0809MySQL实战系列:大字段如何优化|数据存储结构
转自https://yq.aliyun.com/articles/59256?spm=5176.100239.blogcont59257.9.5MLR2d
摘要: 背景 线上发现一张表,1亿的数据量,物理大小尽然惊人的大,1.2T 最终发现,原来有很多字段,10个varchar,1个text 这么大的表,会给运维带来很大的痛苦:DDL咋办?恢复咋办?备份咋办? 基本知识:InnoDB Storage Architecture for InnoDB On
背景
线上发现一张表,1亿的数据量,物理大小尽然惊人的大,1.2T
最终发现,原来有很多字段,10个varchar,1个text
这么大的表,会给运维带来很大的痛苦:DDL咋办?恢复咋办?备份咋办?
基本知识:InnoDB Storage Architecture for InnoDB On Disk Format
蓝图: database --> tablespaces --> pages --> rows --> columns
InnoDB 物理结构存储结构
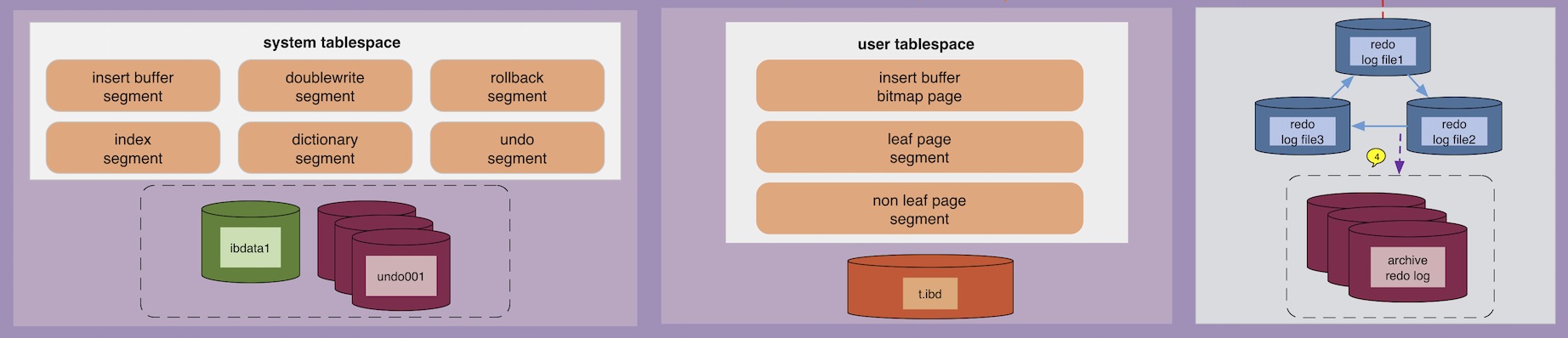
InnoDB 逻辑存储结构
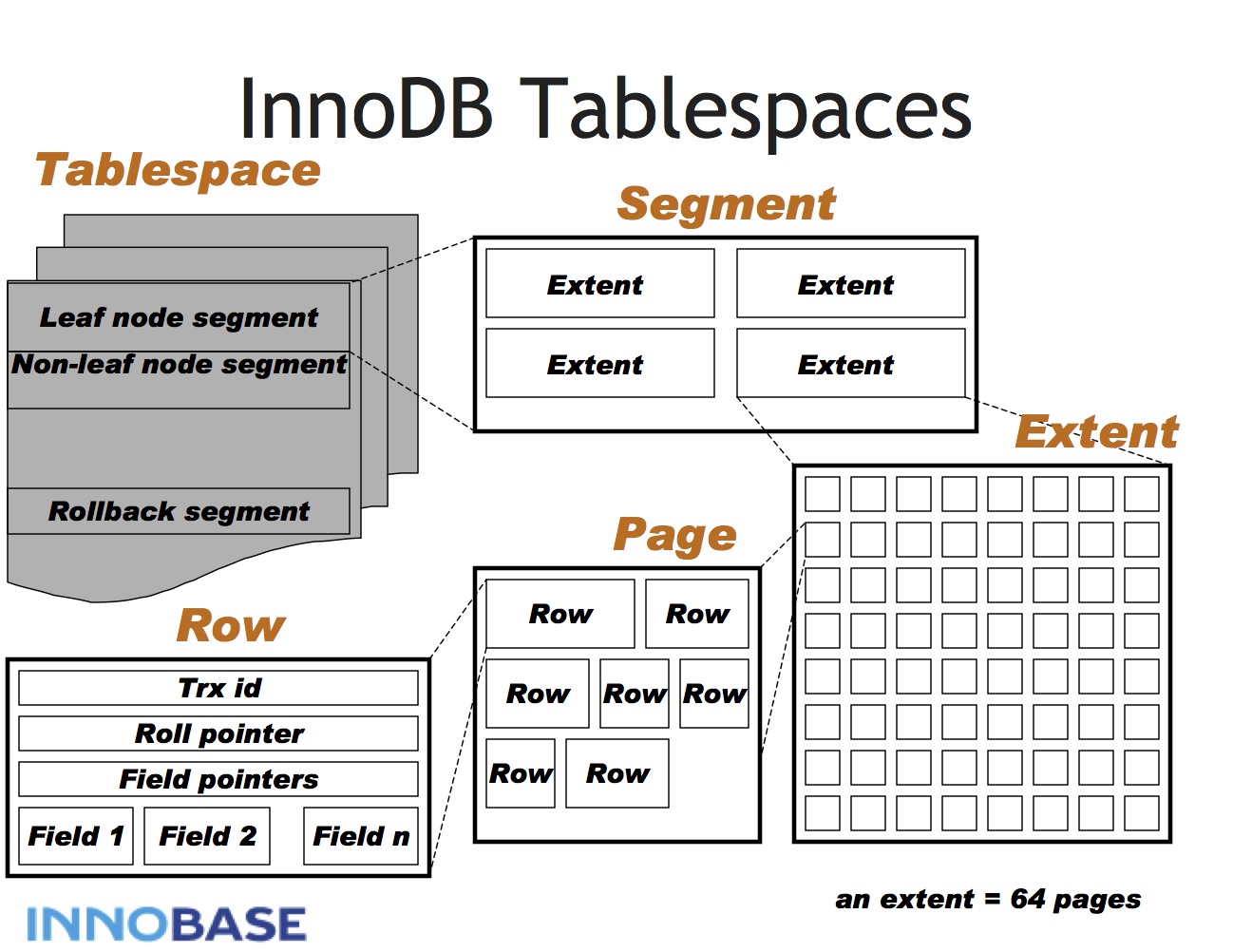
InnoDB page 存储结构
页类型
数据页(B-tree Node)
undo页(undo Log Page)
系统页(System Page)
事务数据页(Transaction system Page)
插入缓冲位图页(Insert Buffer Page)
未压缩的二进制大对象页(Uncompressd BLOB Page)
压缩的二进制大对象页(compressd BLOB Page)
页大小
默认16k(若果没有特殊情况,下面介绍的都是默认16k大小为准)
一个页内必须存储2行记录,否则就不是B+tree,而是链表了
结构图

InnoDB row 存储结构
rows 文件格式总体规划图
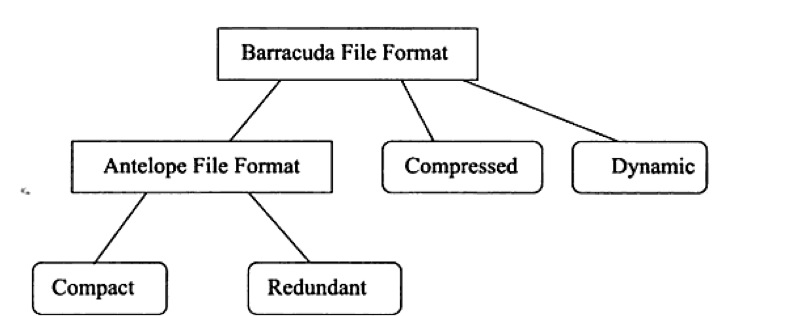
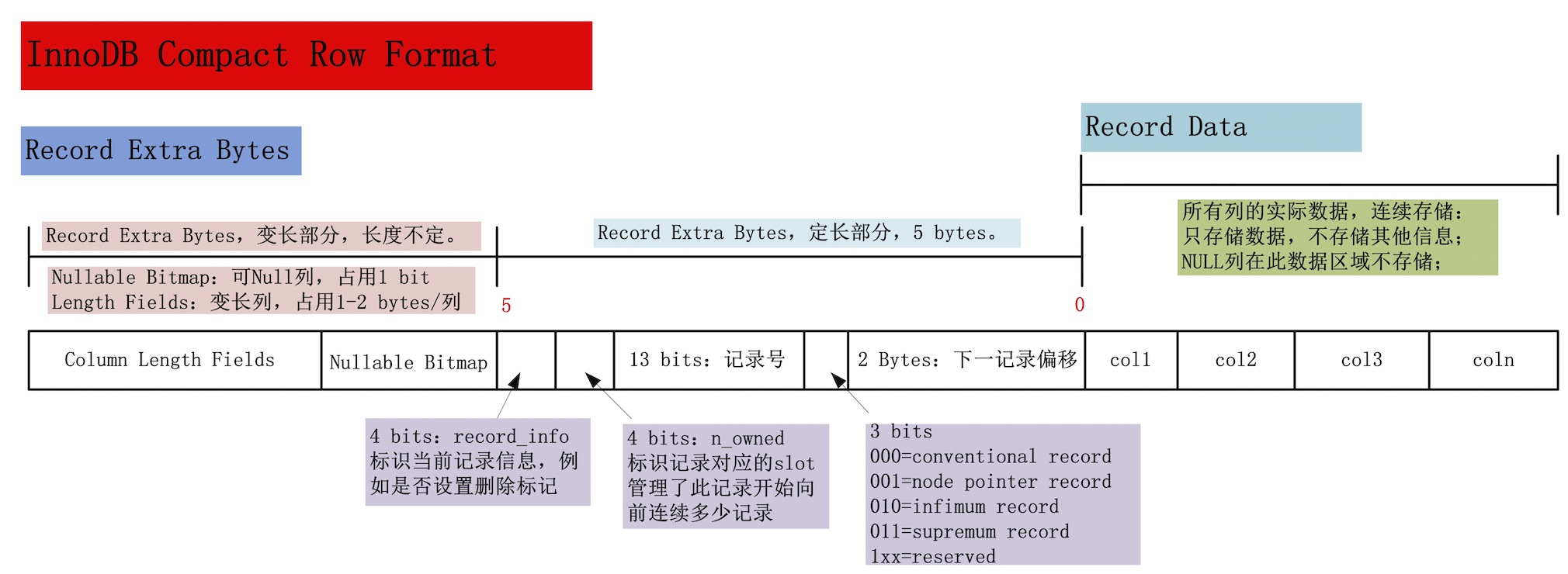
row-fomat为Compact的结构图
row-fomat为Redundant的结构图
不常用
compress & dynamic 与 Compact 的区别之处
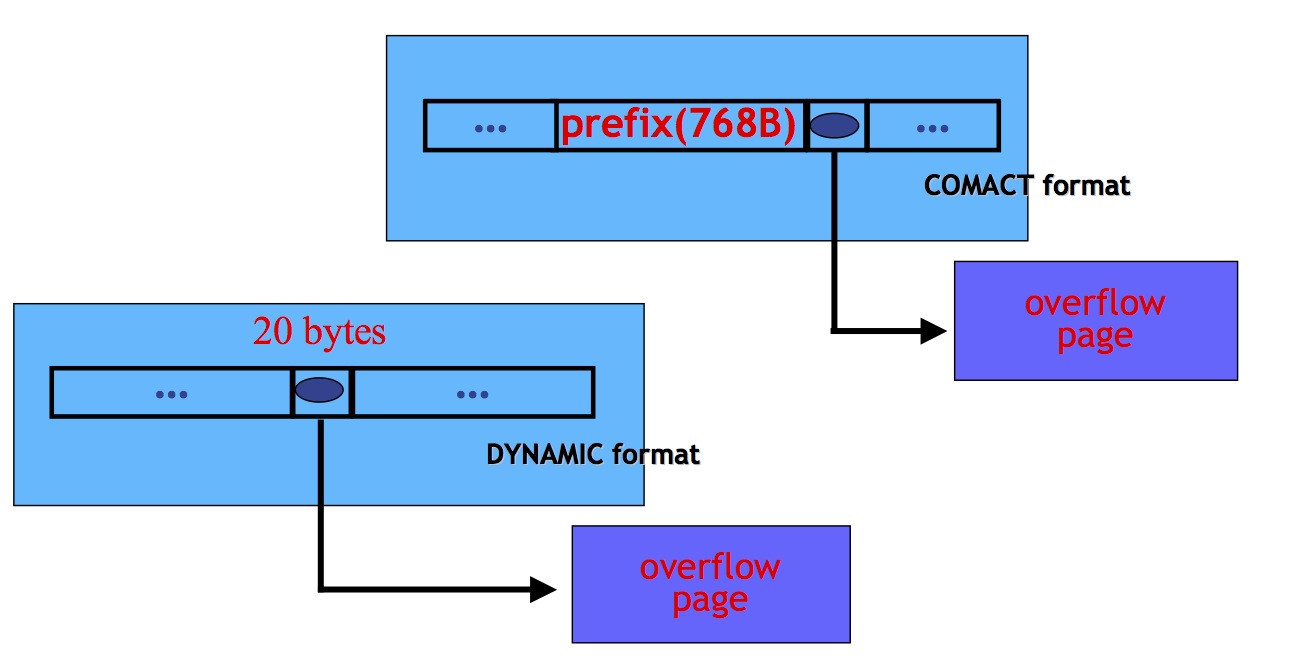
字段之字符串类型
char(N) vs varchar(N)
不管是char,还是varchar,在compact row-format格式下,NULL都不占用任何存储空间
在多字节字符集的情况下,CHAR vs VARCHAR 的实际行存储基本没区别
CHAR不管是否是多字符集,对未能占满长度的字符还是会填充0x20
规范中:对char和varchar可以不做要求
varchar(N) : 255 vs 256
当实际长度大于255的时候,变长字段长度列表需要用两个字节存储,也就意味着每一行数据都会增加1个字节
实测下来存储空间增长并不算大,且性能影响也不大,所以,尽量在256之内吧
varchar(N) & char(N) 的最大限制
char的最大限制是: N<=255
varchar 的最大限制是: N<=65535 , 注意官方文档说的是N是字节,并且说的是一行的所有字段的总和小于65535,而varchar(N)中的N表示的是字符。
测试后发现,65535并不是最大限制,最大的限制是65532
[MySQL 5.6.27]
* char的最大限制是: N<=255
root:test> create table test( a char(65535))charset=latin1 engine=innodb;
ERROR 1074 (42000): Column length too big for column 'a' (max = 255); use BLOB or TEXT instead
* 测试后发现,65535并不是最大限制,最大的限制是65532
root:test> create table test( a varchar(65535))charset=latin1 engine=innodb;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
root:test> create table test( a varchar(65532))charset=latin1 engine=innodb;
Query OK, 0 rows affected (0.00 sec)
* varchar 的最大限制是: N<=65535 , 注意官方文档说的是N是字节,并且说的是一行的所有字段的总和小于65535,而varchar(N)中的N表示的是字符
root:test> create table test_1( a varchar(30000),b varchar(30000),c varchar(5535))charset=latin1 engine=innodb;
ERROR 1118 (42000): Row size too large. The maximum row size for the used table type, not counting BLOBs, is 65535. This includes storage overhead, check the manual. You have to change some columns to TEXT or BLOBs
* varchar(N)中的N表示的是字符
root:test> create table test_1( a varchar(50000))charset=utf8 engine=innodb;
Query OK, 0 rows affected, 1 warning (0.00 sec)
root:test> show warnings;
+-------+------+--------------------------------------------+
| Level | Code | Message |
+-------+------+--------------------------------------------+
| Note | 1246 | Converting column 'a' from VARCHAR to TEXT |
+-------+------+--------------------------------------------+
1 row in set (0.00 sec)
root:test> show create table test_1;
+--------+-------------------------------------------------------------------------------+
| Table | Create Table |
+--------+-------------------------------------------------------------------------------+
| test_1 | CREATE TABLE `test_1` (
`a` mediumtext
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+-------------------------------------------------------------------------------+
1 row in set (0.00 sec)
off-page: 行溢出
- 为什么会有行溢出off-page这个概念呢
假设创建了一张表,里面有一个字段是a varchar(30000) , innoDB的页才16384个字节,如何存储的下呢?所以行溢出就来了嘛
- 如何看出行溢出了?
可以通过姜承尧写的工具查看
其中溢出的页有 Uncompressed BLOB Page: 243453
[root()@xx script]# python py_innodb_page_info.py t.ibd
Total number of page: 537344:
Insert Buffer Bitmap: 33
Freshly Allocated Page: 74040
File Segment inode: 1
B-tree Node: 219784
File Space Header: 1
扩展描述页: 32
Uncompressed BLOB Page: 243453
- 溢出有什么危害
溢出的数据不再存储在B+tree中
溢出的数据使用的是uncompress BLOB page,并且存储独享,这就是存储越来越大的真正原因
通过下面的测试,你会发现,t_long 插入的数据仅仅比 t_short 多了几个字节,但是最终的存储却是2~3倍的差距
* 表结构
root:test> show create table t_long;
+--------+---------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------+---------------------------------------------------------------------------------------------------------+
| t_long | CREATE TABLE `t_long` (
`id` int(11) DEFAULT NULL,
`col1` text
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+---------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
root:test> show create table t_short;
+---------+----------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+----------------------------------------------------------------------------------------------------------+
| t_short | CREATE TABLE `t_short` (
`id` int(11) DEFAULT NULL,
`col1` text
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+----------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
* 测试案例
foreach $num (1 .. 48849){
$sql_1 = "insert into $table_short select $num,repeat('a',8090)";
$sql_2 = "insert into $table_long select $num,repeat('a',8098)";
`$cmd -e " $sql_1 "`;
`$cmd -e " $sql_2 "`;
}
* 最终的记录数
root:test> select count(*) from t_short;
+----------+
| count(*) |
+----------+
| 48849 |
+----------+
1 row in set (0.03 sec)
root:test> select count(*) from t_long;
+----------+
| count(*) |
+----------+
| 48849 |
+----------+
1 row in set (0.02 sec)
* 页类型的比较
[root()@xx script]# python py_innodb_page_info.py /data/mysql_data/test/t_short.ibd
Total number of page: 25344:
Insert Buffer Bitmap: 2
Freshly Allocated Page: 887
File Segment inode: 1
B-tree Node: 24452
File Space Header: 1
扩展描述页: 1
[root()@xx script]# python py_innodb_page_info.py /data/mysql_data/test/t_long.ibd
Total number of page: 60160:
Insert Buffer Bitmap: 4
Freshly Allocated Page: 8582
File Segment inode: 1
B-tree Node: 2720
File Space Header: 1
扩展描述页: 3
Uncompressed BLOB Page: 48849
* 最终大小的对比
[root()@xx test]# du -sh * | grep 'long\|short' | grep ibd
941M t_long.ibd
397M t_short.ibd
* 结论
t_short 的表,在400M左右可以理解,因为 8k * 48849 = 400M
t_long 的表,由于独享48849个Uncompressed BLOB Page,严重浪费空间
- 什么情况下会溢出
原则:只要一行记录的总和超过8k,就会溢出。
所以:varchar(9000) 或者 varchar(3000) + varchar(3000) + varchar(3000),当实际长度大于8k的时候,就会溢出
所以:Blob,text,一行数据如果实际长度大于8k会溢出,如果实际长度小于8k则不会溢出,并非所有的blob,text都会溢出
- 多列总和大字段 vs 一列大字段
多个大字段会导致多次off-page
root:test> show create table t_3_col;
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------+
| Table | Create Table
|
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------+
| t_3_col | CREATE TABLE `t_3_col` (
`id` int(11) DEFAULT NULL,
`col1` varchar(7000) DEFAULT NULL,
`col2` varchar(7000) DEFAULT NULL,
`col3` varchar(7000) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------+
1 row in set (0.00 sec)
root:test> show create table t_1_col;
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
| t_1_col | CREATE TABLE `t_1_col` (
`id` int(11) DEFAULT NULL,
`col1` varchar(21000) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+---------+---------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
root:test>
root:test>
root:test> insert into t_1_col(col1) select repeat('a',21000);
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
root:test>
root:test>
root:test> insert into t_3_col(col1,col2,col3) select repeat('a',7000),repeat('a',7000),repeat('a',7000);
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
[root()@xx script]# python py_innodb_page_info.py /data/mysql_data/test/t_1_col.ibd
Total number of page: 6:
Insert Buffer Bitmap: 1
Uncompressed BLOB Page: 2
File Space Header: 1
B-tree Node: 1
File Segment inode: 1
[root()@xx script]# python py_innodb_page_info.py /data/mysql_data/test/t_3_col.ibd
Total number of page: 7:
Insert Buffer Bitmap: 1
Uncompressed BLOB Page: 3
File Space Header: 1
B-tree Node: 1
File Segment inode: 1
如何对大字段进行优化
如果有多个大字段,尽量序列化后,存储在同一列中,避免多次off-page
将text等大字段从主表中拆分出来,a)存储到key-value中 b)存储在单独的一张子表中,并且压缩
必须保证一行记录小于8k
0809MySQL实战系列:大字段如何优化|数据存储结构的更多相关文章
- memcached实战系列(六)理解Memcached的数据存储方式
Memcached的数据存储方式被称为Slab Allocator,其基本方式是: 1:先把内存分成很多个Slab,这个大小是预先规定好的,以解决内存碎片的问题.启动参数的时候配置进去的不懂得可以参考 ...
- 【mysql】关于InnoDB表text blob大字段的优化
最近在数据库优化的时候,看到一些表在设计上使用了text或者blob的字段,单表的存储空间已经达到了近100G,这种情况再去改变和优化就非常难了 一.简介 为了清楚大字段对性能的影响,我们必须要知道i ...
- ByteArrary(优化数据存储和数据流)
原地址:http://www.unity蛮牛.com/blog-1801-799.html 首页 博客 相册 主题 留言板 个人资料 ByteArrary(优化数据存储和数据流) 分类:unity ...
- Spring Boot干货系列:(八)数据存储篇-SQL关系型数据库之JdbcTemplate的使用
Spring Boot干货系列:(八)数据存储篇-SQL关系型数据库之JdbcTemplate的使用 原创 2017-04-13 嘟嘟MD 嘟爷java超神学堂 前言 前面几章介绍了一些基础,但都是静 ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- kafka 数据存储结构+原理+基本操作命令
数据存储结构: Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的.每个topic又可以分成几个不同的partition(每个topic有几个partitio ...
- Cassandra 的数据存储结构——本质是SortedMap<RowKey, SortedMap<ColumnKey, ColumnValue>>
Cassandra 的数据存储结构 Cassandra 的数据模型是基于列族(Column Family)的四维或五维模型.它借鉴了 Amazon 的 Dynamo 和 Google's BigTab ...
- memcached实战系列(七)理解Memcached的数据过期方式、新建过程、查找过程
1.1.1. 新建Item分配内存过程 1:快速定位slab classid,先计算Item长度 key键长+flag+suffix(16字节)+value值长+结构大小(32字节),如90byte ...
- Redis之数据存储结构
今天去中关村软件园面试,被问到:你做项目用到的Redis处理数据用的什么结构?顿时石化,”用到的结构,不就是key-value嘛,还有什么结构?“.面试官说:“平时除了工作,要加强学习,下面的面试我觉 ...
随机推荐
- Codesys——常用快捷键列表
F1——打开Help文档: F2——打开Input Assistant: F5——执行程序(Start): F9——添加或取消断点(Toggle Breakpoint): F8——单步进入(Step ...
- POJ 2728(最优比率生成树+01规划)
Dese ...
- Codeforces--633D--Fibonacci-ish(暴力搜索+去重)(map)
Fibonacci-ish Time Limit: 3000MS Memory Limit: 524288KB 64bit IO Format: %I64d & %I64u Submi ...
- 杂项-Java:JDBC
ylbtech-杂项-Java:JDBC JDBC(Java DataBase Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访 ...
- [Apple开发者帐户帮助]六、配置应用服务(1.2)Apple Pay:在网络上配置Apple Pay
网上Apple Pay允许用户在您的网络应用中购买商品和服务. 首先在您的开发者帐户中创建一个商家标识符,该标识符可以将Apple Pay唯一标识为能够接受付款的商家.您可以为多个本机和Web应用程序 ...
- 关于Vue.js去掉#号路由
正常启动后访问路由: 中间会自动加入一个#号 去掉#号: 在route文件夹下的index.js中加入mode: 'history', ①: ②: 关于mode说明: 默认值: ‘hash‘(浏览器) ...
- 前端布局神器 display:flex
前端布局神器display:flex 一直使用flex布局,屡试不爽,但是总是记不住一些属性,这里写来记录一下. 2009年,W3C提出了一种新的方案--Flex布局,可以简便.完整.响应式地实现 ...
- 深入理解Redis(一)——高级键管理与数据结构
引语 这个章节主要讲解了三部分内容: 如何设计并管理Redis的键以及与其关联的数据结构: 了解并使用Redis客户端对象映射器: 介绍如何利用大O标记来评估Redis性能. 键与数据结构 键 我们先 ...
- ROS-导航功能-Gazebo
前言:仿真的整体思路,先启动仿真环境,再启动导航功能. 前提:已下载并编译了相关功能包集,如还未下载,可通过git下载:https://github.com/huchunxu/ros_explorin ...
- C#url相关知识
C#中Url地址重定向的方法: 1:Response.Redirect(url); 这个跳转页面的方法跳转的速度不快,因为它要走2个来回(2次postback),但他可以跳转到任何页面,没有站点页面限 ...