Python 探索性数据分析工具(PandasGUI,Pandas Profiling,Sweetviz,dtale)以及学术论文快速作图science.mplstyle
如果探索的数据集侧重数据展示,可以选PandasGUI;如果只是简单了解基本统计指标,可以选择Pandas Profiling和Sweetviz;如果需要做深度的数据探索,那就选择dtale。
1. 4款 Python 自动数据分析神器真香啊:
如此优雅,4款 Python 自动数据分析神器真香啊_我爱Python数据挖掘的博客-CSDN博客_python自动分析数据
1. PandasGUI:

PandasGUI操作界面
PandasGUI更侧重数据展示,提供了10多种图表,通过可视的方式配置。
但数据统计做的比较简单,没有提供缺失值、相关系数等指标,数据转换部分也只开放了一小部分接口。
2.Pandas Profiling

Pandas Profiling操作界面
每列的详情包括:缺失值统计、去重计数、最值、平均值等统计指标和取值分布的柱状图。
列之间的相关系数支持Spearman、Pearson、Kendall 和 Phik 4 种相关系数算法。
与 PandasGUI 相反,Pandas Profiling没有丰富的图表,但提供了非常多的统计指标以及相关系数。
3. Sweetviz
Sweetviz与Pandas Profiling类似,提供了每列详细的统计指标、取值分布、缺失值统计以及列之间的相关系数。


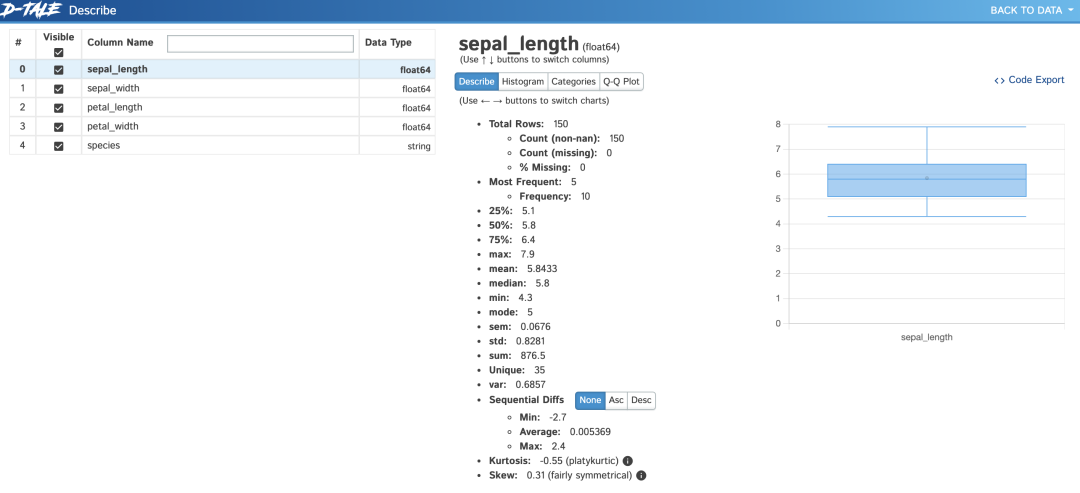
4. dtale
最后重磅介绍dtale,它不仅提供丰富图表展示数据,还提供了很多交互式的接口,对数据进行操作、转换。



1.2 Python小工具(2)-----数据分析(sweetviz库的使用):
Python小工具(2)-----数据分析(sweetviz库的使用)_飞在天空中的狗的博客-CSDN博客_python sweetviz
1.3 sweetviz包:快速可视化和数据集EDA
sweetviz包:快速可视化和数据集EDA_Smilecoc的博客-CSDN博客_sweetviz
1.4 【DTale】数据分析强大工具DTale的使用
【DTale】数据分析强大工具DTale的使用_Koma_zhe的博客-CSDN博客_dtale教程
1.5 用Python的dtale库进行数据探索
用Python的dtale库进行数据探索_菜鸟学Python数据分析的博客-CSDN博客
2. 学术论文快速作图(不同期刊格式图表):
Python小工具(3)----- 学术论文快速作图(不同期刊格式图表)_飞在天空中的狗的博客-CSDN博客


3. 多个文件多数据批量读取:
多个文件多数据批量读取_飞在天空中的狗的博客-CSDN博客_批量从多个文件中提取数据
import numpy as np
import os
# 加载数据路径
x_path = r'xxxx\BP_input_ai_data\\'
y_path = r'xxxx\BP_input_Y_data\\'
def read(x_path,y_path):
x_files = os.listdir(x_path)
y_files = os.listdir(y_path)
file_num = len(x_files) # 文件夹下文件个数
print('======= 共计%s个数据 ======' % file_num)
x_files.sort(key=lambda x: int(x[:-4])) #倒着数第四位'.'为分界线,按照‘.’左边的数字从小到大排序 1.txt 2.txt
y_files.sort(key=lambda y: int(y[:-4]))
# 读取文件夹中每个数据
for i in range(file_num): # 这里循环 读每个文件下的所有数据
x_name = x_path + '\\' + x_files[i]
y_name = y_path + '\\' + y_files[i]
# print('====== %s读取数据... ======' % x_files[i])
x_data = np.loadtxt(x_name) # 读取数据
y_data = np.loadtxt(y_name)
4.批量修改文件夹中文件后缀名:
批量修改文件夹中文件后缀名_飞在天空中的狗的博客-CSDN博客_批量修改后缀名
待修改数据 1.doc 2.doc
目标格式: 1.txt 2.txt
在此文件夹新建一个记事本,输入代码 ren *.doc *.txt,保存,然后把这个记事本的后缀改为bat,双击运行就行
(无论多少的文件,运行这个bat文件都能同时修改后缀~)
Python 探索性数据分析工具(PandasGUI,Pandas Profiling,Sweetviz,dtale)以及学术论文快速作图science.mplstyle的更多相关文章
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- 关于Python的数据分析工具
Python - 核心编程环境NumPy/SciPy - 用于快速.高效的数组和矩阵运算IPython - 用于Python的可视化交互开发matplotlib - 用于数据的图形可视化pandas ...
- 利用Python进行数据分析:【Pandas】(Series+DataFrame)
一.pandas简单介绍 1.pandas是一个强大的Python数据分析的工具包.2.pandas是基于NumPy构建的.3.pandas的主要功能 --具备对其功能的数据结构DataFrame.S ...
- python Pandas Profiling 一行代码EDA 探索性数据分析
文章大纲 1. 探索性数据分析 代码样例 效果 解决pandas profile 中文显示的问题 1. 探索性数据分析 数据的筛选.重组.结构化.预处理等都属于探索性数据分析的范畴,探索性数据分析是帮 ...
- python 数据分析工具之 numpy pandas matplotlib
作为一个网络技术人员,机器学习是一种很有必要学习的技术,在这个数据爆炸的时代更是如此. python做数据分析,最常用以下几个库 numpy pandas matplotlib 一.Numpy库 为了 ...
- python数据分析工具安装集合
用python做数据分析离不开几个好的轮子(或称为科学棧/第三方包等),比如matplotlib,numpy, scipy, pandas, scikit-learn, gensim等,这些包的功能强 ...
- 快速学习 Python 数据分析包 之 pandas
最近在看时间序列分析的一些东西,中间普遍用到一个叫pandas的包,因此单独拿出时间来进行学习. 参见 pandas 官方文档 http://pandas.pydata.org/pandas-docs ...
- 利用Python进行数据分析-Pandas(第四部分-数据清洗和准备)
在数据分析和建模的过程中,相当多的时间要用在数据准备上:加载.清理.转换以及重塑上.这些工作会占到分析时间的80%或更多.有时,存储在文件和数据库中的数据的格式不适合某个特定的任务.研究者都选择使用编 ...
- Python数据处理常用工具(pandas)
目录 数据清洗的常用工具--Pandas 数据清洗的常用工具 Pandas常用数据结构series和方法 Pandas常用数据结构dataframe和方法 常用方法 数据清洗的常用工具--Pandas ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
随机推荐
- VS Code 2022路线图:大量Spring Boot优化提上日程
1月20日,一名微软开发者发布了一篇标题为<Java on Visual Studio Code Update>的文章. 文中介绍了VS Code 2021年的亮点,同时还透露了VS Co ...
- Hottest 30 of codeforce
1. 4A.Watermelon 题目链接:https // s.com/problemset/problem/4/A 题意:两人分瓜,但每一部分都得是偶数 分析:直接 对2取余,且 w != 2 # ...
- Codeforces Round #733 (Div. 1 + Div. 2)
比赛链接:Here 1530A. Binary Decimal 现在规定一种只由0和1组成的数字,我们称这种数字为二进制数字,例如10,1010111,给定一个数n,求该数字最少由多少个二进制数字组成 ...
- 企业如何利用 Serverless 快速扩展业务系统?
2022 年 9 月 24 日,阿里云用户组(AUG)第 12 期活动在厦门举办.活动现场,阿里云高级技术专家史明伟(花名:世如)向参会企业代表分享了<未来已来--从技术升级到降本提效>. ...
- Ribbon默认负载均衡规则替换为NacosRule
近期博主在参与一个 Spring Cloud 搭建,版本为 Hoxton.SR12,服务注册发现组件为 Nacos 的老项目时,发现项目负载均衡组件 Ribbon 的负载均衡规则在某些场景下不够完美, ...
- C# 排序算法5:归并排序
归并排序,是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个有序的子序列,再把有序的子序列合并为整体有序序列.该算法是采用分治法. 原理: 1.申请空间,使其大小为两个已经排序 ...
- C# 加解密
1. Md5 /// <summary> /// 不可逆加密 /// 1 防止被篡改 /// 2 防止明文存储 /// 3 防止抵赖,数字签名 /// </summary> ...
- c#.net 6 实现简单爬虫几行代码实现百度搜索
使用selenium封装的简单使用工具包 Gitee:SeleniumUtil: Selenium简化工具包,包含三个主流浏览器的一些基本操作 (gitee.com) 第一步安装爬虫工具: 在程序包管 ...
- 基于python的药店药品信息管理系统-毕业设计-课程设计
基于python+django+vue.js开发的药店信息管理系统 功能介绍 平台采用B/S结构,后端采用主流的Python语言进行开发,前端采用主流的Vue.js进行开发. 功能包括:药品管理.分类 ...
- Pycharm配置git
原文链接:https://www.jianshu.com/p/ae92970d2062 1.下载Gitee插件 同样在设置页面,选中 Plugins,并搜索 Gitee安装. 安装后,重启一下Pych ...