Colocate join场景需要用户在系统建设前提前进行数据规划,数据写入时join的左右表join条件字段需要使用相同哈希算法入库分布,保证join key相同数据写入到同一个计算节点上。
- 如果对数据写入时效性要求不太高的场景,可通过分布式表进行生成数据,生成数据简单快捷,性能较慢;
- 如果对数据写入时效性要求较高的场景,可通过应用/中间件写入数据到local表,中间件需要实现入库数据分布算法,入库性能较好。
2)扩缩容
- 扩缩容完成后,需要将全部数据重写/重分布一遍,缺点:耗时长,占用存储可能暂时会翻倍,一种节省空间的方式是:逐个表进行重分布,每个表数据重分布完成后可删除重分布前的数据,避免占用过多存储。将来的改进/增强:重分布过程中支持可写在线,重分布尽量少或不影响写入查询的在线操作,减少重分布过程中对客户业务的影响。
3. 总结
业界所宣称的ClickHouse只能做大宽表查询,而通过以上分析,事实上在特定场景下ClickHouse也可以进行高效的join(Broadcast join和Colocate join)查询,如果将表结构设计及数据分布的足够好,查询性能也并不会太差:Broadcast join对于大小表关联,需要将小表数据放在右边;Colocate join需要将join key字段使用相同的分布算法,将分布键相同数据分布在同一个计算节点。对于ClickHouse而言,当前优化器能力较弱,如join场景reorder以及统计信息缺失,基于成本代价估算CBO的优化能力较弱,用户SQL所写即所得,可能会要求人人都是DBA,人人都要对ClickHouse或数据库有深入的理解及经验才能设计出较优的数据库结构以及写出较高性能的SQL语句。对于ClickHouse手动挡数据库,将来我们也会在统计信息、CBO优化器、分布式join模型框架、大大表等多表关联查询以及复杂查询上进行优化增强,以降低用户使用门槛,提升用户使用体验。
Colocate Join :ClickHouse的一种高性能分布式join查询模型的更多相关文章
- 基于netty轻量的高性能分布式RPC服务框架forest<上篇>
工作几年,用过不不少RPC框架,也算是读过一些RPC源码.之前也撸过几次RPC框架,但是不断的被自己否定,最近终于又撸了一个,希望能够不断迭代出自己喜欢的样子. 顺便也记录一下撸RPC的过程,一来作为 ...
- 高性能分布式锁-redisson
RedLock算法-使用redis实现分布式锁服务 译自Redis官方文档 在多线程共享临界资源的场景下,分布式锁是一种非常重要的组件. 许多库使用不同的方式使用redis实现一个分布式锁管理. 其中 ...
- 基于netty轻量的高性能分布式RPC服务框架forest<下篇>
基于netty轻量的高性能分布式RPC服务框架forest<上篇> 文章已经简单介绍了forest的快速入门,本文旨在介绍forest用户指南. 基本介绍 Forest是一套基于java开 ...
- 两种高性能 I/O 设计模式 Reactor 和 Proactor
两种高性能 I/O 设计模式 Reactor 和 Proactor Reactor 和 Proactor 是基于事件驱动,在网络编程中经常用到两种设计模式. 曾经在一个项目中用到了网络库 libeve ...
- 高性能分布式执行框架——Ray
Ray是UC Berkeley AMP实验室新推出的高性能分布式执行框架,它使用了和传统分布式计算系统不一样的架构和对分布式计算的抽象方式,具有比Spark更优异的计算性能. Ray目前还处于实验室阶 ...
- 高可用高性能分布式文件系统FastDFS实践Java程序
在前篇 高可用高性能分布式文件系统FastDFS进阶keepalived+nginx对多tracker进行高可用热备 中已介绍搭建高可用的分布式文件系统架构. 那怎么在程序中调用,其实网上有很多栗子, ...
- I/O模型系列之四:两种高性能IO设计模式 Reactor 和 Proactor
不同的操作系统实现的io策略可能不一样,即使是同一个操作系统也可能存在多重io策略,常见如linux上的select,poll,epoll,面对这么多不同类型的io接口,这里需要一层抽象api来完成, ...
- I/O模型之三:两种高性能 I/O 设计模式 Reactor 和 Proactor
目录: <I/O模型之一:Unix的五种I/O模型> <I/O模型之二:Linux IO模式及 select.poll.epoll详解> <I/O模型之三:两种高性能 I ...
- 高性能分布式哈希表FastDHT
高性能分布式哈希表FastDHT介绍及安装配置 FastDHT-高效分布式Hash系统 FastDHT(分布式hash系统)安装和与FastDFS整合实现自定义文件ID Centos6.3 停安装 F ...
- 6种.net分布式缓存解决方式
6种.net分布式缓存解决方式 1. 使用内置ASP.NET Cache (System.Web.Caching) : https://msdn.microsoft.com/en-us/lib ...
随机推荐
- kubernetes 概述
云原生的发展 云原生是一条最佳路径或者最佳实践.更详细的说,云原生为用户指定了一条低心智负担的.敏捷的.能够以可扩展.可复制的方式最大化地利用云的能力.发挥云的价值的最佳路径.因此,云原生其实是一套指 ...
- js数据结构--队列
<!DOCTYPE html> <html> <head> <title></title> </head> <body&g ...
- 安装 Android x86 并开启 arm 兼容
安装 Android x86 并开启 arm 兼容 Win 11 下开启了 Hyper-v,尝试了各种安卓模拟器,要么不能设置代理(BlueStacks),要么/system目录没办法设置. 获取 A ...
- PKUSC & GDCPC 2023 游记
离得太近,游记打算扔一起. 有没有神仙面基啊 /kel. PKUSC 2023 Day -? 突然听说不给 NOI Linux,震惊. 前情提要:在从 CSP 开始就全员强制 linux 的 LN 为 ...
- 2022/7/26 暑期集训 pj组第6次%你赛
个人第3次 又是下午打,旁边那帮 不知好歹的 入门组小孩们又在吵吵... T1 老师是不是放反了? T1 是蓝题诶 理所应当地 跳过 然后就忘了写了,连样例也没打...样例可是有7分诶! 到现在也没写 ...
- 【VMware NSX-T】在vCenter内直接将Manager设备删除后,ESXi上还遗留N-VDS交换机及网卡被占用等问题的解决方法。
由于之前在实验平台安装了NSX-T的测试环境,但是由于太忙了没怎么测试,后来实验环境出了点小问题,索性就将上面所有虚拟机给清空了.但是没想到上面遗留了NSX-T上创建的N-VDS交换机,还占用了服务器 ...
- Vue打包发布
打包发布 目标:明确打包的作用 说明:vue脚手架只是开发过程中,协助开发的工具,当真正开发完了,脚手架不参与上线 打包的作用: 将多个文件压缩合并成一个文件 语法降级 less sass ts 语法 ...
- 基于WPSOffice+Pywpsrpc构建Docker镜像,实现文档转换和在线预览服务
背景 产品功能需要实现标准文档的在线预览功能,由于DOC文档没办法直接通过浏览器打开预览,需要提前转换为PDF文档或者HTML页面. 经过测试发现DOC转为HTML页面后文件提交较大,而且生成的静态资 ...
- STA分析-复制
1 静态时序分析(Static Timing Analysis)静态时序分析(Static Timing Analysis):静态执行对于数字设计时序的分析,不依赖于施加在输入端口上的激励,验证设计是 ...
- 生成模型的两大代表:VAE和GAN
生成模型 给定数据集,希望生成模型产生与训练集同分布的新样本.对于训练数据服从\(p_{data}(x)\):对于产生样本服从\(p_{model}(x)\).希望学到一个模型\(p_{model}( ...