模拟IDC spark读写MaxCompute实践
简介: 现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。
一、背景
1、背景信息
现有湖仓一体架构是以 MaxCompute 为中心读写 Hadoop 集群数据,有些线下 IDC 场景,客户不愿意对公网暴露集群内部信息,需要从 Hadoop 集群发起访问云上的数据。本文以 EMR (云上 Hadoop)方式模拟本地 Hadoop 集群访问 MaxCompute数据。
2、基本架构

二、搭建开发环境
1、EMR环境准备
(1)购买
① 登录阿里云控制台 - 点击右上角控制台选项 https://www.aliyun.com/accounttraceid=bc277aa7c0c64023b459dd695ac328b1jncu

② 进入到导航页 - 点击云产品 - E-MapReduce(也可以搜索)
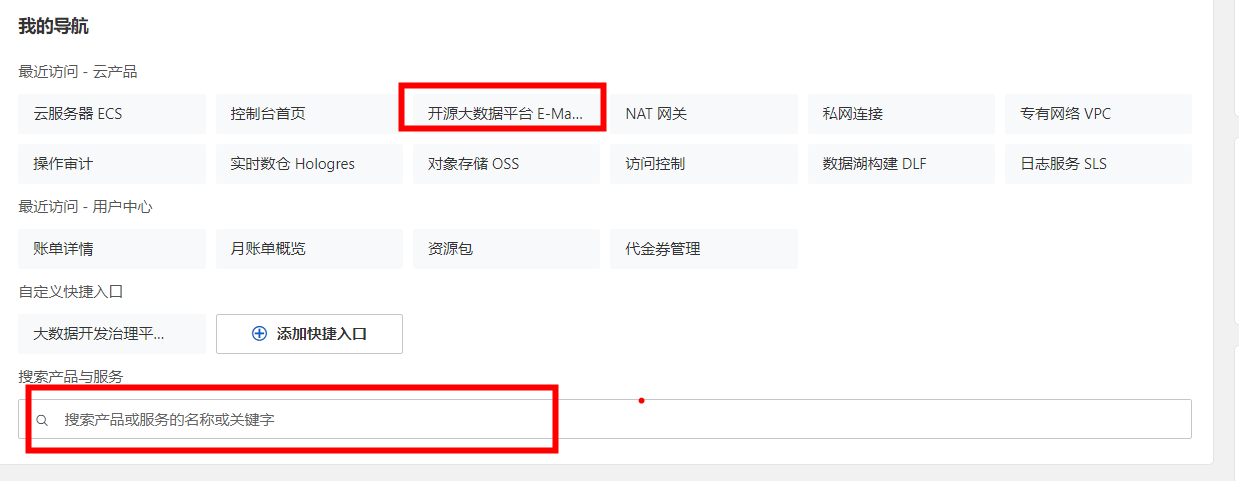
③ 进入至 E-MapReduce 首页,点击 EMR on ECS - 创建集群
-- 具体购买细节参考官方文档 https://help.aliyun.com/document_detail/176795.html#section-55q-jmm-3ts
④ 点击集群ID 可查看集群的基础信息、集群服务以及节点管理等模块
(2)登录
-- 详细登录集群方式可参考官方文档 https://help.aliyun.com/document_detail/169150.html
-- 本文以登录ECS实例操作
① 点击阿里云首页控制台 - 云服务器ECS
https://www.aliyun.com/product/ecs?spm=5176.19720258.J_3207526240.92.542b2c4aSz6c39
② 点击实例名称 - 远程连接 - Workbench远程连接
2、本地IDEA准备
(1)安装maven
-- 可参考文档 https://blog.csdn.net/l32273/article/details/123684435
(2)创建Scala项目
① 下载Scala插件
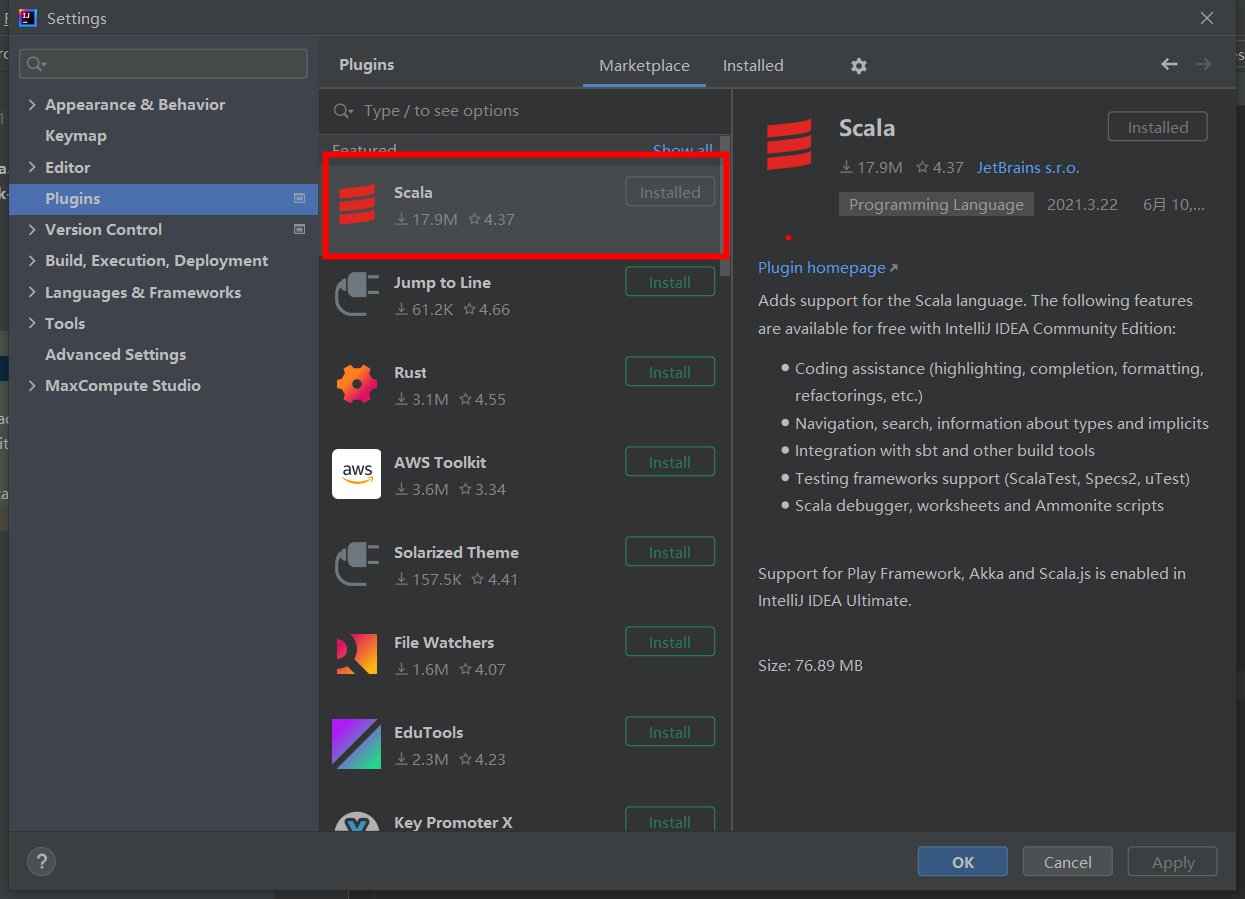
② 安装 Scala JDK
-- 建议下载 *.zip 文件
-- 配置 Scala 环境变量
-- 通过 Win + R 打开 cmd 测试是否出现 Scala版本
-- 可参考文档: https://blog.csdn.net/m0_59617823/article/details/124310663
③ 创建 Scala 项目
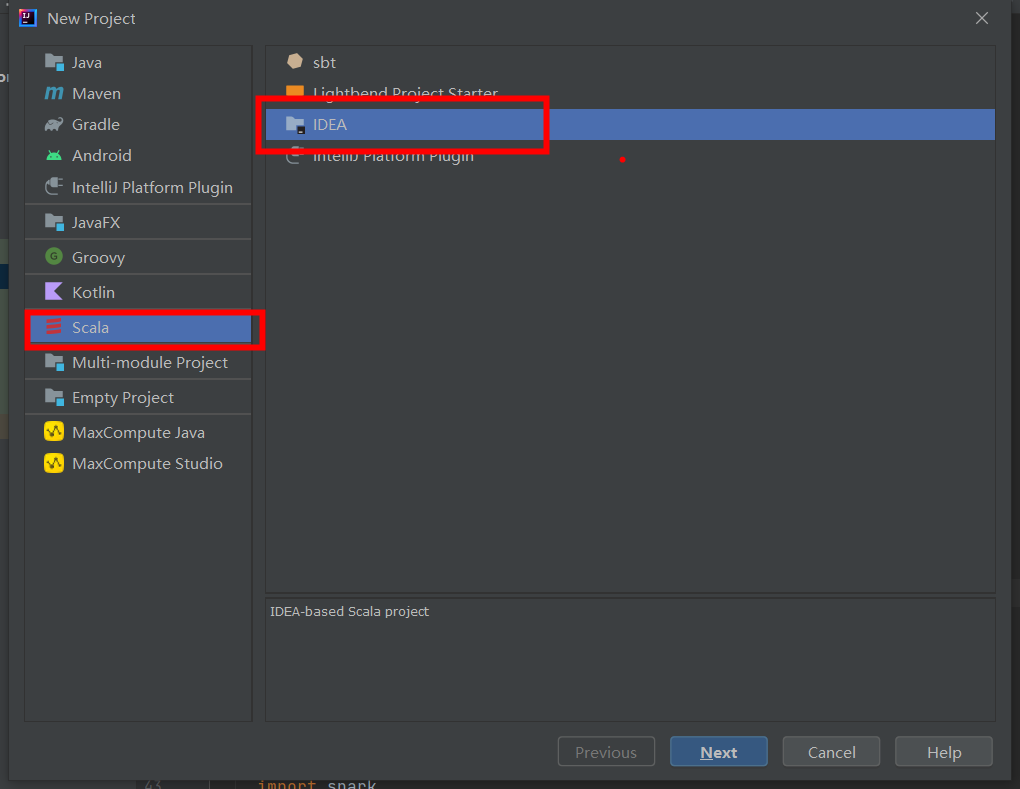
3、MaxCompute数据准备
(1)Project
-- MaxCompute 创建 project 可参考官方文档: https://help.aliyun.com/document_detail/27815.html
(2)AccessKey
-- 简称AK,包括AccessKey ID和AccessKey Secret,是访问阿里云API的密钥。在阿里云官网注册云账号后,可以在AccessKey管理页面生成该信息,用于标识用户,为访问MaxCompute、其他阿里云产品或连接第三方工具做签名验证。请妥善保管AccessKey Secret,必须保密,如果存在泄露风险,请及时禁用或更新AccessKey。
-- 查找 ak 可参考官方文档
https://ram.console.aliyun.com/manage/ak?spm=a2c4g.11186623.0.0.24704213IXakh3
(3)Endpoint
-- MaxCompute服务:连接地址为Endpoint,取值由地域及网络连接方式决定
-- 各地域 endpoint 可参考官方文档:https://help.aliyun.com/document_detail/34951.html
(4)table
-- MaxCompute 创建表可参考官方文档 https://help.aliyun.com/document_detail/73768.html
-- 本文需准备分区表和非分区表,供测试使用
三、代码测试
1、前提条件
(1)准备 MaxCompute 上的project、ak信息以及表数据
(2)准备 E-MapReduce集群
(3)终端连接 E-MapReduce节点(即 ECS 实例)
(4)本地 IDEA 需配置 Scala 环境变量、maven 环境变量 并下载 Scala 插件
2、代码示例
3、打包上传
(1)本地写好代码后,maven 打包
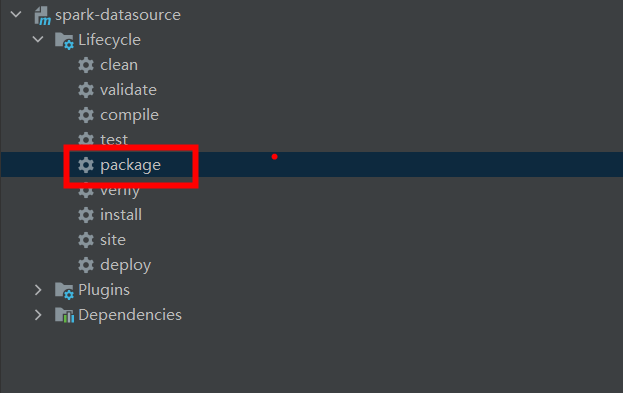
(2)本地编译jar包
① 进入project目录
cd ${project.dir}/spark-datasource-v3.1
② 执行mvn命令构建spark-datasource
mvn clean package jar:test-jar

③ 查看 target 目录下是否有 dependencies.jar 和 tests.jar
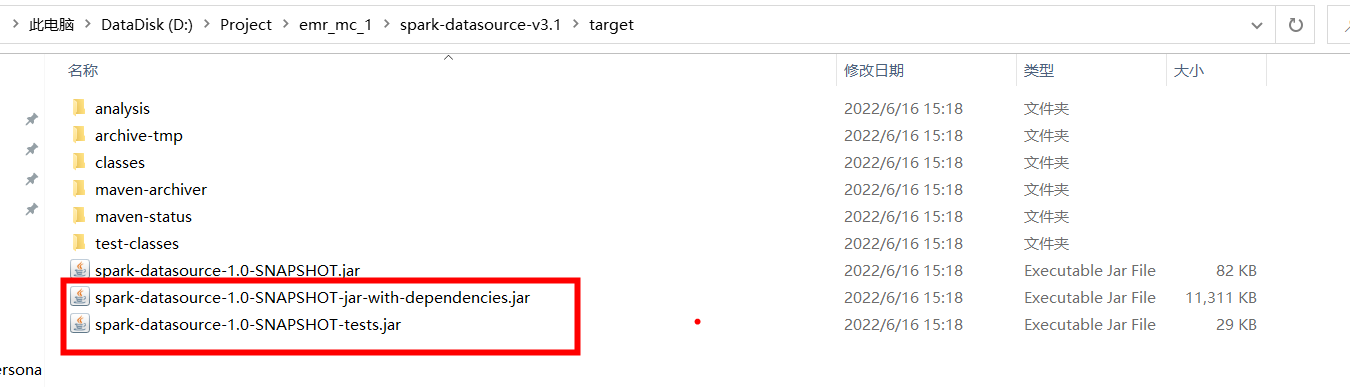
(3)打好的 jar 包上传至服务器
① scp 命令上传
scp [本地jar包路径] root@[ecs实例公网IP]:[服务器存放jar包路径]

② 服务器查看

③ 各节点之间上传 jar 包
scp -r [本服务器存放jar包路径] root@ecs实例私网IP:[接收的服务器存放jar包地址]

4、测试
(1)运行模式
① Local 模式:指定 master 参数为 local
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② yarn 模式:指定master 参数为 yarn、代码中 endpoint 选择以 -inc 结尾
代码:val ODPS_ENDPOINT = "http://service.cn-beijing.maxcompute.aliyun-inc.com/api" ./bin/spark-submit \
--master yarn \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
(2)读非分区表表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataReaderTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果

(2)读分区表测试
① 命令
-- 首先进入spark执行环境
cd /usr/lib/spark-current
-- 提交任务
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行界面

③ 执行结果

(3)写非分区表表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name}
② 执行界面

③ 执行结果
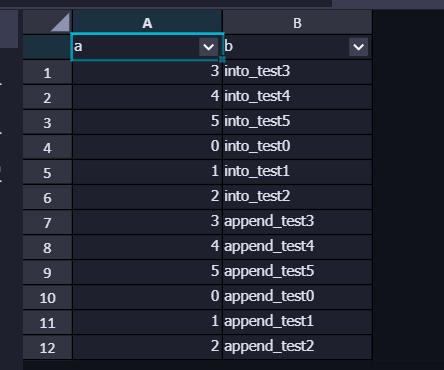
(4)写分区表测试
① 命令
./bin/spark-submit \
--master local \
--jars ${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-jar-with-dependencies.jar,${project.dir}/spark-datasource-v2.3/libs/cupid-table-api-1.1.5-SNAPSHOT.jar,${project.dir}/spark-datasource-v2.3/libs/table-api-tunnel-impl-1.1.5-SNAPSHOT.jar \
--class DataWriterTest \
${project.dir}/spark-datasource-v3.1/target/spark-datasource-1.0-SNAPSHOT-tests.jar \
${maxcompute-project-name} \
${aliyun-access-key-id} \
${aliyun-access-key-secret} \
${maxcompute-table-name} \
${partition-descripion}
② 执行过程

③ 执行结果

5、性能测试
-- 由于实验环境是 EMR 和 MC ,属于云上互联,如果 IDC 网络与云上相连取决于 tunnel 资源或者专线带宽
(1)大表读测试
-- size:4829258484 byte
-- partitions : 593个
-- 读取分区 20170422
-- 耗时: 0.850871 s

(2)大表写测试
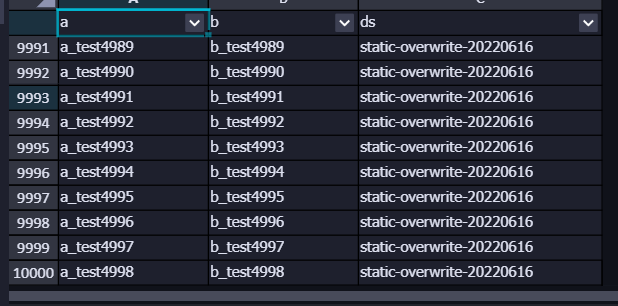
① 分区写入 万条 数据
-- 耗时:2.5s

-- 结果
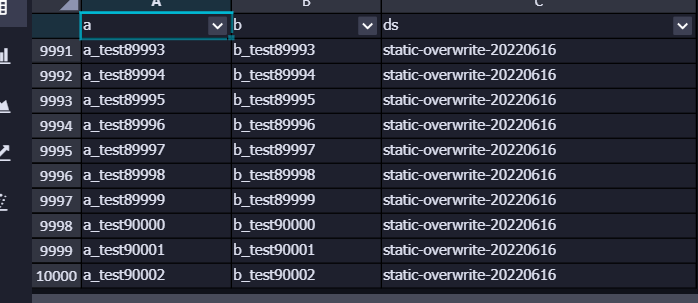
② 分区写入 十万条 数据
-- 耗时:8.44 s

-- 结果:
③ 分区写入 百万条 数据
-- 耗时:73.28 s

-- 结果

模拟IDC spark读写MaxCompute实践的更多相关文章
- Spark 读写hive 表
spark 读写hive表主要是通过sparkssSession 读表的时候,很简单,直接像写sql一样sparkSession.sql("select * from xx") 就 ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- 使用Spark读写CSV格式文件(转)
原文链接:使用Spark读写CSV格式文件 CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号.在本文中的CSV格 ...
- spark读写mysql
spark读写mysql除官网例子外还要指定驱动名称 travels.write .mode(SaveMode.Overwrite) .format("jdbc") .option ...
- Spark在MaxCompute的运行方式
一.Spark系统概述 左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架,如Spark ...
- Spark读写ES
本文主要介绍spark sql读写es.structured streaming写入es以及一些参数的配置 ES官方提供了对spark的支持,可以直接通过spark读写es,具体可以参考ES Spar ...
- [Big Data]从Hadoop到Spark的架构实践
摘要:本文则主要介绍TalkingData在大数据平台建设过程中,逐渐引入Spark,并且以Hadoop YARN和Spark为基础来构建移动大数据平台的过程. 当下,Spark已经在国内得到了广泛的 ...
- [转载] 从Hadoop到Spark的架构实践
转载自http://www.csdn.net/article/2015-06-08/2824889 http://www.zhihu.com/question/26568496 当下,Spark已经在 ...
- 我的Spark SQL单元测试实践
最近加入一个Spark项目,作为临时的开发人员协助进行开发工作.该项目中不存在测试的概念,开发人员按需求进行编码工作后,直接向生产系统部署,再由需求的提出者在生产系统检验程序运行结果的正确性.在这种原 ...
- 从Hadoop到Spark的架构实践
当下,Spark已经在国内得到了广泛的认可和支持:2014年,Spark Summit China在北京召开,场面火爆:同年,Spark Meetup在北京.上海.深圳和杭州四个城市举办,其中仅北京就 ...
随机推荐
- 华为sound x智能音箱初体验
外观颜值 在这个网红遍地的年代,好看的皮囊是那么的重要.很多东西,买与不买,只是你在电脑的橱上看它一眼.颜值对一个消费电子产品来说,在这个虚拟的互联网世界中是那么的重要.sound x的初次看来, ...
- KETTLE实战视频教程--免费白嫖(本贴持续更新)
KETTLE实战视频教程 欢迎关注笔者的公众号: java大师, 每日推送java.kettle运维等领域干货文章,关注即免费无套路附送 100G 海量学习.面试资源哟!!个人网站: http://w ...
- 封装TornadoFx常用控件库
github:https://github.com/Stars-One/common-controls 为TornadoFx的封装的常用控件与工具,基于Jfoenix,借鉴Kfoenix 前言 这个开 ...
- java线程池知识整理
参考,欢迎点击原文:https://www.jianshu.com/p/246021d04310(java多线程那点事) https://blog.csdn.net/fanrenxiang/artic ...
- Redis安装(Linux CentOS)
1. 环境介绍 主机系统:CentOS Redis版本:7.0.10 2. 安装过程 检查 GCC 版本 gcc -v redis 6.0 以上需要 gcc 5.3,升级 gcc.如果安装的redis ...
- 记录--JS原型链
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 引子 对于初学者学习原型链,还是有很大的困难.一方面是函数与对象分不太清楚:另一方面,不懂原型链的继承等.本人曾今也深受困惑,并且把疑惑的 ...
- 记录--vue脚手架
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 一.vue脚手架 1.简介 Vue CLI 是一个基于 Vue.js 进行快速开发的完整系统. 2.命令行操作步骤 npm install ...
- C# 优雅的处理TCP数据(心跳,超时,粘包断包,SSL加密 ,数据处理等)
Tcp是一个面向连接的流数据传输协议,用人话说就是传输是一个已经建立好连接的管道,数据都在管道里像流水一样流淌到对端.那么数据必然存在几个问题,比如数据如何持续的读取,数据包的边界等. Nagle's ...
- YOLACT++ : 实时实例分割,从29.8mAP/33.5fps到34.1mAP/33.5fps
YOLACT是首个实时实例分割算法,但是准确率较SOTA差得有点多,YOLACT++从主干网络.分支和anchor的3个角度出发对YOLACT进行优化,在保持实时性的前提下提升了5map,论文改进的角 ...
- kingbase ES 关于NULL及其相关函数
文章概要: 本文对主要就NULL值及其相关处理函数进行讨论,同时也介绍了ora_input_emptystr_isnull参数 一,关于NULL值 1,sql中的null值 null 值代表未知数据, ...