反向传播(Backpropagation)相关思想
在前面我们学习了SVM损失函数和softmax损失函数,我们优化权重矩阵w的具体思路便是让损失函数最小化,还记得损失函数的定义吗?
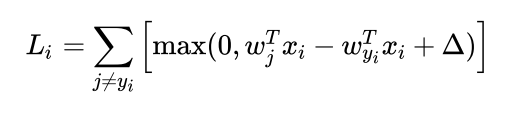
没错,损失函数长这样,其中,Wj为权重矩阵的第j个列向量,xi为第i个train image reshape得到的列向量(其中的每一个维度为Xi的所对应的特征或者说属性),wx的意义为Xi在第j个类上的得分,Wyi正确的类别所对应的权重矩阵,那么显然后续的乘积为正确类别的得分。这个函数对于同类/不同类的梯度我们通过微积分的方法可以很轻松的得到,即只需要简单的进行求导即可:
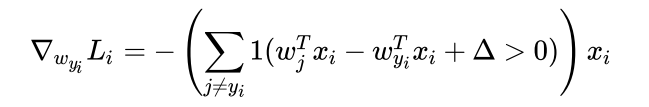
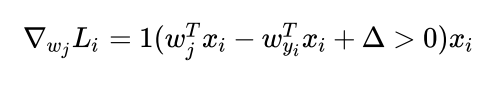
其中1()为指示函数,若指示函数内部逻辑表达式的值为1,则指示函数的值为1,反之则为0。其中第一个等式W对于正确的类的梯度,对于其他类的梯度则为第二个等式,下面将简单推导为什么是这样:
如果我们对于Wyi求偏导,即考虑正确类别对于损失函数的贡献:由于前面有一个求和符号,Li中的每一项有两种取值,0或者是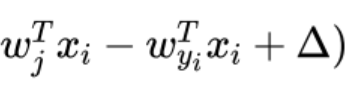 ,那么我们求导的结果也有两种,第一种是0,另一种则为-xi,所以写成指示函数的形式即为上面第一个式子,关于求和符号:因为我们要考虑正确类别对于损失的贡献,我们需要考虑正确类别关于除正确类别外所有可能的情况的贡献,故需要遍历所有的类,判断其是否有损失。对于第二个式子,我们对于Wj求偏导,前面的求和符号消失了,这是由于我们考虑特定的第j列对于损失函数的贡献,第j列是否构成损失,则显然只取决于这一列与正确类之间得分差距是否在安全边界之内,故求和符号消失。
,那么我们求导的结果也有两种,第一种是0,另一种则为-xi,所以写成指示函数的形式即为上面第一个式子,关于求和符号:因为我们要考虑正确类别对于损失的贡献,我们需要考虑正确类别关于除正确类别外所有可能的情况的贡献,故需要遍历所有的类,判断其是否有损失。对于第二个式子,我们对于Wj求偏导,前面的求和符号消失了,这是由于我们考虑特定的第j列对于损失函数的贡献,第j列是否构成损失,则显然只取决于这一列与正确类之间得分差距是否在安全边界之内,故求和符号消失。


1 loss = 0
2 dW = np.zeros(W.shape) # initialize the gradient as zero
3 num_train=X.shape[0]
4 num_class=W.shape[1]
5 score=X.dot(W)
6 correct_score=score[np.arange(num_train),y].reshape(num_train,1) #正确的分数是y的那一列 将其压缩为行向量
7 margin=np.maximum(0,score-correct_score+1)
8 margin[np.arange(num_train),y]=0 #同理,将正确的划分那行的分数重置为0
9 loss=margin.sum()/num_train
10 loss+=reg*np.sum(W*W)
11 margin[margin>0]=1
12 correct_num=np.sum(margin,axis=1)
13 margin[np.arange(num_train),y]-=correct_num
14 dW=X.T.dot(margin)/num_train
15 dW+=2*reg*W
SVM损失函数及梯度计算方法
类似的,我们可以写出Softmax损失函数的写法:
1 loss, dx = 0.0, None
2 num_train=x.shape[0]
3 x=np.exp(x)
4 temp=np.sum(x,axis=1)
5 soft_max=x/temp.reshape(num_train,1)
6 loss_i=-np.sum(np.log(soft_max[np.arange(num_train),y]))
7 loss+=loss_i
8 loss/=num_train
9 soft_max[np.arange(num_train),y]-=1
10 dx=soft_max/num_train
Softmax损失函数及梯度(若此时映射为ReLU)
以上便是SVM中梯度的计算,显然,我们的梯度计算十分的繁琐。这个繁琐体现的并不是有关矩阵上,而是在推导过程上,我们想象:如果损失函数并不是这么简单的形式,而是一个超级超级复杂的多项式的复合,或是一个超级复杂的多元函数,那么我们对于这个多元函数求梯度显然要求某一点的偏导数,显然,我们很容易计算出问题,那么我们便可以考虑反向传播Backpropagation:
反向传播应用了大学微积分中链式法则的思想,我们考虑一个等式:f(x,y,z)=(x+y)z,我们要求他的偏导数相当容易,那么很显然:f对于z的偏导为x,f对于y的偏导为z,f对于x的偏导为z,这很简单,我们考虑换元法:即将内部所有的计算单元构成一个节点,最后的表达式为若干节点进行简单运算的叠加。如图所示,我们令q=x+y,则整个函数的表达式可以看做是f=qz,将括号项消除。那么这么做有什么优点呢,我们考虑f(x,y,z)=f(q,z),则f对于x的偏导数由链式法则可以写为 ,如果没有图的例子我们很难理解链式法则的精妙之处,我们结合下面的图说明问题:
,如果没有图的例子我们很难理解链式法则的精妙之处,我们结合下面的图说明问题:
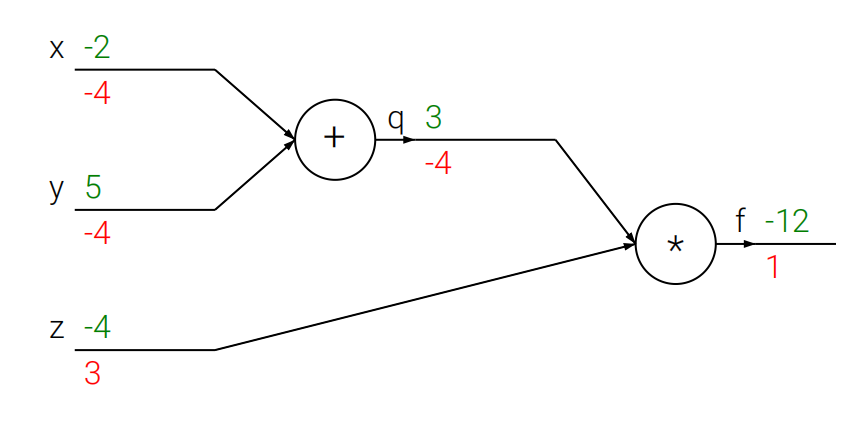
我们从后往前推理:最后f对于f的偏导数显然为,在考虑前面的节点q,f对于q的偏导根据链式法则,等价于f对于f的偏导乘以f对于q的偏导,那么f关于q的偏导由于我们的函数解析式为f=qz,则关于q的偏导数为z,继续向前考虑:q节点相连的是x和y节点,那么对于x而言,f对于x的偏导等价于f对于q的偏导乘以q对于x的偏导,而q=x+y,则q对于x的偏导就是1,那么整体的偏导就是-4,节点y同理,看最下面的z节点,我们的z没有经过换元处理,所以f关于z的偏导就等价于f关于f的偏导乘以f关于z的偏导,由解析式,我们很轻松的能得到:f=qz,那么偏导数的值即为q。
大家不知道有没有发现我在表述上的特点:明明f对于q的偏导就是f对于q的偏导,我为什么要说成f对于f的偏导乘以f对于q的偏导呢。答案就在于链式法则上:我们不难发现,链式法则中有若干个两项相乘再相加(由链式法则的定义不难得到),那么这两项中,必然有一项是在该节点计算能够得到的,如图中的q对于x的偏导,而另外一项,则是后面的式子对于前面式子的“影响”。如图中的f对于q的偏导数,我们惊喜的发现f对于q的偏导数在前面已经计算过了,我们可以直接拿过来用,那么我们很轻松的就能得到总体函数f对于该点处的变量的偏导数:即为此节点的偏导数与上游节点传递给次节点的偏导数值的乘积。
这个结论有什么用呢?我们考虑,一个函数哪怕再复杂,也是由若干简单运算(+-*/以及log,e等运算)经复合而成的,对于每一个这种运算,我们非常轻松的能求出他的偏导数,根据我们上文提到的结论,我们就能很轻松的得到整个函数关于任意变量的偏导数值,也即能得到任意一点的梯度值;
我们再来看一个相对复杂一点的例子:

这个函数的表达式为 ,相对而言,super复杂,如果不用反向传播的方法,硬求导+代入值表示梯度,显然可行,但是计算量及其大,而且很容易出错,那么用我们的反向传播算法就很轻松的能解决这个问题,下面我们来解析一下这个图:首先是有五个输入端口,w0,w1,w2,x0,x1,我们将整个函数根据运算进行分解:首先很显然,有两个乘法节点:q=w0x0,p=w1x1.在p和q运算结束后,相加,即有一个加法节点m=p+q,再与w2相加,n=m+w2,即又有一个加法节点,在之后,取一个负号:b=-n,然后取一个以e为底的指数:a=exp(b),然后继续进行加法运算:c=a+1,然后整个进行取一个倒数(可以看做除法运算):g=1/c。f=g这样,我们就将整个较为复杂的函数切割为若干节点进行分析了。我们从后面开始:仍然同理,f对f求导,就是1,然后将df/df传递到前面的节点,考虑前面的节点,g,df/dg=df/df*df/dg,所以df/dg=1,将此值继续向前传递到节点c:df/dc=df/dg*dg/dc,所以df/dc=dg/dc,由于g=1/c,所以dg/dc=-1/c方,然后根据此时c的值:1/0.73,得到答案:dg/dc=-0.53。故df/dc=-0.53,继续将此值向前传递:到节点a:df/da=df/dc*dc/da,由于dc/da=1,于是df/da=-0.53不变,继续向前传递到节点b:df/db=df/da*da/db,考虑a与b的关系:a=exp(b),故da/db=exp(b),由于b的值为-1,故exp(b)=0.37,所以df/db=-0.53*0.37=-0.2.继续将此值向前传递:到节点n:df/dn=df/db*db/dn,考虑b=-n,于是db/dn=-1,所以df/dn=-1*-0.2=0.2.然后遇到分叉,先考虑下面的分叉:到节点w2:df/dw2=df/dn*dn/dw2,由于n=m+w2,所以dn/dw2=1,于是df/dw2=0.2。然后考虑上面的节点m,同理,df/dm=df/dn*dn/dm,dn/dm=1,所以df/dm=0.2,考虑将m节点传输到p和q,由于pq都是系数为1的加法组合,故df/dq=df/dp=0.2。
,相对而言,super复杂,如果不用反向传播的方法,硬求导+代入值表示梯度,显然可行,但是计算量及其大,而且很容易出错,那么用我们的反向传播算法就很轻松的能解决这个问题,下面我们来解析一下这个图:首先是有五个输入端口,w0,w1,w2,x0,x1,我们将整个函数根据运算进行分解:首先很显然,有两个乘法节点:q=w0x0,p=w1x1.在p和q运算结束后,相加,即有一个加法节点m=p+q,再与w2相加,n=m+w2,即又有一个加法节点,在之后,取一个负号:b=-n,然后取一个以e为底的指数:a=exp(b),然后继续进行加法运算:c=a+1,然后整个进行取一个倒数(可以看做除法运算):g=1/c。f=g这样,我们就将整个较为复杂的函数切割为若干节点进行分析了。我们从后面开始:仍然同理,f对f求导,就是1,然后将df/df传递到前面的节点,考虑前面的节点,g,df/dg=df/df*df/dg,所以df/dg=1,将此值继续向前传递到节点c:df/dc=df/dg*dg/dc,所以df/dc=dg/dc,由于g=1/c,所以dg/dc=-1/c方,然后根据此时c的值:1/0.73,得到答案:dg/dc=-0.53。故df/dc=-0.53,继续将此值向前传递:到节点a:df/da=df/dc*dc/da,由于dc/da=1,于是df/da=-0.53不变,继续向前传递到节点b:df/db=df/da*da/db,考虑a与b的关系:a=exp(b),故da/db=exp(b),由于b的值为-1,故exp(b)=0.37,所以df/db=-0.53*0.37=-0.2.继续将此值向前传递:到节点n:df/dn=df/db*db/dn,考虑b=-n,于是db/dn=-1,所以df/dn=-1*-0.2=0.2.然后遇到分叉,先考虑下面的分叉:到节点w2:df/dw2=df/dn*dn/dw2,由于n=m+w2,所以dn/dw2=1,于是df/dw2=0.2。然后考虑上面的节点m,同理,df/dm=df/dn*dn/dm,dn/dm=1,所以df/dm=0.2,考虑将m节点传输到p和q,由于pq都是系数为1的加法组合,故df/dq=df/dp=0.2。
然后分别考虑节点w0,x0,w1,x1,在这里仅举一组例子:考虑w0:df/dw0=df/dq*dq/dw0。考虑q=w0x0,所以dq/dw0=x0,同理dq/dx0=w0,所以很轻松能得到:df/dw0=df/dp*-1=-0.2,df/dx0=df/dp*2=0.39(因为0.2是保留小数得到的)。
以上便是整个的算法流程,说清楚原理过后我们考虑代码实现:在进行算法前,我们先观察上述的代码流程:我们需要先从头完整的计算一遍整个函数,即正向传播并计算节点的值,并存储相应的中间变量的值。然后从最后面开始,每次递归性的应用链式法则。我们都需要用到哪些值?第一,前面节点的导数值,以及前面节点的中间变量,那么我们在正向传递的过程中显然需要先存储中间变量,以及我们还需要调用后续节点的导数值,第二个,便是当前节点的运算符以及相对应的参与运算的变量的值。我们反向传播到当前节点,当前节点的dx=dout(上游节点导数值)*dx(当前节点导数值)。
具体bp算法的实现将在神经网络中应用,请看下篇关于神经网络的博客
反向传播(Backpropagation)相关思想的更多相关文章
- 反向传播BackPropagation
http://www.cnblogs.com/charlotte77/p/5629865.html http://www.cnblogs.com/daniel-D/archive/2013/06/03 ...
- 反向传播 Backpropagation
前向计算:没啥好说的,一层一层套着算就完事了 y = f( ... f( Wlayer2T f( Wlayer1Tx ) ) ) 反向求导:链式法则 单独看一个神经元的计算,z (就是logit)对 ...
- 如何理解反向传播 Backpropagation 梯度下降算法要点
http://colah.github.io/posts/2015-08-Backprop/ http://www.zhihu.com/question/27239198 待翻译 http://blo ...
- 稀疏自动编码之反向传播算法(BP)
假设给定m个训练样本的训练集,用梯度下降法训练一个神经网络,对于单个训练样本(x,y),定义该样本的损失函数: 那么整个训练集的损失函数定义如下: 第一项是所有样本的方差的均值.第二项是一个归一化项( ...
- [DeeplearningAI笔记]序列模型1.3-1.4循环神经网络原理与反向传播公式
5.1循环序列模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.3循环神经网络模型 为什么不使用标准的神经网络 假如将九个单词组成的序列作为输入,通过普通的神经网网络输出输出序列, 在 ...
- 【原】Coursera—Andrew Ng机器学习—编程作业 Programming Exercise 4—反向传播神经网络
课程笔记 Coursera—Andrew Ng机器学习—课程笔记 Lecture 9_Neural Networks learning 作业说明 Exercise 4,Week 5,实现反向传播 ba ...
- CNN反向传播更新权值
背景 反向传播(Backpropagation)是训练神经网络最通用的方法之一,网上有许多文章尝试解释反向传播是如何工作的,但是很少有包括真实数字的例子,这篇博文尝试通过离散的数据解释它是怎样工作的. ...
- PyTorch深度学习实践——反向传播
反向传播 课程来源:PyTorch深度学习实践--河北工业大学 <PyTorch深度学习实践>完结合集_哔哩哔哩_bilibili 目录 反向传播 笔记 作业 笔记 在之前课程中介绍的线性 ...
- 递归神经网络(RNN,Recurrent Neural Networks)和反向传播的指南 A guide to recurrent neural networks and backpropagation(转载)
摘要 这篇文章提供了一个关于递归神经网络中某些概念的指南.与前馈网络不同,RNN可能非常敏感,并且适合于过去的输入(be adapted to past inputs).反向传播学习(backprop ...
- [2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具 TensorFlo ...
随机推荐
- 声网 Agora 音频互动 MoS 分方法:为音频互动体验进行实时打分
在业界,实时音视频的 QoE(Quality of Experience) 方法一直都是个重要的话题,每年 RTE 实时互联网大会都会有议题涉及.之所以这么重要,其实是因为目前 RTE 行业中还没有一 ...
- 浅谈云原生基础入坑与docker 搭建redis-cluster集群
浅谈云原生基础入坑与docker 搭建redis-cluster集群 开篇来点自己的小感触:自从走上后端开发这条无法回头的互卷道路以后,在视野内可见新的技术在迭代,更新的技术在不断发行.就拿最近的Op ...
- 2020寒假学习笔记13------Python基础语法学习(二)
同一运算符 同一运算符用于比较两个对象的存储单元,实际比较的是对象的地址. 运算符 描述 is is 是判断两个标识符是不是引用同一个对象 is not is not 是判断两个标识符是不是引用 ...
- .NetCore中使用分布式事务DTM的二阶段消息
一.概述 二阶段消息是DTM新提出的,可以完美代替现有的事务消息和本地消息表架构.无论从复杂度.性能.便利性还是代码量都是完胜现有的方案. 相比现有的消息架构借助于各种消息中间件比如RocketMQ等 ...
- [ElasticSearch]#解决问题#修改Search Guard密码时 报错:ERR: Seems there is no Elasticsearch running on localhost:9300 - Will exit
问题复现 [root@es2 tools]# ps -ef | grep elasticsearch 9200 22693 1 1 09:31 ? 00:04:54 /usr/bin/java -Xm ...
- AtCoder Beginner Contest 236 E - Average and Median
给定一个序列,要求相邻两个数至少选一个,求选出数的最大平均数和最大中位数 \(\text{sol}\):二分答案. 二分平均数\(\text{mid}\),将每个元素减去\(\text{mid}\), ...
- 如何在微信小程序中实现音视频通话
微信小程序的音视频通话可以通过微信提供的实时音视频能力实现.这个能力包括了音视频采集.编码.传输和解码等多个环节,开发者只需要使用微信提供的 API 接口就可以轻松地实现音视频通话功能. 在具体实现上 ...
- 多线程socketserver
模块:socketserver tcp协议: 服务端: import socketserver class MyRequestHandle(socketserver.BaseRequestHandle ...
- 【云享专刊】开源遇上华为云,OCP架构变身“云原生框架”
摘要:华为云DTSE团队出品云原生改造指南,助力轻松实践OCP上云. 本文分享自华为云社区<[云享专刊]开源遇上华为云,OCP架构变身"云原生框架">,作者:华为云社区 ...
- shopee V2 接口 虾皮货代打包贴单仓储系统,独立部署,系统源码 终身使用,没有任何隐形收费,想怎么用就怎么用 直接就已经对接好了的接口。
shopee V2 接口 虾皮货代打包贴单仓储系统,独立部署,系统源码 终身使用,没有任何隐形收费,想怎么用就怎么用 直接就已经对接好了的接口. 虾皮货代打包 系统虾皮代贴单系统 虾皮跨境平台源码 ...