关于为什么使用 ASCII GBK Unicode编码
关于为什么使用 ASCII GBK Unicode编码
由来:大家都知道计算机最早是美国人为了更加便捷的存储和计算数据发明的,但是呢计算机底层都是硬件,只能存储像0101这样的二进制数据,那美国人为了让计算机能够存储他们所使用的字符(字母,数字,标点符号,特殊字符等),他们就对这些字符进行了编号,从0 开始一直到127,一共128个字符。 比如字符0的十进制编码就是48,字符a的十进制编码是97,字符A十进制编码为65。我们把这些字符称之为码点,可以理解为是字符的唯一标识,那么这一套码点下来,也就组成了一个字符集,就是我们使用ascii字符集。
ASCII(美国信息交换标准代码)
接着上面说,但是上面的十进制字符集还是不能在计算机中进行存储,所以美国人对这些码点进行了编码,直接把这些码点转成了他们对应的二进制形式,也就是7 位01组合 'xxxxxxx' ,但是这样就不能满足计算机的最小01组合(计算机的最小存储单元就是1byte 8位01组合 ),所以在这些码点的二进制前面补了一位0,正好变成了1字节用来表述字符。
标准的ASCII使用一个字节存储一个字符,首位是 0 (0 被当作标识符),总共可以表示128个字符,这些对美国人来说完全是够用了
ascii编码形式:0xxxxxxx
GBK(汉字内码扩展规范)
接着上面说,随着计算机普及和发展,我们中国人也开始使用计算机。那么当我们中国人看到这个ASCII字符表的时候,只说了一句话,emmm,"还不够我塞牙缝的!" ,这是由于我们的字符实在是太多了,ASCII没有办法再包含我们的字符,所以我们中国人就自己研发了一种新的GBK编码,叫做 汉字编码字符集。
GBK字符集包含二万多个汉字等字符,GBK一个中文字符编码是以两个字节的形式存储。
注意:这里需要注意GBK字符集是需要去兼容ascii的。
GBK编码后的形式:1xxxxxxx xxxxxxxx 十五位 32768个字符,其中有二万多个汉字字符
那么在GBK中,英文字符和汉字在计算机中如何进行解码。比如:你h啊
编码之后:xxxxxxxx xxxxxxxx|0xxxxxxx|xxxxxxxx xxxxxxxx
那么计算机在对底层的01比特解码的时候如何去识别汉字和字母的编码呢??
这里规定汉字的第一个字节的第一位必须是 1 ,ascii字节是第一位是0 ,那么计算机在解码时就会根据字节的首位去判断,当字节的第一位是1之后,就知道接下来的15位01比特表示了一个汉字,当字节的第一位是0时,就知道接下来的7位01比特表示一个ascii中的一个字符。
Unicode字符集(统一码,也叫万国码)
接着上面说,当我们中国人看到ascii字符集无法表示中国汉字,就研发了GBK,那么当世界上其他国家也为他们的语言进行编码之后,就会出现各种各样的字符集编码。 这样的话,当计算机在世界流通,信息交换的时候,就会很麻烦。比如:当我们把用GBK编码的字符发给美国,美国人用ascii编码打开的时候,就会产生乱码,无法解析我们的内容。
此时国际组织就站出来了,并且搞了一套全世界通用的字符集编码unicode,也就是最早的是UTF-32 ,并且国际组织,呼吁各个国家使用unicode编码,这样就可以解决交流不通的问题了。
//utf-32
Unicode是国际组织制定的编码,可以容纳世界上所有的文字,符号的字符集
最早的 UTF-32
用4个字节表示32位表示一个字符,当初这样设计的思想就是有容乃大(2^32足矣表示世界上的所以文字,想法很狂野,但不现实)
但是这样以32位编码的字符集并不被其他国家所认可,大家都认为这种编码方案过太于"奢侈!" ,因为四个字节表示一个字符的编码方式,占用存储空间,并且使通信效率变低。比如:我们要表示一个字母就是 xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx,那么这样的编码方案,最终没有被各个国家采用。
紧接着就诞生了 一个非常重要的 字符集编码 UTF-8 (目前我们在使用的编码一般都是这个编码,比我我们在使用编译器的时候默认就是使用utf-8)
UTF-8
utf-8 是Unicode字符集的一种编码方案,采取可变长编码方案,一共分为四个长度区 :1个字节,2个字节,3个字节,4个字节(按照需要去相应的使用)
那么英文字符、数字、汉字字符,在unicode中如何编码呢?
在unicode中英文字符、数字 只占用一个字节(兼容ascii),汉字占用三个字节。
比如:n好a 0xxxxxxx|1110xxxxx 10xxxxxx 10xxxxxx|0xxxxxxx
那么解码的时候如何区分呢?
这里规定的是,英文字符在进行存储的时候就是一个以 0 开头的字节,如果是两个字节存储时候,要求第一个字节是以110 第二个字节需要以10开头,以此类推,至此我要讲的编码原理就结束了。

注意1:我们程序员一般使用 utf-8编码
注意2:字符的编码解码需要使用同一种字符集,否则解码的时候会出现乱码的请
注意3: 英文和数字,一般不会乱码,因为很多字符都兼容了ascii编码
比如在pycharm编码的时候使用的就是 utf-8
测试:使用不兼容编码解析文本
在pycharm中对 你h啊 进行解码(编码使用的是unicode--utf-8)
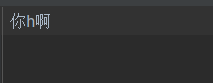
我们用ascii进行解码
出现提示,我们是否要用ascii解析Unicode编码
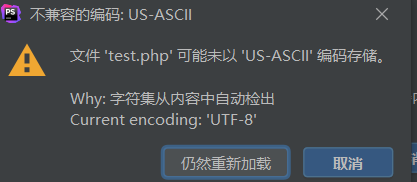
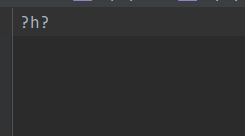
解析结果就出现了 ?h?,由于ascii不兼容Unicode编码,所以在解码的时候出现了乱码。在ctf比赛中因解析问题出现的 ?就是这个原因
关于为什么使用 ASCII GBK Unicode编码的更多相关文章
- BIG5, GB(GB2312, GBK, ...), Unicode编码, UTF8, WideChar, MultiByte, Char说明与区别
汉语unicode编译方式,BIG5是繁体规范,GB是简体规范 GB是大陆使用的国标码,BIG5码,又叫大五码,是台湾使用的繁体码. BIG5编码, GB编码(GB2312, GBK, ...), U ...
- ASCII与Unicode编码消息写文件浅析
[文章摘要] ASCII与Unicode是两种常见的字符编码. 它们的表示方法不一样,因而在程序中就要差别处理. 本文基于作者的实际开发经验,对ASCII与Unicode两种字符编码消息的写文件过程进 ...
- 编码 ASCII, GBK, Unicode+utf-8
0. 1.参考 网页编码就是那点事 阮一峰 字符编码笔记:ASCII,Unicode 和 UTF-8 2.总结 美国 ASCII 码 发音: /ˈæski/ :128个字符,只占用了一个字节的后面7位 ...
- 字符编解码的故事(ASCII,GBK,Unicode,Utf-8区别)
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们认为8个开关状态作为原子单位很好,于是他们把这称为"字节". 再后来,他们又做了一 ...
- ASCII和Unicode编码的区别
归纳: 编码 大小 支持语言 ASCII 1个字节 英文 Unicode 2个字节(生僻字4个) 所有语言 UTF-8 1-6个字节,英文字母1个字节,汉字3个字节,生僻字4-6个字节 所有语言 具体 ...
- 码表的理解(ASCII,GBK,Unicode,UTF-8等)。
以下任何言论都完全是个人的理解,如有雷同纯属巧合,如有错误,希望大家多多指出,共同学习!谢谢! 笔者是一个理解能力偏慢.稍钻牛角尖的程序员,什么东西都要从最基础理解起,一步一步向上理解,因此讲述时也是 ...
- ASCII 和 Unicode 编码的由来
大话数据结构上的说明: 网络博文的说明:
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍,并使LCD显示汉字字符(2)
在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Unicode编码 2)写应用程序,使LCD显示汉字和字符 大家都知道,数据传输的是二进制,而字符和汉字 ...
- 2.数码相框-编码(ASCII/GB2312/Unicode)介绍
转载:https://www.cnblogs.com/lifexy/p/8485634.html 在上章-学习了数码相框的框架分析(1)了 本章主要内容如下: 1)熟悉ASCII/GB2312/Uni ...
- javascript正则中ASCII与unicode
正则表达式中允许直接利用ASCII和Unicode编码来查找我们相应的字符串. ASCII: 下面是检索ASCII编码在x41-x7a范围内的所有匹配的字符串.(x41,x7a为十六进制) var s ...
随机推荐
- 多Github账号指定ssh-key提交代码
问题 目前github中代码提交只能通过ssh方式. 每个github账号只能添加一个专用的ssh-key. 如果同时有多个Github账号在用的话就必须给每个账号绑定不同的ssh-key. 方法一: ...
- 如何从零开始集成DTM Android SDK
什么是动态标签管理? 动态标签管理(Dynamic Tag Manager,简称"DTM"),可让开发者快速配置更新测量代码及相关代码片段,可以基于Web界面轻松地进行分析.测量代 ...
- 在 AWS 平台搭建 DolphinScheduler
AWS平台搭建 DolphinScheduler DolphinScheduler 是当前热门的调度器,提供了完善的可视化.拖拉拽式的调度.在 AWS 平台上提供了 airflow 与 step fu ...
- Vs生成后 自动压缩 删除多余xml
setlocal enabledelayedexpansionset ProjectName=$(ProjectName)del /s /q /f "$(ProjectDir)bin\Deb ...
- python基础-列表list [ ]
列表的定义和操作 列表的特性: 元素数量 支持多个 元素类型 任意 下标索引 支持 重复元素 支持 可修改性 支持 数据有序 是 使用场景 可修改.可重复的 一批数据记录场景 # 定义一个列表list ...
- Redis查询大key
原文 安装 wget "https://pypi.python.org/packages/68/44/5efe9e98ad83ef5b742ce62a15bea609ed5a0d1caf35 ...
- 梁培利DeFi去中心化金融课程笔记2024版
课程链接:https://space.bilibili.com/220951871/channel/collectiondetail?sid=2824381&ctype=0 讲义仓库:http ...
- 汇编语言--cpu的工作原理(寄存器)--手稿
03
- yb课堂 谷歌开源缓存框架Guava cache,封装API 《二十》
Guava cache github地址:点我直达 全内存的本地缓存实现 高性能且功能丰富 线程安全,操作简单 添加依赖 <dependency> <groupId>com.g ...
- 洛谷P1057
#include<iostream> #include<utility> using namespace std; typedef long long ll; #define ...