Python数据分析--------numpy数据打乱
一、shuffle函数:
import numpy.random
def shuffleData(data):
np.random.shufflr(data)
cols=data.shape[1]
X=data[:,0:cols-1]
Y=data[:,cols-1:]
return X,Y
二、np.random.permutation()函数
这个函数的使用来随机排列一个数组的,
一维数组:

对多维数组来说,是多维随机打乱而不是1维,例如:

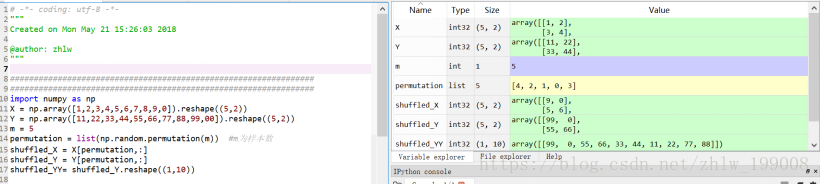
如果要利用次函数对输入数据X、Y进行随机排序,且要求随机排序后的X Y中的值保持原来的对应关系,可以这样处理:
permutation = list(np.random.permutation(m)) #m为样本数
shuffled_X = X[permutation]
shuffled_Y = Y[permutation].reshape((1,m))
图4中的代码是针对一维数组来说的,(图片中右侧为运行结果):

图5中的代码是针对二维数组来说的:
https://blog.csdn.net/zhlw_199008/article/details/80569167
三、sameple函数
sample()参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3
以下代码实现了从“CRASHSEV”中选出1,2,3,4的属性,乱序,然后取出前10000行,按行链接成新的数据,重建索引:
def unbanlance(un_data):
data1 = un_data.loc[(data["CRASHSEV"] == 1)].sample(frac=1).iloc[:10000, :]
data2 = un_data.loc[(data["CRASHSEV"] == 2)].sample(frac=1).iloc[:10000, :]
data3 = un_data.loc[(data["CRASHSEV"] == 3)].sample(frac=1).iloc[:10000, :]
data4 = un_data.loc[(data["CRASHSEV"] == 4)].sample(frac=1).iloc[:10000, :]
ba_data = pd.concat([data1,data2,data3,data4], axis=0).sample(frac=1).reset_index(drop=True) #0是按行链接
return ba_data
Python数据分析--------numpy数据打乱的更多相关文章
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- python数据分析笔记——数据加载与整理]
[ python数据分析笔记——数据加载与整理] https://mp.weixin.qq.com/s?__biz=MjM5MDM3Nzg0NA==&mid=2651588899&id ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
- python 利用numpy同时打乱列表的顺序,同时打乱数据和标签的顺序
可用于网络训练打乱训练数据个标签,不改变对应关系 方法一: np.random.shuffle (无返回值,直接打乱原列表) state = np.random.get_state() np.rand ...
- Python数据分析--Numpy常用函数介绍(4)--Numpy中的线性关系和数据修剪压缩
摘要:总结股票均线计算原理--线性关系,也是以后大数据处理的基础之一,NumPy的 linalg 包是专门用于线性代数计算的.作一个假设,就是一个价格可以根据N个之前的价格利用线性模型计算得出. 前一 ...
- python 数据分析----numpy
NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进行快速运算的数学函数 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
随机推荐
- [\S\s]+ 可以匹配多行html,最常用的还是.*?
[\S\s]+ 可以匹配多行html,最常用的还是.*?
- ThinkPHP模版引擎之变量输出具体解释
ThinkPHP模版引擎之变量输出具体解释 使用ThinkPHP开发有一定时间了,今日对ThinkPHP的模板引擎变量解析深入了解了一下.做出一些总结,分享给大家供大家參考. 详细分析例如以下: 我们 ...
- spring学习笔记(22)声明式事务配置,readOnly无效写无异常
在上一节内容中.我们使用了编程式方法来配置事务,这种优点是我们对每一个方法的控制性非常强.比方我须要用到什么事务,在什么位置假设出现异常须要回滚等.能够进行非常细粒度的配置.但在实际开发中.我们可能并 ...
- HDU-5310-Souvenir(C++ && 简单数学题)
Souvenir Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others) Total ...
- 报错configure:error: no acceptable C compiler found in $PATH。。
报错configure:error: no acceptable C compiler found in $PATH.. 查看日志: 出错原因:新安装的linux系统,没有gcc库 解决方案:使用yu ...
- Referenced file contains errors (http://www.springframework.org/schema/beans/spring-beans-3.0.xsd)
问题: java项目在Eclipse中xml有小红叉 Problems:Referenced file contains errors (http://www.springframework.org/ ...
- Linux学习之设置联网,关闭防火墙,关闭selinux
桥接模式,给一台物理机,有自己独立的IP. boot分区,引导分区,系统启动,内核文件. swap分区,内存扩展分区.1.5或2倍.内存不够的时候,会写入其中.正常给8G或者16G就够了.不需要非要1 ...
- 【POJ 2286】 The Rotation Game
[题目链接] http://poj.org/problem?id=2286 [算法] IDA* [代码] #include <algorithm> #include <bitset& ...
- 通过ip获取地址
<?php /** * IP 地理位置查询类 * * @author 马秉尧 * @version 1.5 * @copyright 2005 CoolCode.CN */ class IpLo ...
- BZOJ-3732 Network 图论 最小生成树 倍增
题面 题意:给你N个点,M条边的无向图 (N<=15000,M<=30000)第j条边的长度为 dj (1<=dj<=1e9),然后K个询问 (1<=K<=2000 ...