【pytorch】目标检测:YOLO的基本原理与YOLO系列的网络结构
利用深度学习进行目标检测的算法可分为两类:two-stage和one-stage。two-stage类的算法,是基于Region Proposal的,它包括R-CNN,Fast R-CNN, Faster R-CNN;one-stage类的算法仅仅使用一个CNN网络直接预测不同目标的类别与位置,它包括YOLO系列算法、SSD算法。two-stage类算法精度高,但速度慢,one-stage类算法速度快,但精度不如two-stage。当然了,在它们也在吸取彼此之间的精华,进而提升改进自我。
YOLO(You Only Look Once)凭借其实时性、不错的精度,在工业应用中发挥着巨大的作用,如无人驾驶、农作物病虫害预防、医学检查等。而且YOLO系列从提出至今已经迭代研发出了15个版本,不断地借鉴新的算法提高己身性能。下面让我们一起来了解YOLO算法吧。
1. YOLO概述
实时物体检测已经成为众多应用中的一个重要组成部分,如自主车辆、机器人、视频监控和增强现实等各个领域。在各种物体检测算法中,YOLO(You Only Look Once)因其在速度和准确性方面的显著平衡而脱颖而出,能够快速、可靠地识别图像中的物体。自成立以来,YOLO系列已经经历了多次迭代,每次都是在以前的版本基础上解决局限性并提高性能(见下图)。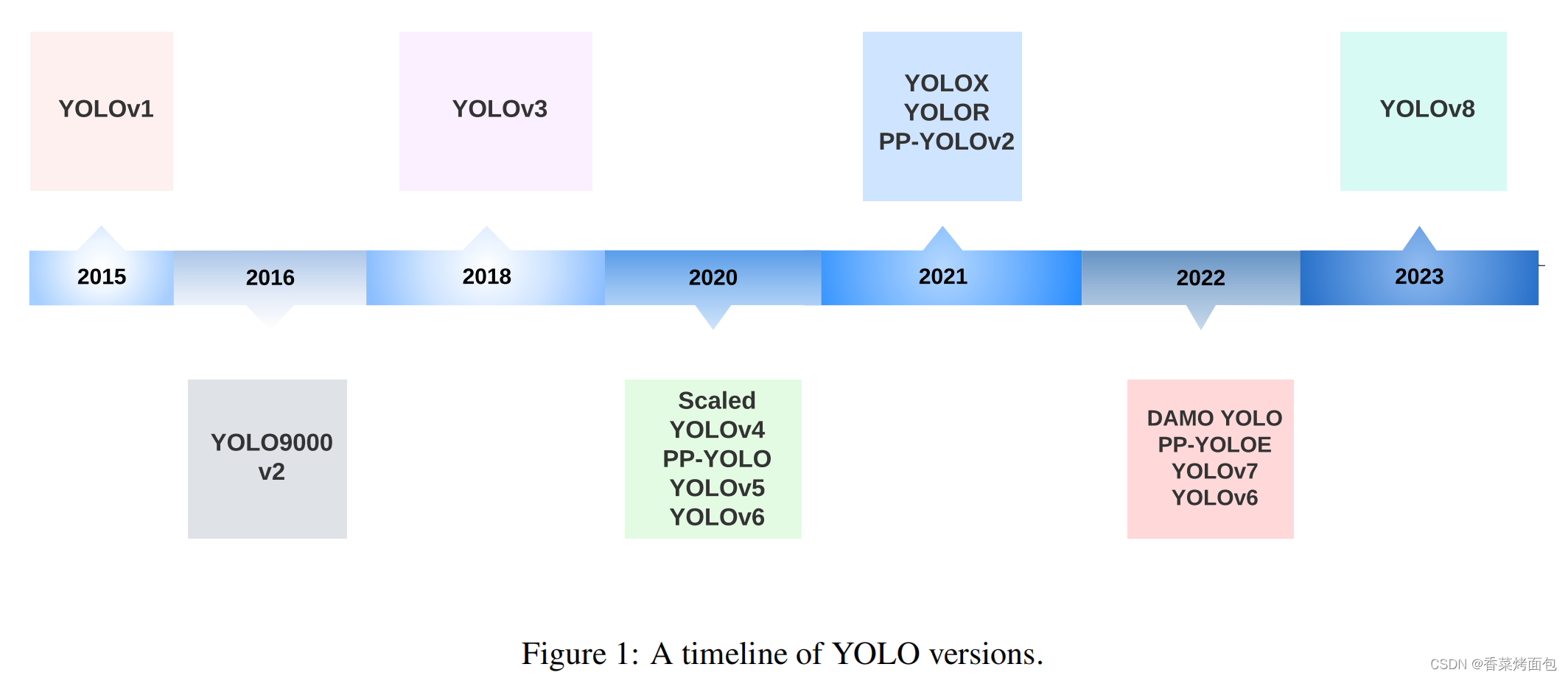
图1 YOLO发展年表
2. YOLOv1的基本原理
在介绍YOLO之前先来介绍一下滑动窗口技术。滑动窗口技术就是采用不同大小和比例(宽高比)的窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了。但是这有个致命的缺点,由于检测目标的大小未知,需要设置很多不同尺寸的窗口去滑动,这样会导致产生极多的无效区域,而且这些区域都需要经过分类器判断,计算量巨大。
YOLO摒弃了滑动窗口技术,直接将原始图片分割成SS个互不重合的小方块,然后通过卷积最后产生SS的特征图,可以认为特征图的每个元素对应原始图片的一个小方块(和视野域挺像的),然后用每个元素来预测那些中心点在该小方格内的目标,这就是YOlO系列算法的朴素思想。
2.1. 设计理念
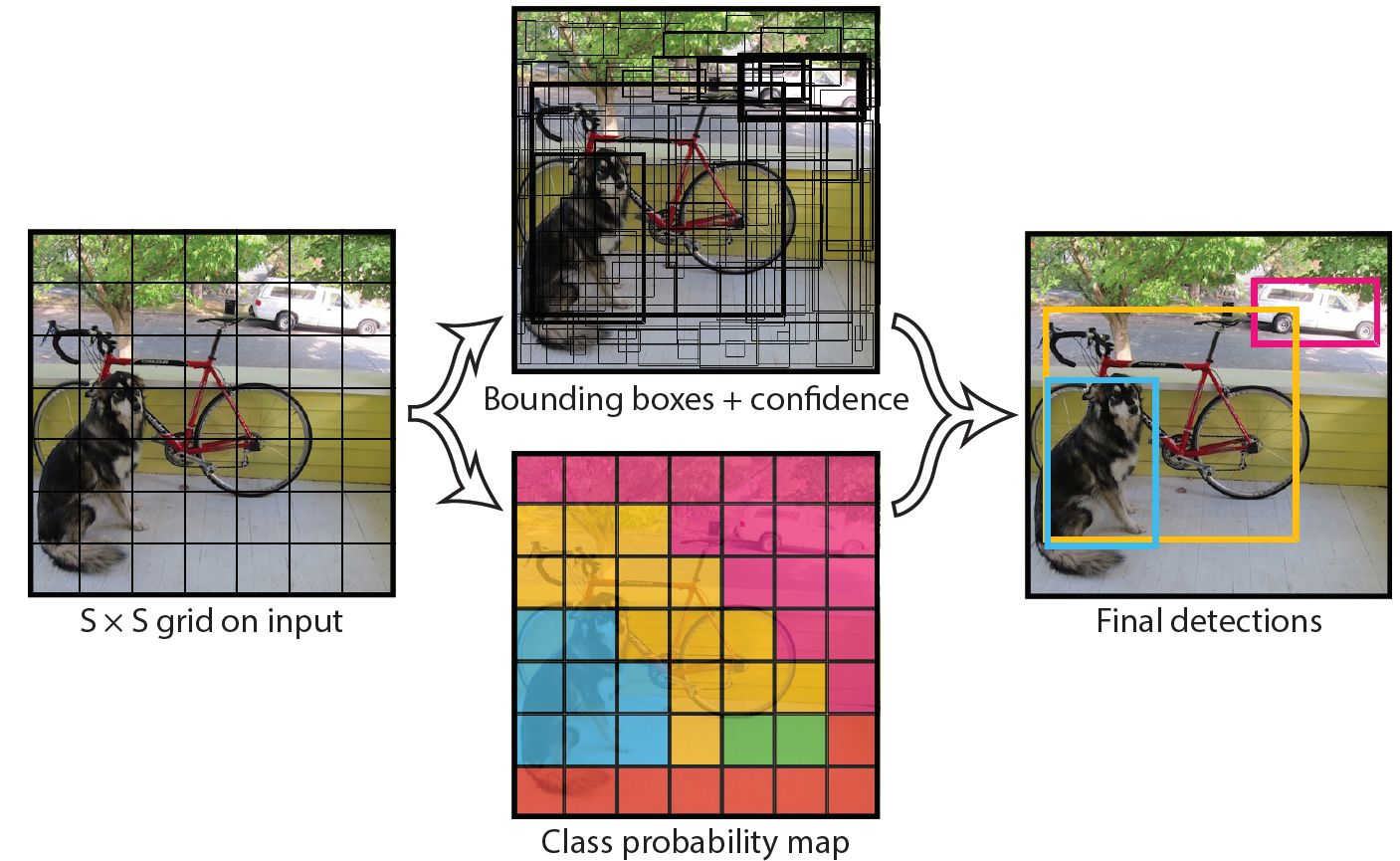
图2 YOLOv1模型预测示意图
YOLO的CNN网络将输入的图片分割成S*S的网格,然后每个单元格负责去检测那些中心落入其中的目标,最后该单元格会预测B(v1中B为2)个边界框(bounding box)以及边界框的置信度(confidence score)。
备注:这就是YOLO系列的设计范式——逐网格查找;以下是针对v1版本对该范式的详细分析。
对上面的话逐字阅读后,会产生以下疑问:
1)怎么确认单元格是否对应目标?
这是对网络进行训练的结果,可以看作是一个二分类,其结果记为 Pr(object)。假如我们的目标是狗、自行车、汽车,预测单元格cell1对应的目标是狗,则Pr(object)=1;预测单元格cell2不在目标之中,则Pr(object)=0。
2)怎么确认边界框的大小与位置?
边界框的大小与位置可以用4个值来表征: (x, y, w, h) ,其中 (x, y) 是边界框的中心坐标,而 w 和 h 是边界框的宽与高。还有一点要注意,中心坐标的预测值 (x, y) 是相对于每个单元格左上角坐标点的偏移值,并且单位是单元格大小。而边界框的 w 和 h 预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在 [0,1] 范围。如图3,图中边界框可以表征为(0.4, 0.6, 0.4, 0.8)。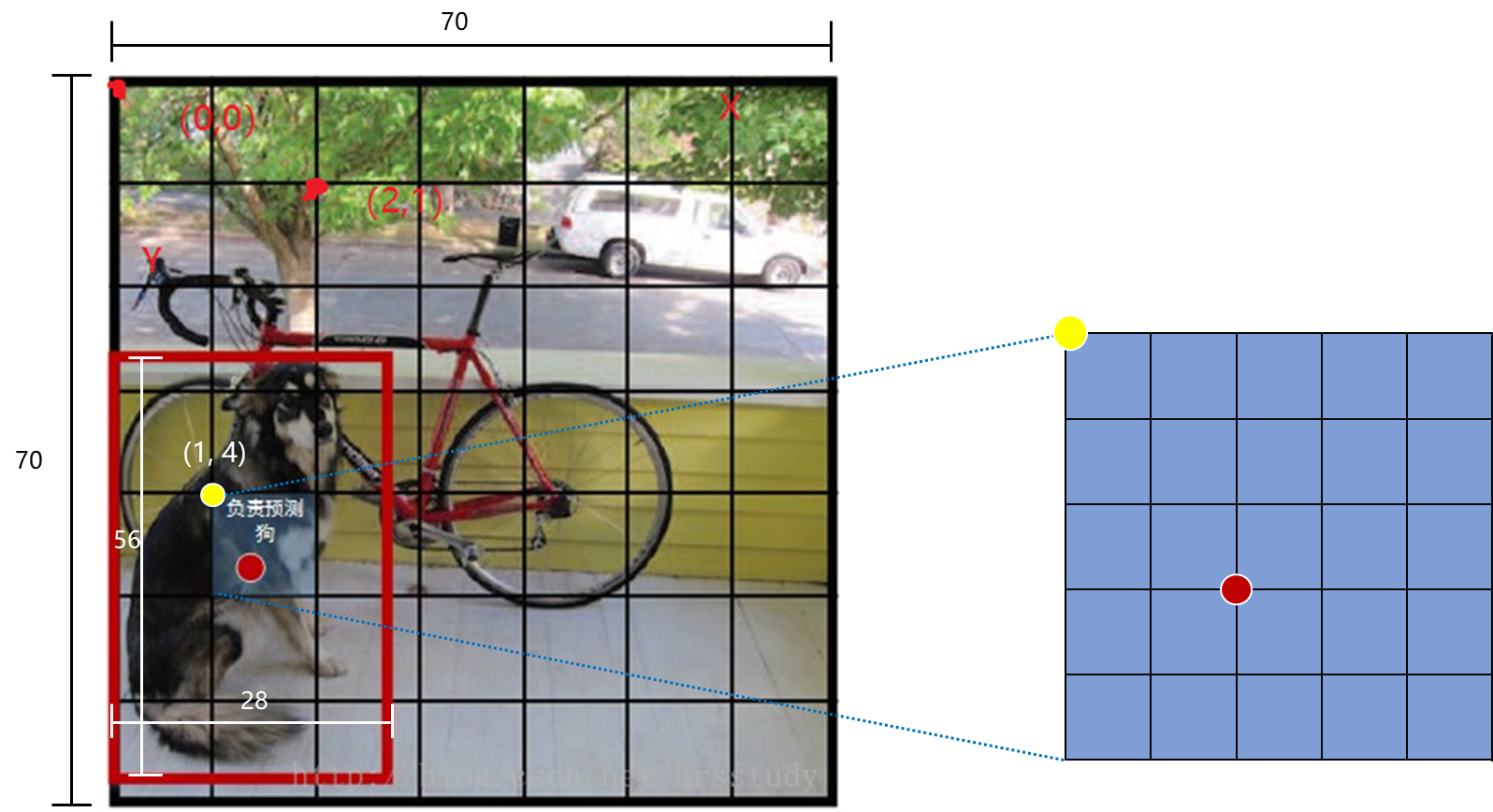
图3 网格划分及边界框示意图
3)边界框的置信度是什么?该怎么计算?
所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者就是指边界框对应的单元格是否对应目标,其用Pr(object)表征,值为0和1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为
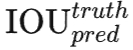
因此置信度可以定义为
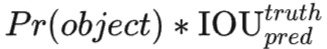 。
。
4)怎么确定含有目标的单元格类别?
对于每一个单元格其还要给出预测出 C个类别概率值,其表征的是由该单元格负责预测的边界框其目标属于各个类别的概率。直白来说,每个单元格只对应一个概率最高的类别(这个在v3及以后做了改变)。但是这些概率值其实是在各个边界框置信度下的条件概率,即Pr(classi|object)。值得注意的是,不管一个单元格预测多少个边界框,其只预测一组类别概率值,这是Yolov1算法的一个缺点。同时,我们可以计算出各个边界框类别置信度(class-specific confidence scores):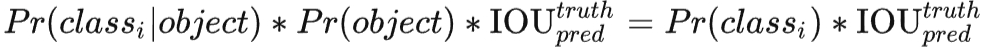
边界框类别置信度表征的是该边界框中目标属于各个类别的可能性大小以及边界框匹配目标的好坏。一般会根据类别置信度使用NMS来过滤网络的预测框。注意和边界框置信度做区分,边界框置信度是对是否含有目标的表征,边界框类别置信度是对含有的目标类别的表征。
5)总结:
每个单元格需要预测 (B∗5+C) 个值。如果将输入图片划分为 S×S 网格,那么最终预测值为 S×S×(B∗5+C) 。yolov1使用的是训练数据是PASCAL VOC数据,对于PASCAL VOC数据,其共有20个类别,如果令 S=7,B=2 ,那么最终的预测结果就是 7×7×30 大小的张量。
2.2. 网络设计
YOLO采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图4所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x, 0, 1)。但是最后一层却采用线性激活函数。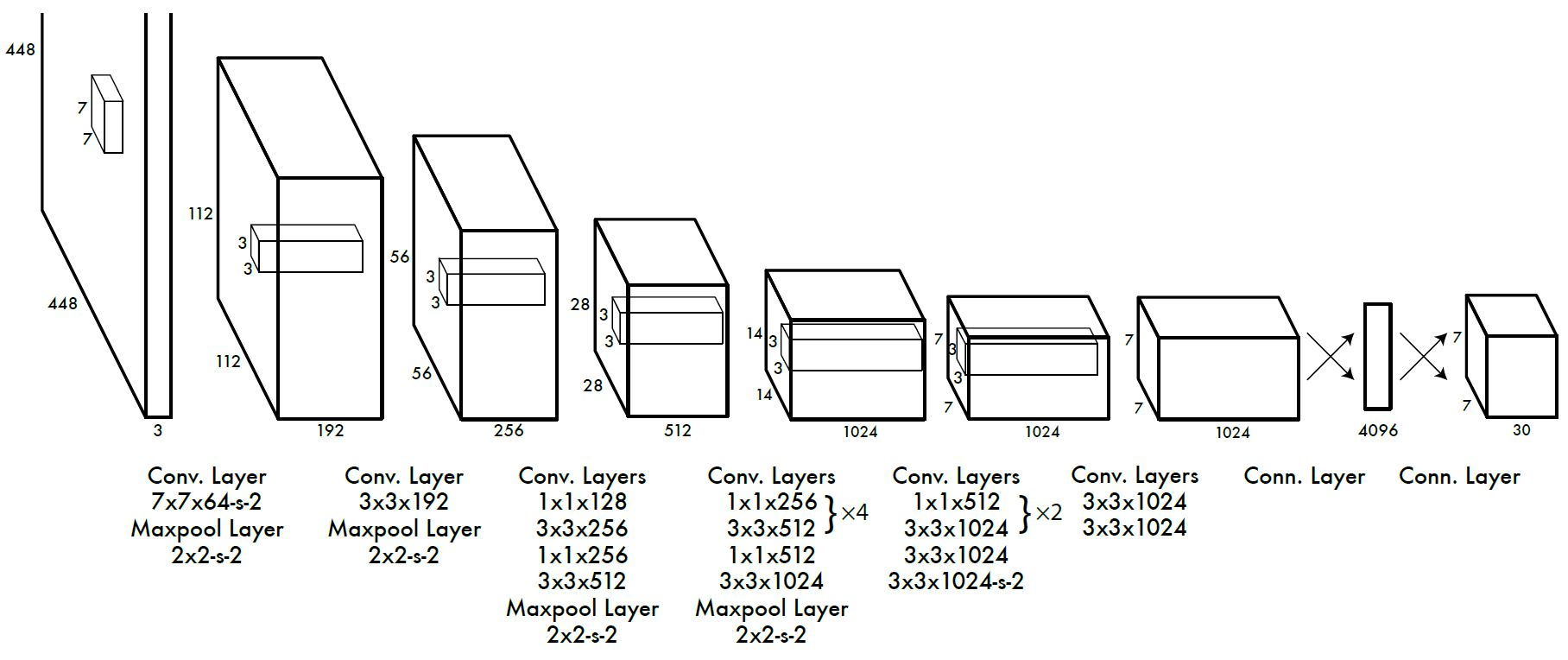
图4 YOLOv1网络结构示意图
可以看到网络的最后输出为 7×7×30 大小的张量。这和前面的讨论是一致的。这个张量所代表的具体含义如图5所示。对于每一个单元格,前20个元素是类别概率值,然后2个元素是边界框置信度,两者相乘可以得到类别置信度,最后8个元素是边界框的 (x, y, w, h) 。大家可能会感到奇怪,对于边界框为什么把置信度 c 和 (x, y, w, h) 都分开排列,而不是按照 (x, y, w, h, c) 这样排列,其实纯粹是为了计算方便,因为实际上这30个元素都是对应一个单元格,其排列是可以任意的。但是分离排布,可以方便地提取每一个部分。这里来解释一下,首先网络的预测值是一个二维张量 P ,其shape为 [batch,7×7×30] 。采用切片,那么 P[:,0:7∗7∗20] 就是类别概率部分,而P[:,7∗7∗20:7∗7∗(20+2)] 是置信度部分,最后剩余部分 P[:,7∗7∗(20+2):] 是边界框的预测结果。这样,提取每个部分是非常方便的,这会方面后面的训练及预测时的计算。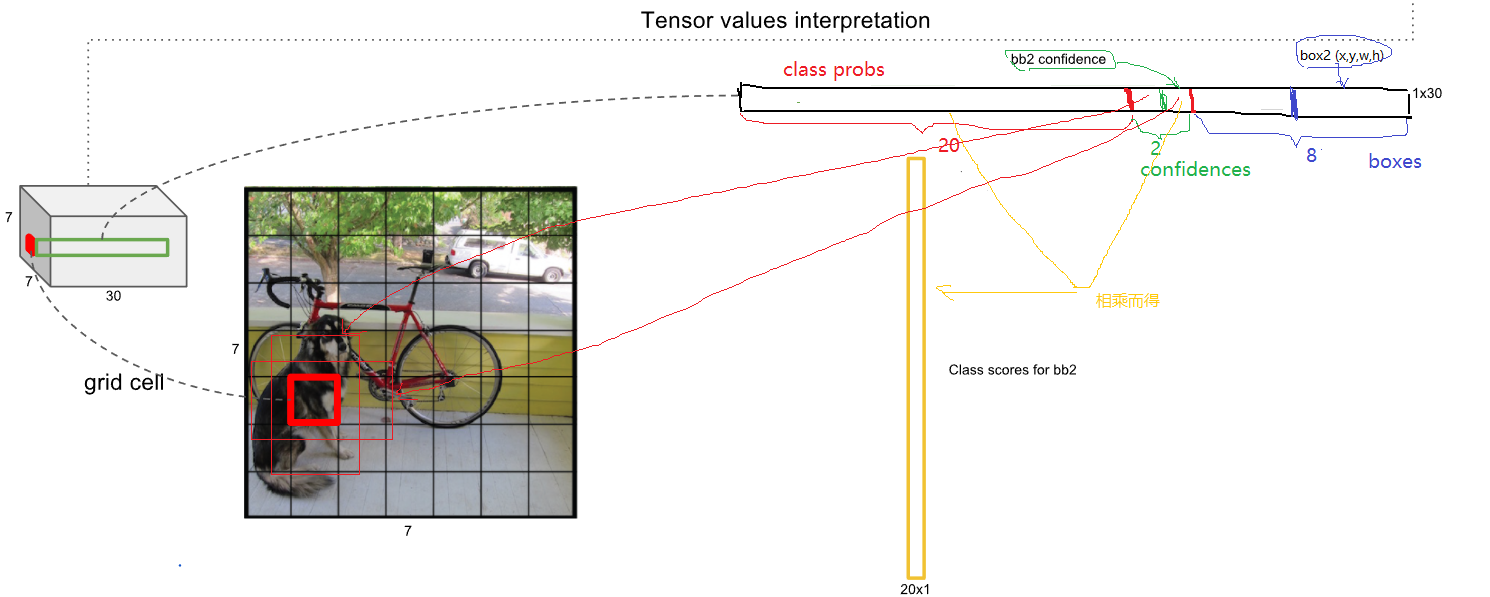
图5 预测张量的解析
3. 目标检测评价指标(mAP)
AP(Average-Precision),平均精度,是主流的目标检测模型的评价指标,通常来说一个越好的分类器,AP值越高。mAP(mean Average Precision)是多个类别AP的平均值,mAP的大小一定在[0,1]区间,越大越好。在目标检测中一般以mPA作为评价指标。
AP指标是基于精确率和召回率,处理多个对象类别,并使用IoU定义一个积极的预测。因此在深入了解AP之前我们需要先了解一下精确率(Precision)、召回率(Recalll)、PR曲线(Precision-recall 曲线)、IoU(Intersection over union)。
众所周知,在进行图像分类训练时我们会将数据集分为正样本和负样本。现在,假设我们有一份正样本(Positive)和负样本(Negative),将样本集输入某模型中进行识别,其结果共有四类。
TP(True Positive):输入的正样本,预测结果是正样本;
FN(False Negative):输入的正样本,预测结果是负样本;
TN(True Negative):输入的是负样本,预测结果是负样本;
FP(False Positive):输入的是负样本,预测结果是正样本。
精确率(Precision),TP/(TP+FP)。即,所有被预测为正的样本中实际为正的样本的概率。
召回率(Recall),TP/(TP+FN)。即,实际为正的样本中被预测为正样本的概率。
PR曲线(Precision-recall 曲线),精准率和召回率的分子是相同,都是TP,但分母是不同的,一个是(TP+FP),一个是(TP+FN)。两者的关系可以用一个P-R图来展示,如下图所示,图中的查全率就是召回率,查准率就是精确率。图中明显看到,如果其中一个非常高,另一个肯定会非常低,因此对于两者我们需要权衡取值找到一个平衡点。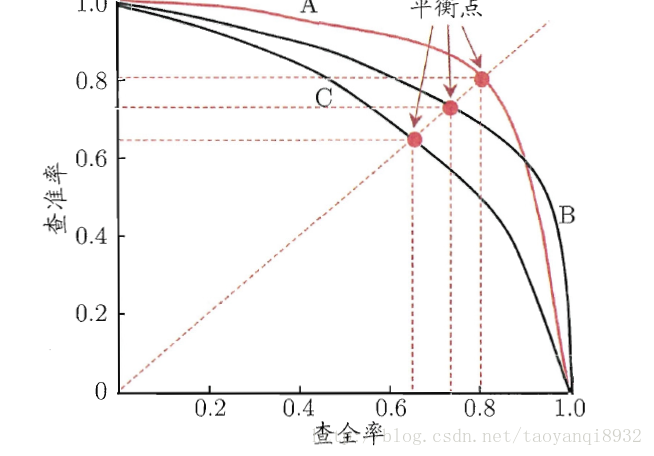
图6 查全率与查准率
简单来说,AP就是PR曲线与坐标轴围成的面积,可表示为,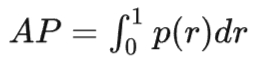
实际计算中,我们并不直接对该PR曲线进行计算,而是对PR曲线进行平滑处理。即对PR曲线上的每个点,Precision的值取该点右侧最大的Precision的值,如下图所示。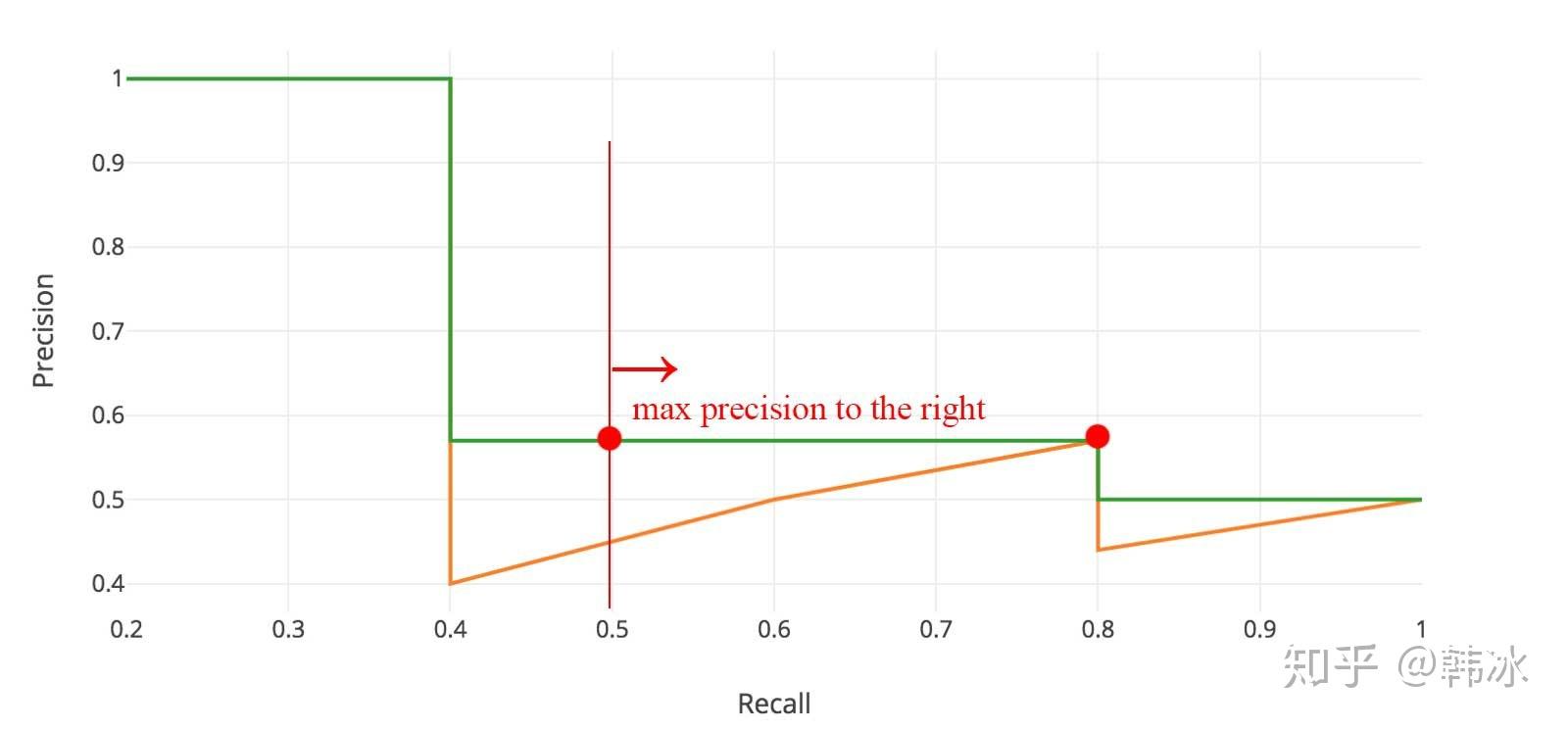
图7 PR曲线的平滑处理
IoU(Intersection over union),交并比IoU衡量的是两个区域的重叠程度,是两个区域重叠部分面积占二者总面积(重叠部分只计算一次)的比例。如下图,两个矩形框的IoU是交叉面积(中间图片红色部分)与合并面积(右图红色部分)面积之比。在目标检测任务中,如果我们模型输出的矩形框与我们人工标注的矩形框的IoU值大于某个阈值时(通常为0.5)即认为我们的模型输出是正确的。
图8 IoU示意
4. 非极大值抑制(NMS)
非极大值抑制(NMS)是物体检测算法中使用的一种后处理技术,用于减少重叠检测框的数量,提高整体检测质量。物体检测算法通常会在同一物体周围产生多个具有不同置信度分数的边界框。NMS过滤掉多余的和不相关的检测框,只保留最准确的检测框。下图显示了一个包含多个重叠边界框的物体检测模型的典型输出和NMS之后的输出。
图9 NMS使用前后
5. 数字系列的YOLO
Joseph Redmon等人的YOLO发表在CVPR 2016。它首次提出了一种实时的端到端物体检测方法,即YOLO。YOLO这个名字代表了 "你只看一次",指的是它只需通过一次网络就能完成检测任务。
本小节对YOLOv1-YOLOv8(YOLO数字系列)做一个简单介绍,用思维导图的形式展现,内容是基于博文:从YOLOv1到YOLOv8的YOLO系列最新综述【2023年4月】_yolo最新版本_香菜烤面包的博客-CSDN博客,本文对相关内容进行提炼。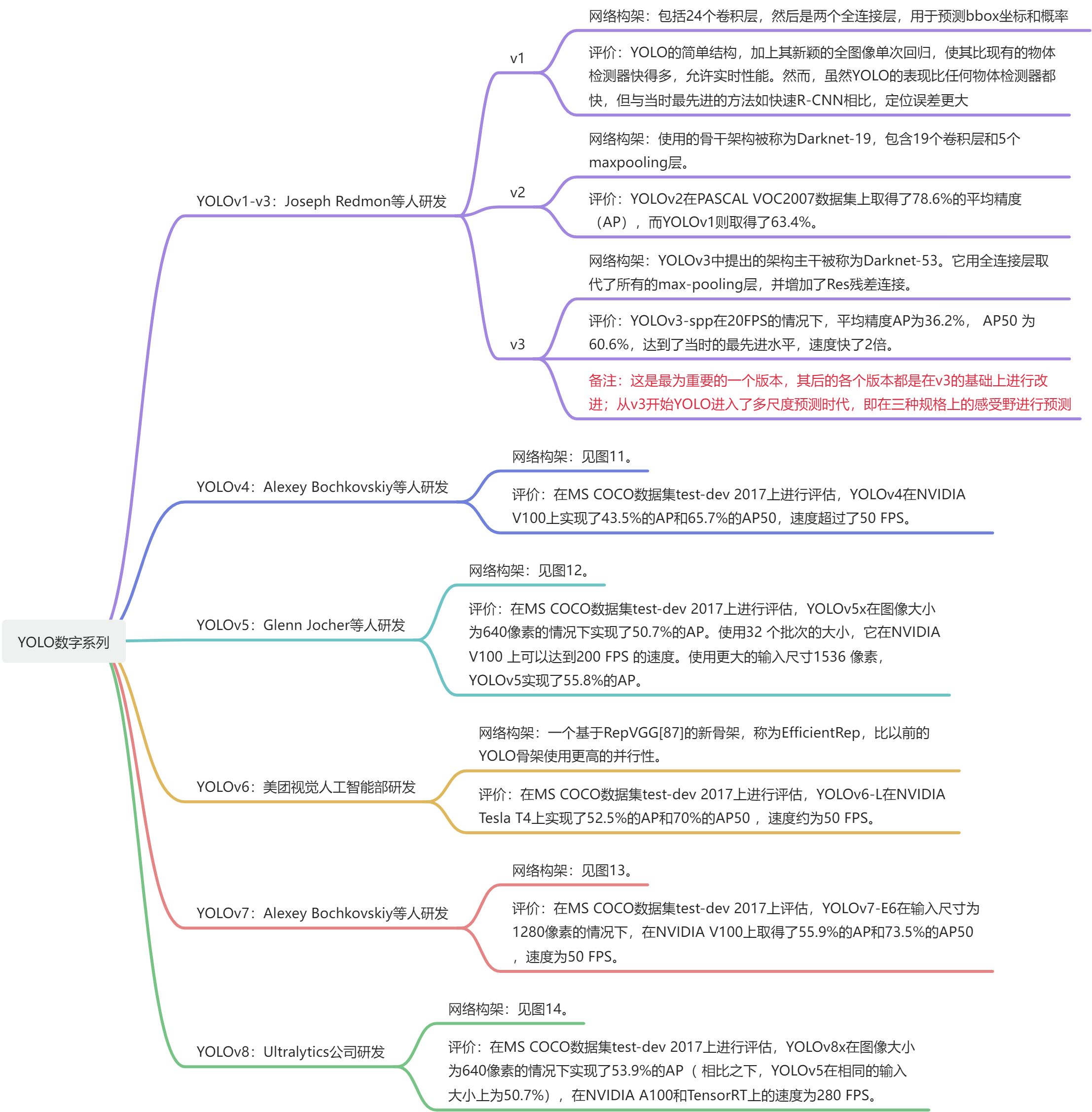
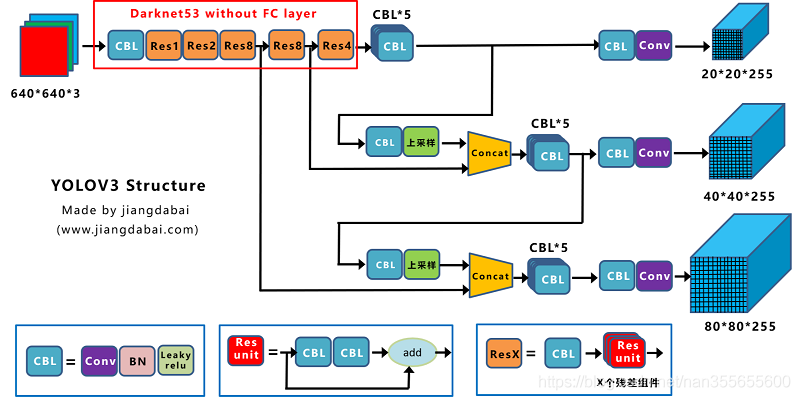
图10-图源:https://blog.csdn.net/nan355655600/article/details/107852288
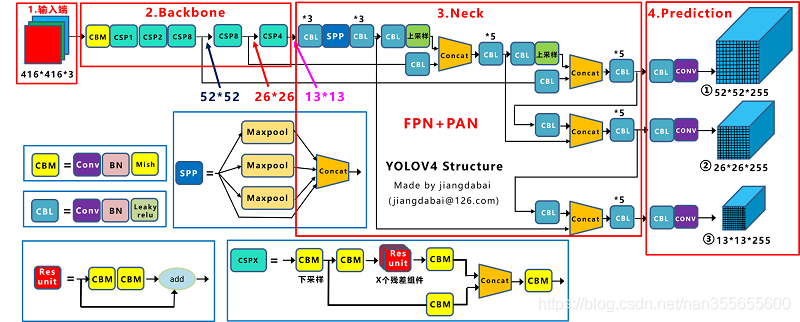
图11-图源:https://blog.csdn.net/nan355655600/article/details/107852288
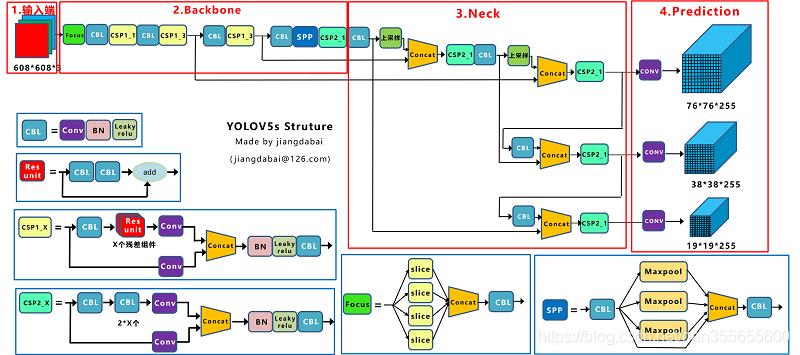
图12-图源:https://blog.csdn.net/nan355655600/article/details/107852288
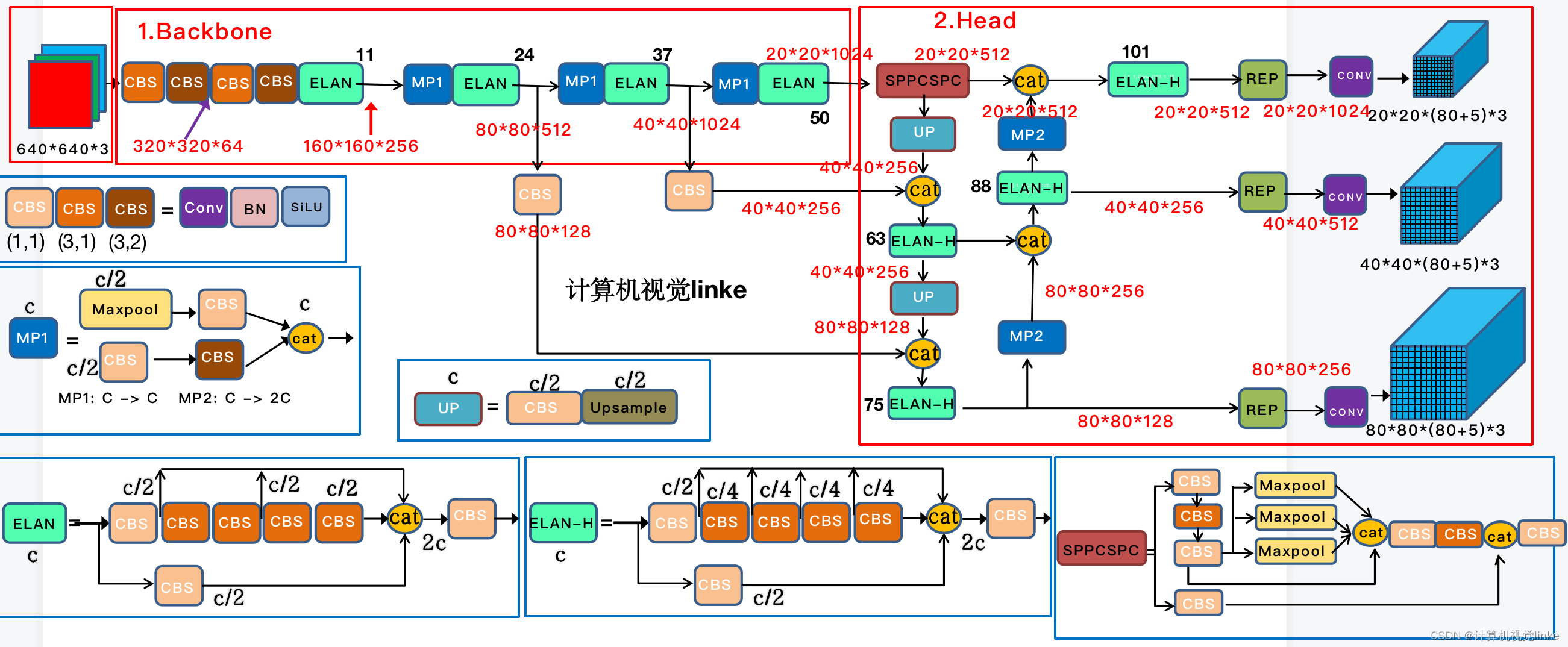
图13-图源:https://blog.csdn.net/u010899190/article/details/125883770
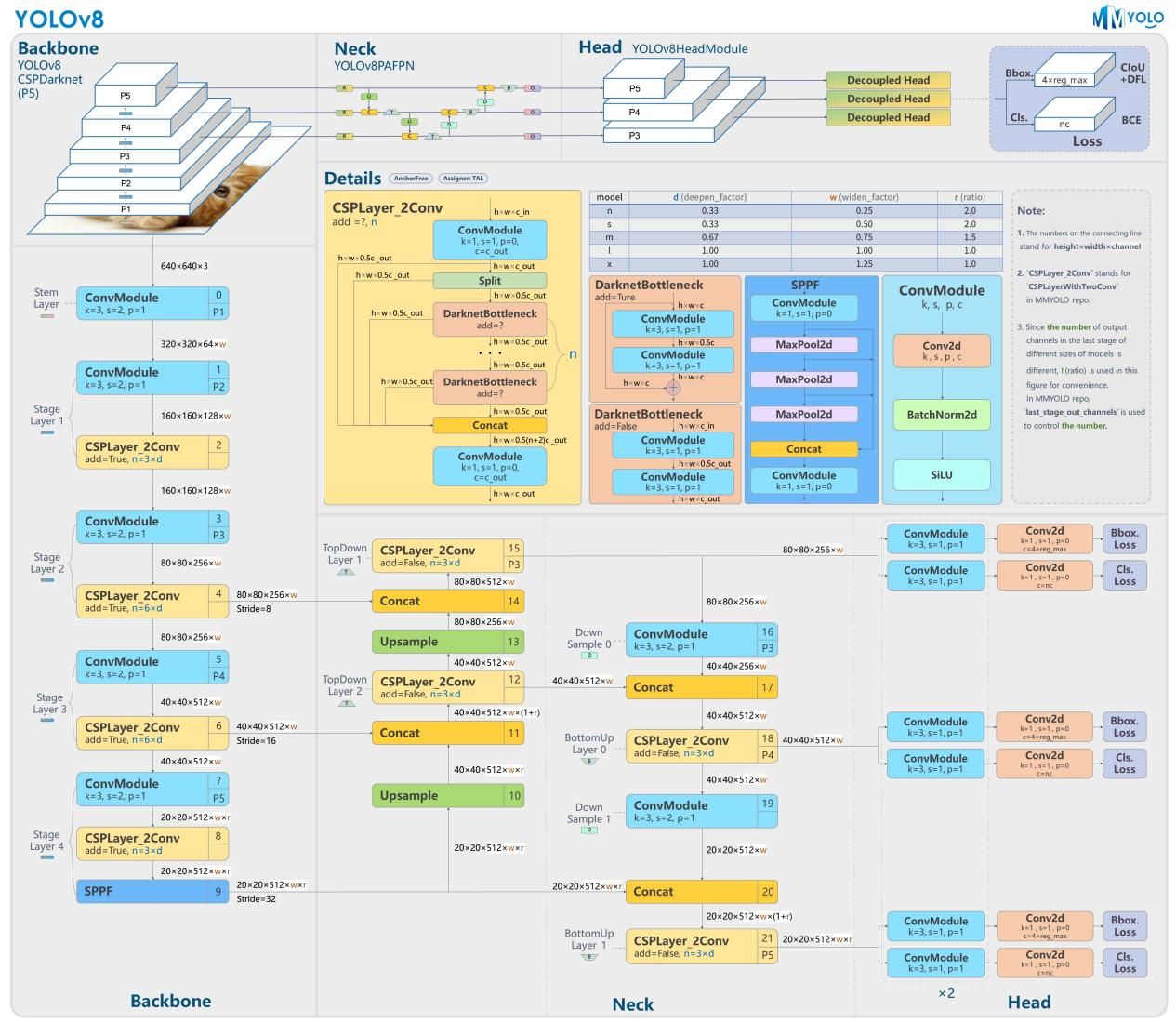
图14-图源:https://zhuanlan.zhihu.com/p/650112468
备注:1)图14中的的构架内容是比较早期的版本,现v5已经更新到了7.x版本,内容上有改动,但总体思路是不变的;2)图片的绘制作者为了能够和v3与v4版本进行比较,输入图片的格式设置为了608608,实际上v5的输入图片是640640。
小结
观察下图,我们可以从锚框、深度学习框架、骨干网络、性能四个方面对YOLO系列做一个总结。
- 锚框Anchor:最初的YOLO模型相对简单,没有采用锚点,而最先进的模型则依赖于带有锚点的两阶段检测器。YOLOv2采用了锚点,从而提高了边界盒的预测精度。这种趋势持续了五年,直到YOLOX引入了一个无锚的方法,取得了最先进的结果。从那时起,随后的YOLO版本已经放弃了锚的使用;
- 深度学习框架:最初,YOLO是使用Darknet框架开发的,后续版本也是如此。然而,当Ultralytics将YOLOv3 移植到PyTorch时,其余的YOLO版本都是使用PyTorch开发的,导致了增强功能的激增。另一个利用的深度学习框架是PaddlePaddle,一个最初由百度开发的开源框架;
- 骨干网络Backbone:YOLO模型的骨干架构随着时间的推移发生了重大变化。从由简单的卷积层和最大集合层组成的Darknet架构开始,后来的模型在YOLOv4中加入了跨阶段部分连接(CSP),在YOLOv6和YOLOv7中加入了重新参数化,并在DAMO-YOLO中加入了神经架构搜索;
- 性能:虽然YOLO模型的性能随着时间的推移有所提高,但值得注意的是,它们往往优先考虑平衡速度和准确性,而不是只关注准确性。这种权衡是YOLO框架的一个重要方面,允许在各种应用中进行实时物体检测。
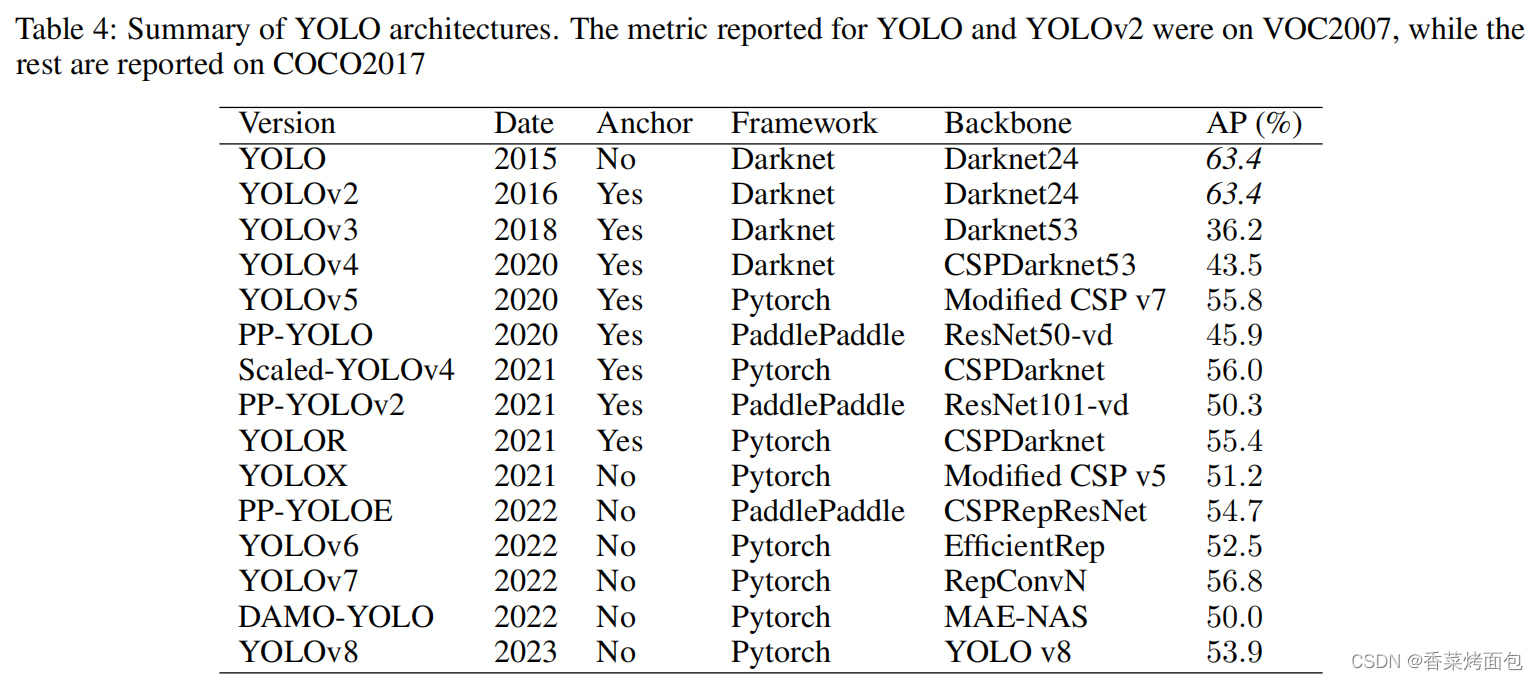
图15-图源:https://blog.csdn.net/daydayup858/article/details/130018935
6. 在不同领域的应用
YOLO已经被应用到了诸多领域,如自主车辆系统,能够快速识别和跟踪各种物体,如车辆、行人、自行车和其他障碍物;农业,能够检测和分类农作物、害虫和疾病,协助精准农业技术和自动化耕作过程;医学,能够用于癌症检测、皮肤分割和药片识别,从而提高诊断的准确性和更有效的治疗过程;遥感领域,能够用于卫星和航空图像中的物体检测和分类,有助于土地利用绘图、城市规划和环境监测;安防系统,能够快速检测可疑活动、社会距离和脸部面具检测;交通领域,被用于车牌检测和交通标志识别等任务。
7. 参考内容
- 从YOLOv1到YOLOv8的YOLO系列最新综述【2023年4月】_yolo最新版本_香菜烤面包的博客-CSDN博客
- 目标检测|YOLO原理与实现
- 深入浅出Yolo系列之Yolov5核心基础知识完整讲解
- 目标检测中的AP,mAP
【pytorch】目标检测:YOLO的基本原理与YOLO系列的网络结构的更多相关文章
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- 论文 | YOLO(You Only Look Once)目标检测
论文:You Only Look Once: Unified, Real-Time Object Detection 原文链接:https://arxiv.org/abs/1506.02640 背景介 ...
- Yolo:实时目标检测实战(下)
Yolo:实时目标检测实战(下) YOLO:Real-Time Object Detection After a few minutes, this script will generate all ...
- Yolo:实时目标检测实战(上)
Yolo:实时目标检测实战(上) YOLO:Real-Time Object Detection 你只看一次(YOLO)是一个最先进的实时物体检测系统.在帕斯卡泰坦X上,它以每秒30帧的速度处理图像, ...
- 从零开始实现SSD目标检测(pytorch)(一)
目录 从零开始实现SSD目标检测(pytorch) 第一章 相关概念概述 1.1 检测框表示 1.2 交并比 第二章 基础网络 2.1 基础网络 2.2 附加网络 第三章 先验框设计 3.1 引言 3 ...
- YOLO_Online 将深度学习最火的目标检测做成在线服务实战经验分享
YOLO_Online 将深度学习最火的目标检测做成在线服务 第一次接触 YOLO 这个目标检测项目的时候,我就在想,怎么样能够封装一下让普通人也能够体验深度学习最火的目标检测项目,不需要关注技术细节 ...
- 目标检测算法之YOLOv1与v2
YOLO:You Only Look Once(只需看一眼) 基于深度学习方法的一个特点就是实现端到端的检测,相对于其他目标检测与识别方法(如Fast R-CNN)将目标识别任务分成目标区域预测和类别 ...
- [AI开发]目标检测之素材标注
算力和数据是影响深度学习应用效果的两个关键因素,在算力满足条件的情况下,为了到达更好的效果,我们需要将海量.高质量的素材数据喂给神经网络,训练出高精度的网络模型.吴恩达在深度学习公开课中提到,在算力满 ...
- One Stage目标检测
在计算机视觉中,目标检测是一个难题.在大型项目中,首先需要先进行目标检测,得到对应类别和坐标后,才进行之后的各种分析.如人脸识别,通常是首先人脸检测,得到人脸的目标框,再对此目标框进行人脸识别.如果该 ...
随机推荐
- 2022-01-29:连接词。 给你一个 不含重复 单词的字符串数组 words ,请你找出并返回 words 中的所有 连接词 。 连接词 定义为:一个完全由给定数组中的至少两个较短单词组成的字符串
2022-01-29:连接词. 给你一个 不含重复 单词的字符串数组 words ,请你找出并返回 words 中的所有 连接词 . 连接词 定义为:一个完全由给定数组中的至少两个较短单词组成的字符串 ...
- 第十三届蓝桥杯c++b组国赛题解(还在持续更新中...)
试题A:2022 解题思路: 有2022个物品,它们的编号分别是1到2022,它们的价值分别等于它们的编号.也就是说,有2022种物品,物品价值等于物品编号. 从2022个物品种选取10个物品,满足1 ...
- rest framework 学习 序列化
序列化功能:对请求数据进行验证和对Queryset进行序列化 Queryset进行序列化: 1 序列化之Serializer 1 class UserInfoSerializ ...
- YOLOV5实时检测屏幕
YOLOV5实时检测屏幕 目录 YOLOV5实时检测屏幕 思考部分 先把原本的detect.py的代码贴在这里 分析代码并删减不用的部分 把屏幕的截图通过OpenCV进行显示 写一个屏幕截图的文件 用 ...
- 基于 Web 的 Linux 终端 WebTerminal
有时候用公共电脑,或者在没有安装 putty.xshell 之类的终端的电脑上访问或展示服务器上的一些资料数据,甚至是在运维平台开发中想要嵌入 WebTerminal 功能,于是找到了这个项目--基于 ...
- 聊聊Cola-StateMachine轻量级状态机的实现
背景 在分析Seata的saga模式实现时,实在是被其复杂的 json 状态语言定义文件劝退,我是有点没想明白为啥要用这么来实现状态机:盲猜可能是基于可视化的状态机设计器来定制化流程,更方便快捷且上手 ...
- .netcore中的虚拟文件EmbeddedFile
以前一直比较好奇像swagger,cap,skywalking等组件是如何实现引用一个dll即可在网页上展示界面的,难道这么多html,js,css等都是硬编码写死在代码文件中的?后面接触apb里面也 ...
- 沉思篇-剖析JetPack的Lifecycle
这几年,对于Android开发者来说,最时髦的技术当属Jetpack了.谷歌官方从19年开始,就在极力推动Jetpack的使用,经过这几年的发展,Jetpack也基本完成了当时的设计目标--简单,一致 ...
- 前端学习C语言 - 函数和关键字
函数和关键字 本篇主要介绍:自定义函数.宏函数.字符串处理函数和关键字. 自定义函数 基本用法 实现一个 add() 函数.请看示例: #include <stdio.h> // 自定义函 ...
- C#/.Net的多播委托到底是啥?彻底剖析下
前言 委托在.Net里面被托管代码封装了之后,看起来似乎有些复杂.但是实际上委托即是函数指针,而多播委托,即是函数指针链.本篇来只涉及底层的逻辑,慎入. 概括 1.示例代码 public delega ...