2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k。 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符; 删除该前缀,递增分割计数。如果有剩余
2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k。
要进行分割操作,直到字符串s为空:
选择s的最长前缀,该前缀最多包含k个不同字符;
删除该前缀,递增分割计数。如果有剩余字符,它们保持原来的顺序。
在操作之前,可以修改字符串s中的一个字符为另一个小写英文字母。
在最佳情况下修改至多一次字符后,返回操作结束时得到的最大分割数量。
输入:s = "accca", k = 2。
输出:3。
答案2024-05-04:
题目来自leetcode3003。
大体步骤如下:
1.创建一个递归函数dfs,用于计算分割得到的最大数量。
2.函数中,首先检查是否到达字符串末尾,若是则返回 1(表示完成一个分割)。
3.使用memo记录中间结果,加快计算速度。
4.对于当前处理的字符s[i],如果不将其作为新的分割点,继续处理下一个字符。
5.如果将s[i]作为新的分割点,并且新的字符数量不超过k,则继续向后处理。
6.如果未修改过字符,则尝试修改s[i]为其他26个小写字母,然后继续考虑分割带来的最大数量。
7.在每一步中,根据是否修改过字符,记录当前的最大分割数量。
8.最终返回得到的最大分割数量。
总的时间复杂度为 $O(n \cdot 2{26})$,其中$n$为字符串长度,$2$表示尝试修改字符的可能性数目。
总的额外空间复杂度为$O(n \cdot 2^{26})$,主要由memo中间结果记录所占用的空间引起。
Go完整代码如下:
package main
import (
"fmt"
"math/bits"
)
func max(x, y int) int {
if x > y {
return x
}
return y
}
func maxPartitionsAfterOperations(s string, k int) int {
n := len(s)
type args struct {
i, mask int
changed bool
}
memo := map[args]int{}
var dfs func(int, int, bool) int
dfs = func(i, mask int, changed bool) (res int) {
if i == n {
return 1
}
a := args{i, mask, changed}
if v, ok := memo[a]; ok { // 之前计算过
return v
}
// 不改 s[i]
bit := 1 << (s[i] - 'a')
newMask := mask | bit
if bits.OnesCount(uint(newMask)) > k {
// 分割出一个子串,这个子串的最后一个字母在 i-1
// s[i] 作为下一段的第一个字母,也就是 bit 作为下一段的 mask 的初始值
res = dfs(i+1, bit, changed) + 1
} else { // 不分割
res = dfs(i+1, newMask, changed)
}
if !changed {
// 枚举把 s[i] 改成 a,b,c,...,z
for j := 0; j < 26; j++ {
newMask := mask | 1<<j
if bits.OnesCount(uint(newMask)) > k {
// 分割出一个子串,这个子串的最后一个字母在 i-1
// j 作为下一段的第一个字母,也就是 1<<j 作为下一段的 mask 的初始值
res = max(res, dfs(i+1, 1<<j, true)+1)
} else { // 不分割
res = max(res, dfs(i+1, newMask, true))
}
}
}
memo[a] = res // 记忆化
return res
}
return dfs(0, 0, false)
}
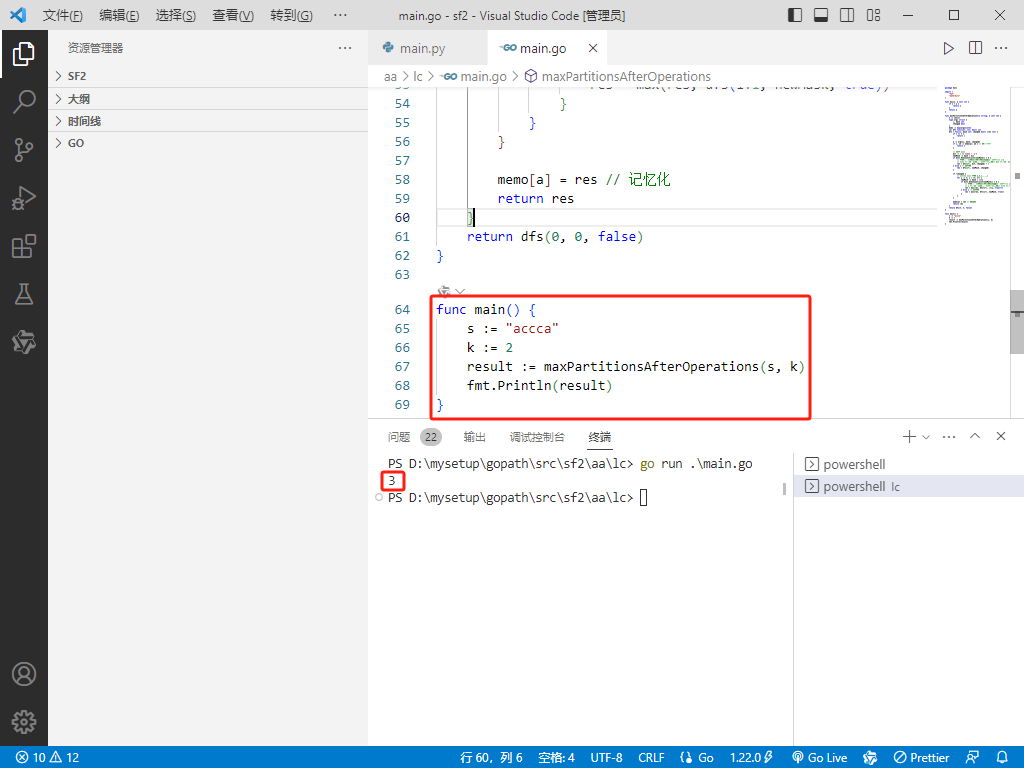
func main() {
s := "accca"
k := 2
result := maxPartitionsAfterOperations(s, k)
fmt.Println(result)
}
Python完整代码如下:
# -*-coding:utf-8-*-
def max_partitions_after_operations(s, k):
n = len(s)
memo = {}
def dfs(i, mask, changed):
if i == n:
return 1
a = (i, mask, changed)
if a in memo:
return memo[a]
res = 0
bit = 1 << (ord(s[i]) - ord('a'))
new_mask = mask | bit
if bin(new_mask).count('1') > k:
res = dfs(i + 1, bit, changed) + 1
else:
res = dfs(i + 1, new_mask, changed)
if not changed:
for j in range(26):
new_mask = mask | 1 << j
if bin(new_mask).count('1') > k:
res = max(res, dfs(i + 1, 1 << j, True) + 1)
else:
res = max(res, dfs(i + 1, new_mask, True))
memo[a] = res
return res
return dfs(0, 0, False)
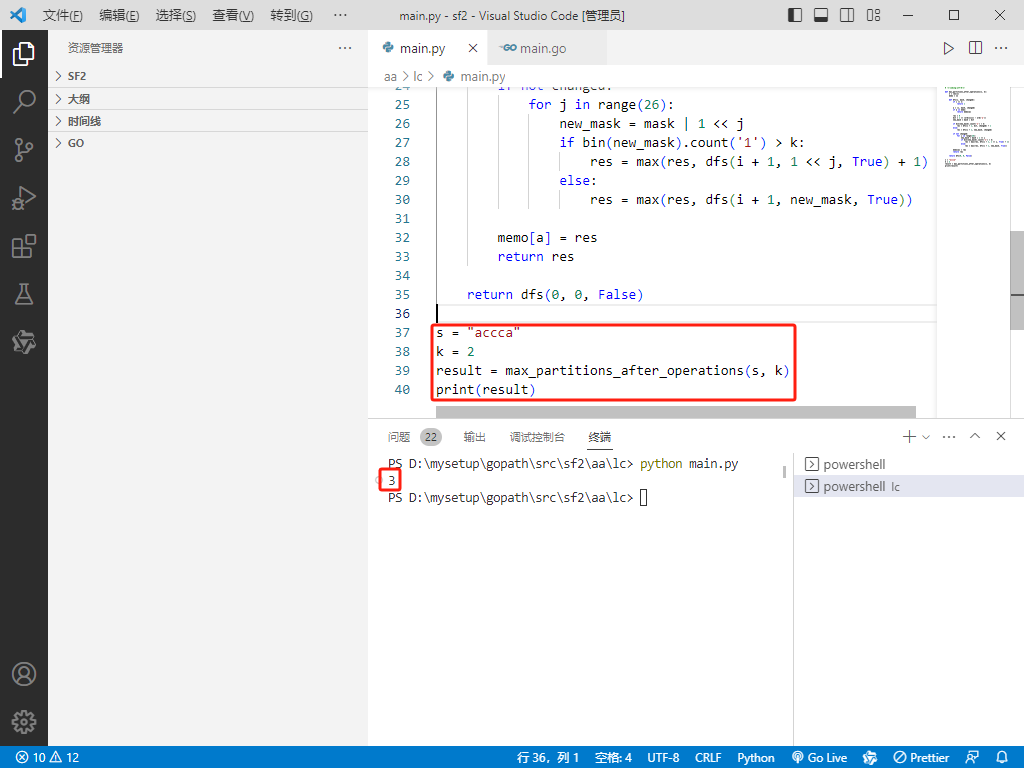
s = "accca"
k = 2
result = max_partitions_after_operations(s, k)
print(result)
2024-05-04:用go语言,给定一个起始索引为0的字符串s和一个整数k。 要进行分割操作,直到字符串s为空: 选择s的最长前缀,该前缀最多包含k个不同字符; 删除该前缀,递增分割计数。如果有剩余的更多相关文章
- poj1056(字符串判断是否存在一个字符串是另一个字符串的前缀)
题目链接:https://vjudge.net/problem/POJ-1056 题意:给定一个字符串集,判断是否存在一个字符串是另一个字符串的前缀. 思路:和hdoj1671一样,有两种情况: 当前 ...
- [leetcode]340. Longest Substring with At Most K Distinct Characters至多包含K种字符的最长子串
Given a string, find the length of the longest substring T that contains at most k distinct characte ...
- [LeetCode] 340. Longest Substring with At Most K Distinct Characters 最多有K个不同字符的最长子串
Given a string, find the length of the longest substring T that contains at most k distinct characte ...
- [LeetCode] Longest Substring with At Most Two Distinct Characters 最多有两个不同字符的最长子串
Given a string S, find the length of the longest substring T that contains at most two distinct char ...
- python Trie树和双数组TRIE树的实现. 拥有3个功能:插入,删除,给前缀智能找到所有能匹配的单词
#coding=utf- #字典嵌套牛逼,别人写的,这样每一层非常多的东西,搜索就快了,树高26.所以整体搜索一个不关多大的单词表 #还是O(). ''' Python 字典 setdefault() ...
- Redis删除特定前缀key的优雅实现
还在用keys命令模糊匹配删除数据吗?这就是一颗随时爆炸的炸弹! Redis中没有批量删除特定前缀key的指令,但我们往往需要根据前缀来删除,那么究竟该怎么做呢?可能你一通搜索后会得到下边的答案 re ...
- [LeetCode] 159. Longest Substring with At Most Two Distinct Characters 最多有两个不同字符的最长子串
Given a string s , find the length of the longest substring t that contains at most 2 distinct char ...
- Redis删除相同前缀的key
如何优雅地删除Redis set集合中前缀相同的key? Redis中有删除单条数据的命令DEL,却没有批量删除特定前缀key的指令,但我们经常遇到需要根据前缀来删除的业务场景 ...
- 算法战斗:给定一个号码与通配符问号W,问号代表一个随机数字。 给定的整数,得到X,和W它具有相同的长度。 问:多少整数协议W的形式和的比率X大?
如果说: 给定一个号码与通配符问号W,问号代表一个随机数字. 给定的整数,得到X,和W它具有相同的长度. 问:多少整数协议W的形式和的比率X大? 进格公式 数据的多组,两排各数据的,W,第二行是X.它 ...
- 最多有k个不同字符的最长子字符串 · Longest Substring with at Most k Distinct Characters(没提交)
[抄题]: 给定一个字符串,找到最多有k个不同字符的最长子字符串.eg:eceba, k = 3, return eceb [暴力解法]: 时间分析: 空间分析: [思维问题]: 怎么想到两根指针的: ...
随机推荐
- C# 日志监控软件 基于 FileSystemWatcher 02
基于上一篇<C# 日志监控软件 基于 FileSystemWatcher>改进 using System; using System.Collections.Generic; using ...
- ZYNQ7000系列学习之TF卡读写(2)
ZYNQ读写实验(2) 1.实验原理 在TF卡读写实验1中,已经将每一个步骤都做完了,但是最后得到的结果是错误的.那个时候由于TF没有格式化,显示的是错误信息.在格式化后,再次实验,得到了预期的结果. ...
- GFLV2:边界框不确定性的进一步融合,提点神器 | CVPR 2021
GFLV2基于GFLV1的bbox分布进行改进,将分布的统计信息融入到定位质量估计中,整体思想十分创新和完备,从实验结果来看,效果还是挺不错的 来源:晓飞的算法工程笔记 公众号 论文: Gener ...
- KingbaseES 名词解释之timeline
timeline定义 每当归档文件恢复完成后,创建一个新的时间线用来区别新生成的WAL记录.WAL文件名由时间线和日志序号组成 引入timeline的意义 为了理解引入时间线的背景,我们来分析一下,如 ...
- KingbaseES file_dw 介绍
file_dw简介 file_fdw模块提供外部数据包装器file_fdw, 它能被用来访问服务器的文件系统中的数据文件,或者在服务器上执行程序并读取它们的输出. 数据文件或程序输出必须是能够被C ...
- 探索Django REST框架构建强大的API
本文分享自华为云社区<探索Django REST框架构建强大的API>,作者:柠檬味拥抱. 在当今的Web开发中,构建强大的API已经成为了不可或缺的一部分.而在Python领域,Djan ...
- Java实现软件设计模式---抽象工厂模式(性别产品等级结构肤色产品族)
一.题目要求 二.画出对应的类图 三.文件目录结构 四.具体实现代码 Black.java 1 package com.a004; 2 3 public class Black implements ...
- AJAX 前端开发利器:实现网页动态更新的核心技术
AJAX AJAX是开发者的梦想,因为你可以: 在不重新加载页面的情况下更新网页 在页面加载后请求来自服务器的数据 在页面加载后接收来自服务器的数据 在后台向服务器发送数据 HTML页面 <!D ...
- Seaborn调色盘设置
调色盘设置 设置调色 color_palette()设置调色盘,返回一个调色盘的颜色列表,默认6种颜色:deep, muted, bright, pastel, dark, colorblind. s ...
- np.squeeze()
np.squeeze() 是 NumPy 库中的一个函数,用于从数组中删除单维度的条目.它返回一个在输入数组中删除了尺寸为 1 的维度的新数组. 下面是使用 np.squeeze() 的示例代码: 点 ...