解决“网页源代码编码形式为utf-8,但爬虫代码设置为decode('utf-8')仍出现汉字乱码”的问题
为了用爬虫获取百度首页的源代码,检查了百度的源代码,显示编码格式为utf-8

但这样写代码,却失败了…..
(这里提示:不要直接复制百度的URL,应该是http,不是https!!!)
# 获取百度首页的源码
import urllib.request
#(1)定义一个URL
url='http://www.baidu.com'
#(2)模拟浏览器向服务器发送请求 要在联网的前提下!
response=urllib.request.urlopen(url)
# (3)获取响应中的页面的源码
# 将二进制转化为字符串,也就是解码 decode('对应页面编码的格式')
content=response.read().decode('utf-8')
# (4)打印数据
print(content)
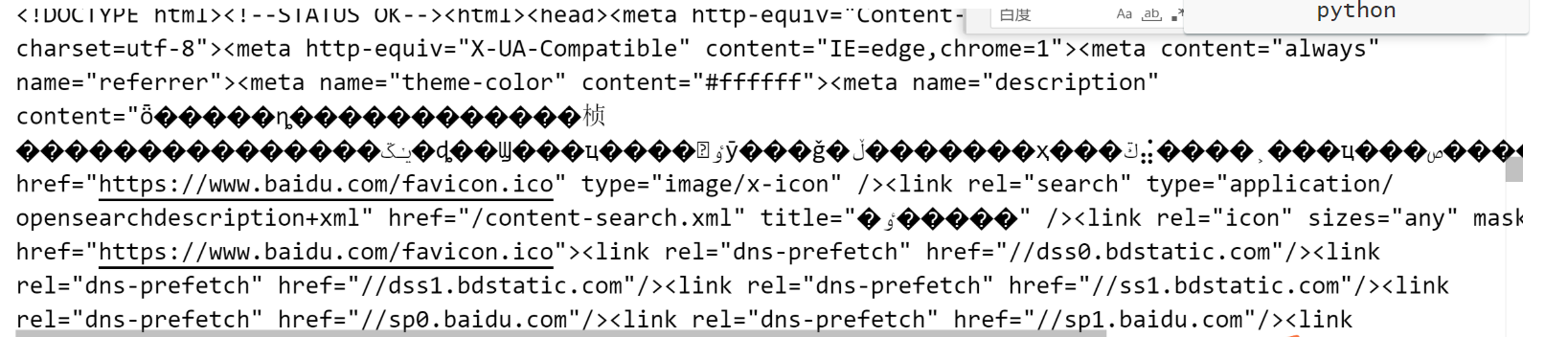
经过查阅资料,发现这样就可以了!成功的代码如下
import urllib.request
import chardet
# 定义一个URL
url = 'http://www.baidu.com'
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(url)
# 获取响应中的页面的源码
content = response.read()
# 检测编码
encoding = chardet.detect(content)['encoding']
# 将二进制转化为字符串,也就是解码
content = content.decode(encoding)
# 打印数据
print(content)
解决“网页源代码编码形式为utf-8,但爬虫代码设置为decode('utf-8')仍出现汉字乱码”的问题的更多相关文章
- 解决EditPlus在设置了UTF-8之后,编写的HTML页面仍出现汉字乱码问题
解决EditPlus在设置了UTF-8之后.编写的HTML页面仍出现汉字乱码问题 相信有些同学在使用EditPlus编写HTML页面时发现,尽管已经设置好了UTF-8的编码格式.但却发现HTML页 ...
- 爬虫如何使用phantomjs无头浏览器解决网页源代码经过渲染的问题(以scrapy框架为例)
一.浏览器的构成 许多开发商提供了商用的浏览器来解释和显示Web文档,而所有这些浏览器几乎都使用相同的体系架构.每一种浏览器(browser)通常由三部分构成:一个控制程序,客户协议和一些解释程序.控 ...
- c#利用HttpWebRequest获取网页源代码
c#利用HttpWebRequest获取网页源代码,搞了好几天终于解决了,直接获取网站编码进行数据读取,再也不用担心乱码了! 命名空间:Using System.Net private static ...
- Java 网络爬虫获取网页源代码原理及实现
Java 网络爬虫获取网页源代码原理及实现 1.网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL ...
- php查看网页源代码的方法
这篇文章主要介绍了php查看网页源代码的方法,涉及php读取网页文件的技巧,具有一定参考借鉴价值,需要的朋友可以参考下 本文实例讲述了php查看网页源代码的方法.分享给大家供大家参考.具体实现 ...
- c#利用WebClient和WebRequest获取网页源代码的比较
前几天举例分析了用asp+xmlhttp获取网页源代码的方法,但c#中一般是可以利用WebClient类和WebRequest类获取网页源代码.下面分别说明这两种方法的实现. WebClient类获取 ...
- URLRedirector 解决网页上无法访问 google CDN 的问题(fonts、ajax、themes、apis等)
URLRedirector 解决网页上无法访问 google CDN 的问题(fonts.ajax.themes.apis等) 由于某些原因,在访问国外的网站时有时候会特别慢,像 stackoverf ...
- 解决asp.net Core Mvc网页汉字乱码问题
跟着www.asp.net网页的教程做电影网站的例子时,将一些英文标签和按钮改成了汉字的,结果出现了乱码. 在网上搜索这方面的信息也不太多,看到大家众说纷纭,最后有解决问题的,也没有说清楚具体的办法, ...
- delphi 获取网页源代码
//获取网页源代码 var s: string; begin s := WebBrowser1.OleObject.document.body.innerHTML; //body内的所有代码 ...
- JS远程获取网页源代码的例子
js代码获取网页源代码. 代码: <!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> < ...
随机推荐
- vue3 如何在 jsx中使用 component 组件
component 组件不像其它的内置组件(tansition.transitionGroup),可以直接从 vue 中直接导出,所有要在 jsx 使用component就要使用 h 函数 使用 vu ...
- Linux搭建ESP-IDF开发环境
下载esp-gitee-tools git clone git@gitee.com:EspressifSystems/esp-gitee-tools.git 替换github网址 cd esp-git ...
- Django - 在后台上传文章封面图 - 并在前端页面展示
需要用到 models.ImageField(), 它继承自 models.FileField(), 用ImageField的时候需要安装pillow pip install pillow -i h ...
- Kubernetes Cluster部署
1.基本环境说明 ip: 192.168.115.149 主机名:node1 CentOS Linux release 7.9.2009,内核版本为3.10.0-1160.81.1.el7.x8 ...
- MySQL学习笔记-索引
索引 索引(index)是帮助MySQL高效获取数据的数据结构(有序).在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现 ...
- JavaSE的运算符
[Top] 算术运算 分类 运算符 算数运算符 * / + - % ++ -- 赋值运算符 +=, -=, /=, *=, %=(扩展赋值运算符), = 比较(关系)运算符 == != > &l ...
- CF914C
problem & blog 数位 dp 模板题. 经过一次操作,可以把 \(n\) 变成一个小于 \(10^3\) 的数. 所以我们可以把所有小于 \(10^3\) 的数操作的次数全部处理出 ...
- CompatTelRunner CPU 占用 22% win10 笔记本常常无故风扇狂转
CompatTelRunner CPU 占用 22% win10 笔记本常常无故风扇狂转 CompatTelRunner.exe is also known as Windows Compatibil ...
- k8s搭建安装 Harbor 私有镜像仓库(本地仓库,内网仓库)
主要参考 https://www.cnblogs.com/wangzy-Zj/p/14011228.html 额外: 1.如果 harbor.yml中的域名和openssl 生成的不一致,你改了hos ...
- C#.NET AES CBC 加密
重点: 1. KEY 和 IV 转 byte[] 时的编码. 2.要加密的字符串转 byte[] 时的编码. 3.AES 的PADDING,MODE. 4.加密后的byte[] 转字符串时的编码. 先 ...