Attention Model详解
要是关注深度学习在自然语言处理方面的研究进展,我相信你一定听说过Attention Model(后文有时会简称AM模型)这个词。AM模型应该说是过去一年来NLP领域中的重要进展之一,在很多场景被证明有效。听起来AM很高大上,其实它的基本思想是相当直观简洁的。
AM 引言:
引用网上通俗的解释,首先,请您睁开眼并确认自己处于意识清醒状态;第二步,请找到本文最近出现的一个“Attention Model”字眼(就是“字眼”前面的两个英文单词,…)并盯住看三秒钟。好,假设此刻时间停止,在这三秒钟你眼中和脑中看到的是什么?对了,就是“Attention Model”这两个词,但是你应该意识到,其实你眼中是有除了这两个单词外的整个一副画面的,但是在你盯着看的这三秒钟,时间静止,万物无息,仿佛这个世界只有我和你…..对不起,串景了,仿佛这个世界只有“Attention Model”这两个单词。这是什么?这就是人脑的注意力模型,就是说你看到了整幅画面,但在特定的时刻t,你的意识和注意力的焦点是集中在画面中的某一个部分上,其它部分虽然还在你的眼中,但是你分配给它们的注意力资源是很少的。其实,只要你睁着眼,注意力模型就无时不刻在你身上发挥作用,比如你过马路,其实你的注意力会被更多地分配给红绿灯和来往的车辆上,虽然此时你看到了整个世界;比如你很精心地偶遇到了你心仪的异性,此刻你的注意力会更多的分配在此时神光四射的异性身上,虽然此刻你看到了整个世界,但是它们对你来说跟不存在是一样的…..这就是人脑的注意力模型,说到底是一种资源分配模型,在某个特定时刻,你的注意力总是集中在画面中的某个焦点部分,而对其它部分视而不见。其实吧,深度学习里面的注意力模型工作机制啊,它跟你看见心动异性时荷尔蒙驱动的注意力分配机制是一样一样的。
Encoder-Decoder框架:
本文只谈谈文本处理领域的AM模型,在图片处理或者(图片-图片标题)生成等任务中也有很多场景会应用AM模型,但是我们此处只谈文本领域的AM模型,其实图片领域AM的机制也是相同的。
要提文本处理领域的AM模型,就不得不先谈Encoder-Decoder框架,因为目前绝大多数文献中出现的AM模型是附着在Encoder-Decoder框架下的,当然,其实AM模型可以看作一种通用的思想,本身并不依赖于Encoder-Decoder模型,这点需要注意。
Encoder-Decoder框架可以看作是一种文本处理领域的研究模式,应用场景异常广泛,本身就值得非常细致地谈一下,但是因为本文的注意力焦点在AM模型,所以此处我们就只谈一些不得不谈的内容,详细的Encoder-Decoder模型以后考虑专文介绍。下图是文本处理领域里常用的Encoder-Decoder框架最抽象的一种表示:
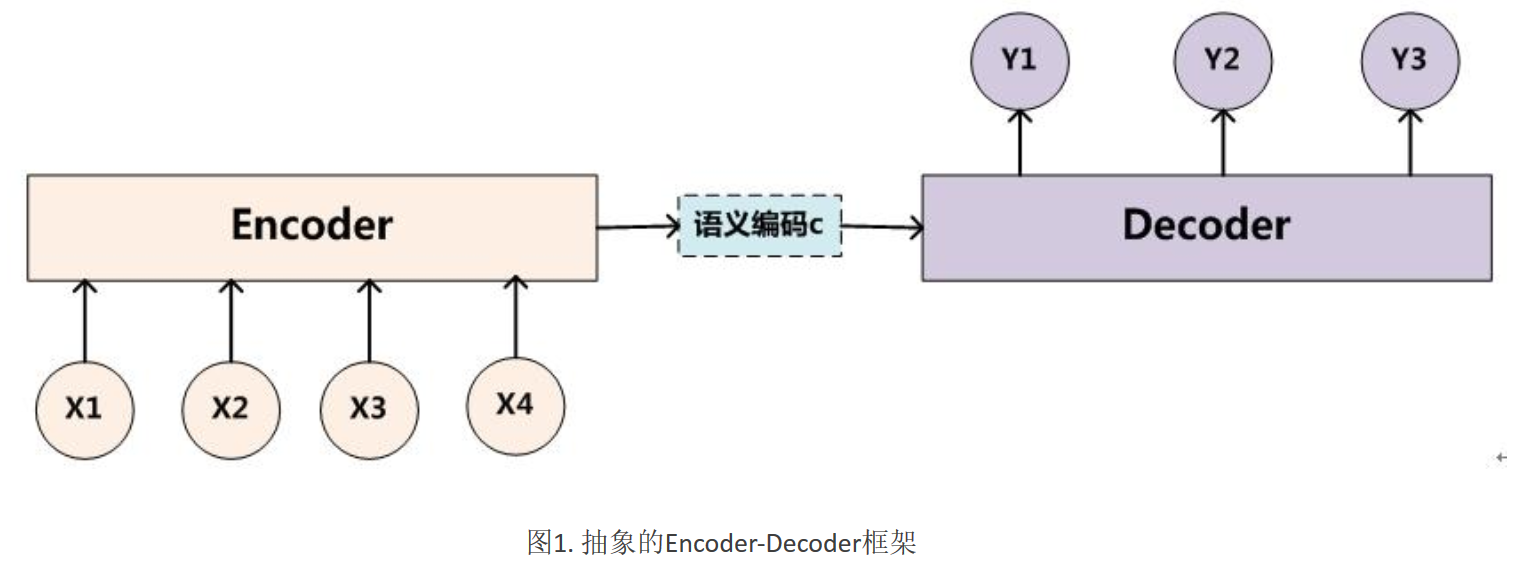
Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<X,Y>,我们的目标是给定输入句子X,期待通过 Encoder-Decoder框架来生成目标句子Y。X和Y可以是同一种语言,也可以是两种不同的语言。而X和Y分别由各自的单词序列构成:
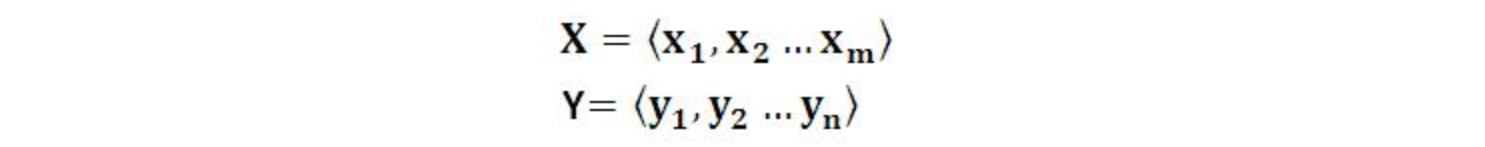
Encoder顾名思义就是对输入句子X进行编码,将输入句子通过非线性变换转化为中间语义表示C:
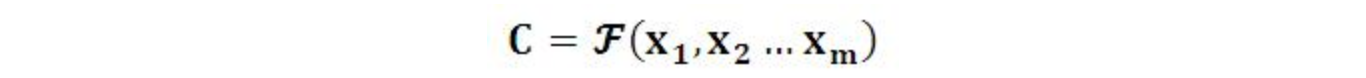
对于解码器Decoder来说,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息y1,y2….yi-1来生成i时刻要生成的单词yi:
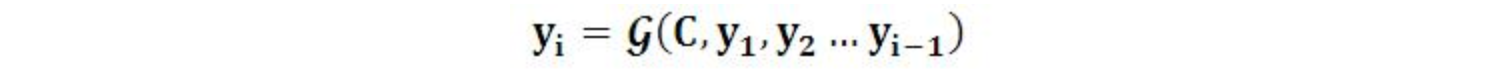
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
Encoder-Decoder是个非常通用的计算框架,至于Encoder和Decoder具体使用什么模型都是由研究者自己定的,常见的比如CNN/RNN/BiRNN/GRU/LSTM/Deep LSTM等,这里的变化组合非常多,而很可能一种新的组合就能攒篇论文,所以有时候科研里的创新就是这么简单。比如我用CNN作为Encoder,用RNN作为Decoder,你用BiRNN做为Encoder,用深层LSTM作为Decoder,那么就是一个创新。
Encoder-Decoder是个创新游戏大杀器,一方面如上所述,可以搞各种不同的模型组合,另外一方面它的应用场景多得不得了,比如对于机器翻译来说,<X,Y>就是对应不同语言的句子,比如X是英语句子,Y是对应的中文句子翻译。再比如对于文本摘要来说,X就是一篇文章,Y就是对应的摘要;再比如对于对话机器人来说,X就是某人的一句话,Y就是对话机器人的应答。
Attention Model:
图1中展示的Encoder-Decoder模型是没有体现出“注意力模型”的,所以可以把它看作是注意力不集中的分心模型。为什么说它注意力不集中呢?请观察下目标句子Y中每个单词的生成过程如下:
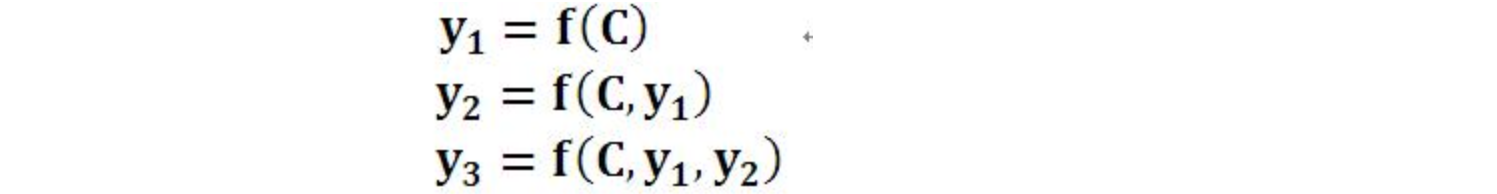
其中f是decoder的非线性变换函数。从这里可以看出,在生成目标句子的单词时,不论生成哪个单词,是y1,y2也好,还是y3也好,他们使用的句子X的语义编码C都是一样的,没有任何区别。而语义编码C是由句子X的每个单词经过Encoder 编码产生的,
这意味着不论是生成哪个单词,y1,y2还是y3,其实句子X中任意单词对生成某个目标单词yi来说影响力都是相同的,没有任何区别(其实如果Encoder是RNN的话,理论上越是后输入的单词影响越大,并非等权的,估计这也是为何Google提出Sequence to Sequence模型时发现把输入句子逆序输入做翻译效果会更好的小Trick的原因)。
这就是为何说这个模型没有体现出注意力的缘由。这类似于你看到眼前的画面,但是没有注意焦点一样。如果拿机器翻译来解释这个分心模型的Encoder-Decoder框架更好理解,比如输入的是英文句子:Tom chase Jerry,Encoder-Decoder框架逐步生成中文单词:“汤姆”,“追逐”,“杰瑞”。在翻译“杰瑞”这个中文单词的时候,分心模型里面的每个英文单词对于翻译目标单词“杰瑞”贡献是相同的,很明显这里不太合理,显然“Jerry”对于翻译成“杰瑞”更重要,但是分心模型是无法体现这一点的,这就是为何说它没有引入注意力的原因。没有引入注意力的模型在输入句子比较短的时候估计问题不大,但是如果输入句子比较长,此时所有语义完全通过一个中间语义向量来表示,单词自身的信息已经消失,可想而知会丢失很多细节信息,这也是为何要引入注意力模型的重要原因。
上面的例子中,如果引入AM模型的话,应该在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:

每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。增加了AM模型的Encoder-Decoder框架理解起来如图2所示。

即生成目标句子单词的过程成了下面的形式:
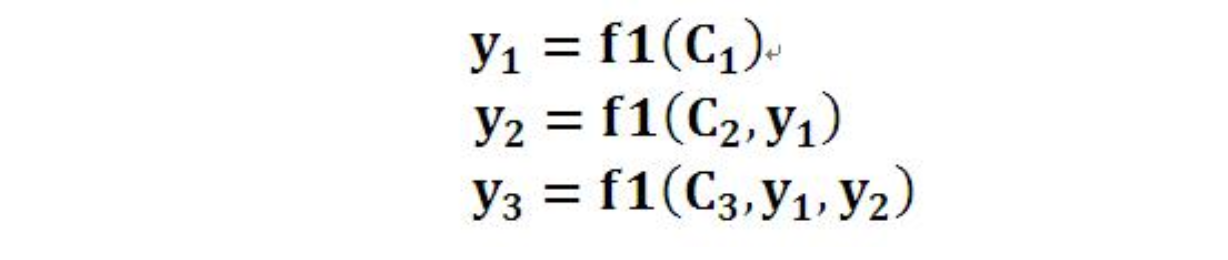
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入xi后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,也就是常常在论文里看到的下列公式:

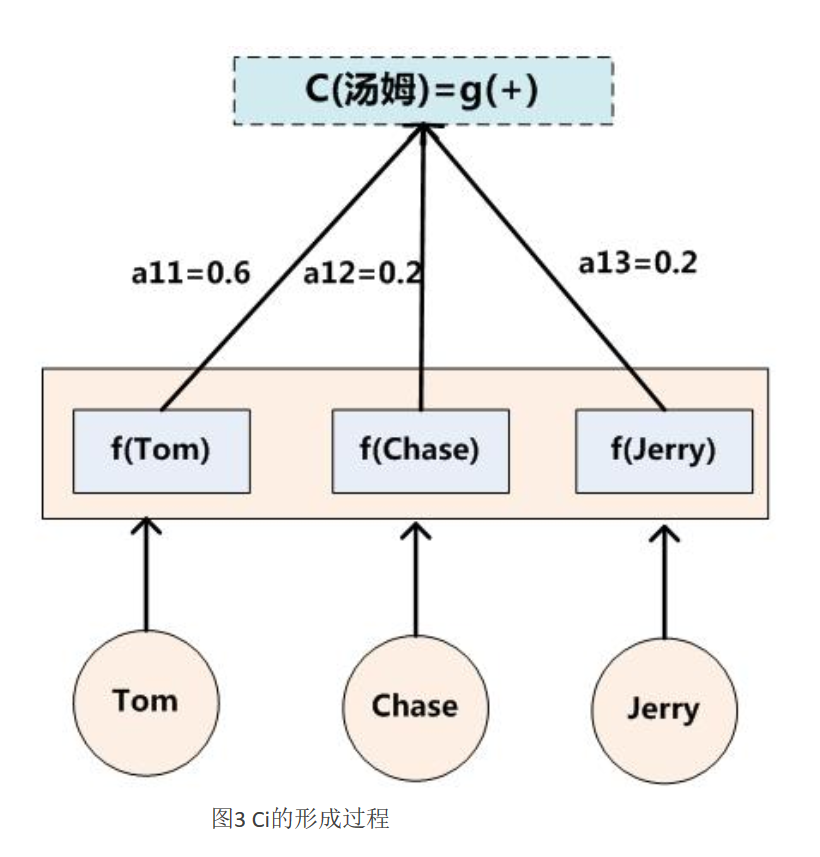
假设Ci中那个i就是上面的“汤姆”,那么Tx就是3,代表输入句子的长度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),对应的注意力模型权值分别是0.6,0.2,0.2,所以g函数就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似下图:
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,你怎么知道AM模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的概率分布:
(Tom,0.6)(Chase,0.2)(Jerry,0.2)是如何得到的呢?为了便于说明,我们假设对图1的非AM模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图1的图转换为下图:
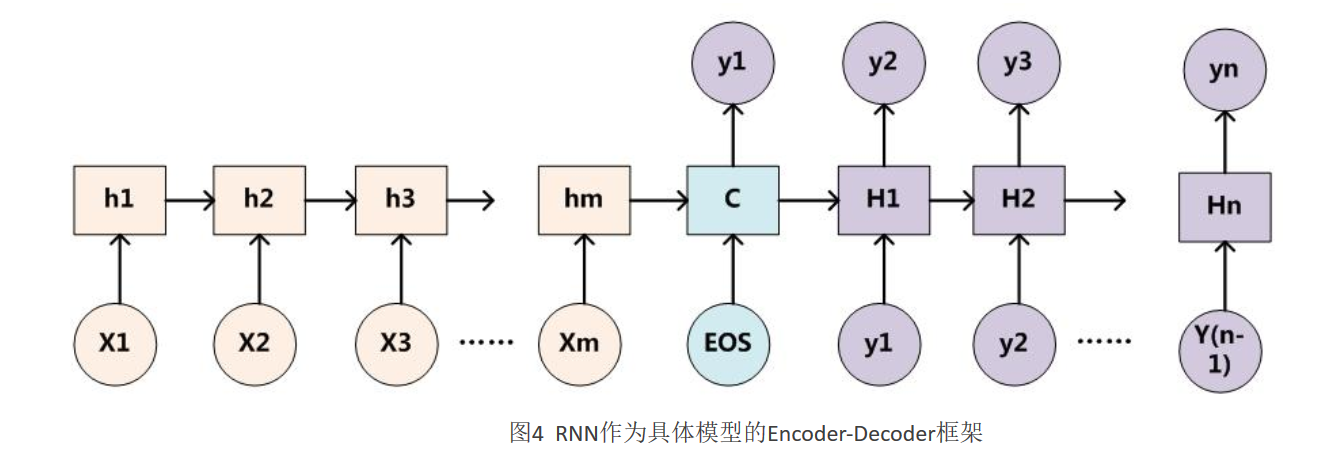
那么用下图可以较为便捷地说明注意力分配概率分布值的通用计算过程:

对于采用RNN的Decoder来说,如果要生成yi单词,在时刻i,我们是可以知道在生成Yi之前的隐层节点i时刻的输出值Hi的,而我们的目的是要计算生成Yi时的输入句子单词“Tom”、“Chase”、“Jerry”对Yi来说的注意力分配概率分布,那么可以用i时刻的隐层节点状态Hi去一一和输入句子中每个单词对应的RNN隐层节点状态hj进行对比,即通过函数F(hj,Hi)来获得目标单词Yi和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,比对函数F,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。图5显示的是当输出单词为“汤姆”时刻对应的输入句子单词的对齐概率。绝大多数AM模型都是采取上述的计算框架来计算注意力分配概率分布信息,区别只是在F的定义上可能有所不同。
上述内容就是论文里面常常提到的Soft Attention Model的基本思想,你能在文献里面看到的大多数AM模型基本就是这个模型,区别很可能只是把这个模型用来解决不同的应用问题。那么怎么理解AM模型的物理含义呢?一般文献里会把AM模型看作是单词对齐模型,这是非常有道理的。目标句子生成的每个单词对应输入句子单词的概率分布可以理解为输入句子单词和这个目标生成单词的对齐概率,这在机器翻译语境下是非常直观的:传统的统计机器翻译一般在做的过程中会专门有一个短语对齐的步骤,而注意力模型其实起的是相同的作用。在其他应用里面把AM模型理解成输入句子和目标句子单词之间的对齐概率也是很顺畅的想法。
当然,我觉得从概念上理解的话,把AM模型理解成影响力模型也是合理的,就是说生成目标单词的时候,输入句子每个单词对于生成这个单词有多大的影响程度。这种想法也是比较好理解AM模型物理意义的一种思维方式。
图6是论文“A Neural Attention Model for Sentence Summarization”中,Rush用AM模型来做生成式摘要给出的一个AM的一个非常直观的例子。
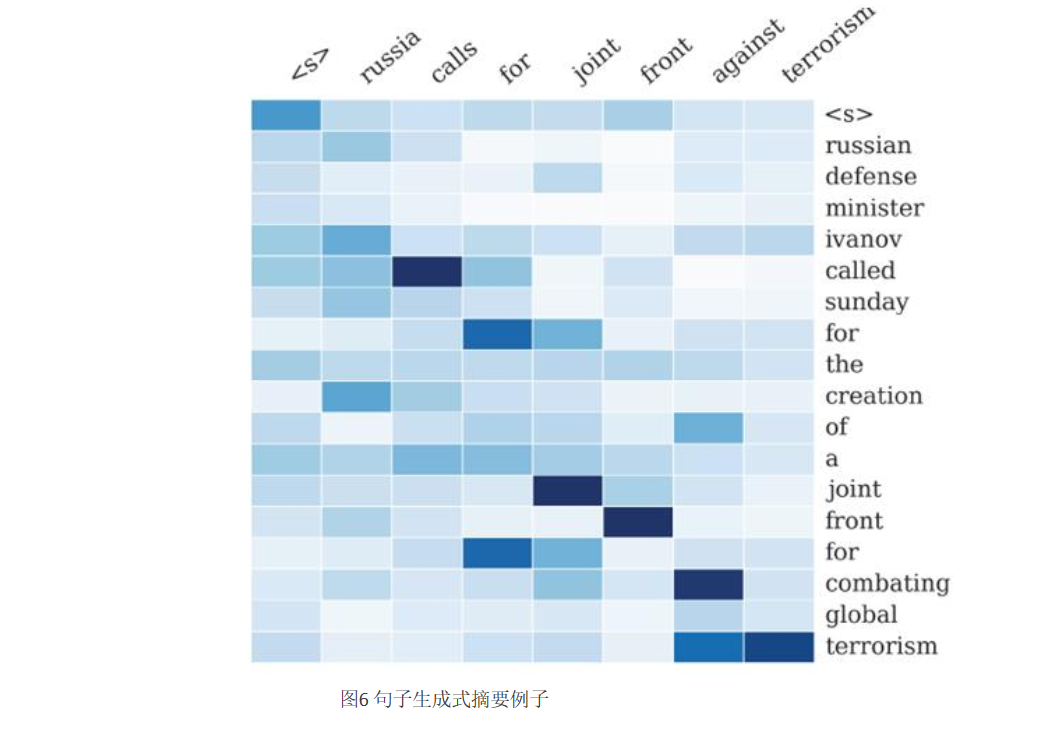
这个例子中,Encoder-Decoder框架的输入句子是:“russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism”。对应图中纵坐标的句子。系统生成的摘要句子是:“russia calls for joint front against terrorism”,对应图中横坐标的句子。可以看出模型已经把句子主体部分正确地抽出来了。矩阵中每一列代表生成的目标单词对应输入句子每个单词的AM分配概率,颜色越深代表分配到的概率越大。这个例子对于直观理解AM是很有帮助作用的。
Attention Model详解的更多相关文章
- Django之model详解
Django中的页面管理后台 Djano中自带admin后台管理模块,可以通过web页面去管理,有点想php-admin,使用步骤: 在项目中models.py 中创建数据库表 class useri ...
- Model详解
一.数据库操作 Model操作: 创建数据库表结构(建表) 操作数据库表(增删改查) 做一部分的验证(验证) a.建表 1.表字段 AutoField(Field) - int自增列,必须填入参数 p ...
- Python之Django的Model详解
一.创建数据库 创建数据库 进入数据库: mysql -uroot -p 创建数据库: CREATE DATABASE test1 CHARSET=utf8; 连接数据库 虚拟环境中安装数据库模块:p ...
- Attention is all you need 论文详解(转)
一.背景 自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基于R ...
- python 中model.py详解
model详解 Django中遵循 Code Frist 的原则,即:根据代码中定义的类来自动生成数据库表. 创建表 基本结构 from django.db import models # Creat ...
- <转>ASP.NET学习笔记之MVC 3 数据验证 Model Validation 详解
MVC 3 数据验证 Model Validation 详解 再附加一些比较好的验证详解:(以下均为引用) 1.asp.net mvc3 的数据验证(一) - zhangkai2237 - 博客园 ...
- Django model 字段详解
字段类型选择: AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 ...
- Django model 中的 class Meta 详解
Django model 中的 class Meta 详解 通过一个内嵌类 "class Meta" 给你的 model 定义元数据, 类似下面这样: class Foo(mode ...
- 反射实现Model修改前后的内容对比 【API调用】腾讯云短信 Windows操作系统下Redis服务安装图文详解 Redis入门学习
反射实现Model修改前后的内容对比 在开发过程中,我们会遇到这样一个问题,编辑了一个对象之后,我们想要把这个对象修改了哪些内容保存下来,以便将来查看和追责. 首先我们要创建一个User类 1 p ...
随机推荐
- 【剑指offer】面试题 20. 表示数值的字符串
面试题 20. 表示数值的字符串
- 11 Sping框架--AOP的相关概念及其应用
1.AOP的概念 AOP(Aspect Oriented Programming 面向切面编程),通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP的延续,是软件开发中的一 ...
- java笔记2—函数
函数: 1.什么是函数? 函数是定义在类中具有特定功能的一段独立小程序. 函数也称方法. 2.函数的格式: [ 修饰符 ] 返回值类型 函数名(参数类型 形式参数) ...
- free(分层图最短路)(2019牛客暑期多校训练营(第四场))
示例: 输入: 3 2 1 3 11 2 12 3 2 输出:1 题意:求s,t最短路,可将k条边权值置零. 题解:分层图最短路原题 #include<bits/stdc++.h> usi ...
- caurina缓动类
一.简单的缓动 一个实例名为box的正方体,开始alpha为0.5,在两秒内移动到x:300 y:100的位置,alpha变为1.import caurina.transitions.Tweener; ...
- 4: ES内执行Groovy脚本,做文档部分更新、执行判断改变操作类型
ES有内置的Groovy脚本执行内核,可以在命令的Json内嵌入Groovy脚本语句 前提数据:
- asBroadcastStream
StreamSubscription sc = StreamSubscription(); Stream s = Stream(); sc.addStream(s); var bs = sc.stre ...
- 第三章:JavaScript选择元素
我们使用jQuery时,很常用的套路是“两步”第一步:选取元素第二步:对选中的元素执行需要的操作这一章我们重点研究第一步,如何使用jQuery选取元素以及对选取的结果进行“各种筛选”以满足我们的需求. ...
- 【layui】layer.photos 相册层动态生成Img 中出现的问题的解决方案
layui版本:2.5.5 参照文档:https://www.jianshu.com/p/c594811fa882 他的3.8的解决方案有一些调整因为发现他的解决方式有些繁琐而最新的2.5.5版本中有 ...
- rabbitmq实战:一、天降奇兵
缘由,最近换了工作,而新的项目中使用了celery+rabbitmq来实现一个分布式任务队列系统,为了能够维护好这套系统,只能来学习一下这两个组件,顺便把学习笔记记录下来,留作以后回顾,当然如果碰巧能 ...