supervisor---elasticsearch 采坑回顾
supervisor 是一个可以管理进程的软件,并监控进程状态,异常退出时能自动重启。它是通过fork/exec的方式把这些被管理的进程当作supervisor的子进程来启动,这样只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去即可。supervisor还提供了一个功能,可以为supervisord或者每个子进程,设置一个非root的user,这个user就可以管理它对应的进程。比如我们要用它管理elasticsearch 就可以把管理es的专属用户密码 写入配置文件。
- 网上有很多supervisor的安装教程,也比较简单。这里就不再赘述。开始使用的时候需要先看一看 配置文件 路径:/etc/supervisord.conf 。
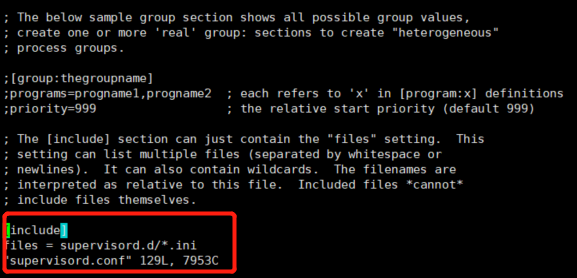
因为我们可能会用 supervisor 管理很多进程 写在一个文件会很大,所以通常需要 每一个 进程独立出一个 以 .ini 为后缀的配置文件 单独管理。
按照配置文件默认的加载路径 supervisord.d/ 下创建了 elasticsearch.ini 文件。
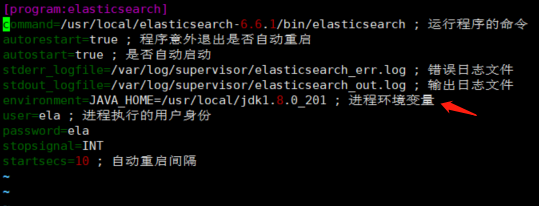
command=/usr/local/elasticsearch-6.6.1/bin/elasticsearch ; 运行程序的命令
autorestart=true ; 程序意外退出是否自动重启
autostart=true ; 是否自动启动
stderr_logfile=/var/log/supervisor/elasticsearch_err.log ; 错误日志文件
stdout_logfile=/var/log/supervisor/elasticsearch_out.log ; 输出日志文件
environment=JAVA_HOME=/usr/local/jdk1.8.0_201 ; 进程环境变量
user=ela ; 进程执行的用户身份
password=ela
stopsignal=INT
startsecs=10 ; 自动重启间隔
写入上图中的配置信息(当时没有写 environment JAVA_HOME 的配置)
所以 执行 supervisorctl reload 、 supervisorctl restart elasticsearch 总是失败。
2、开始排错 (在坑里的感觉真不好)

第一个直觉就是去查看 supervisor的日志了 以为 elasticsearch 根本就没启动 也不会输出 日志

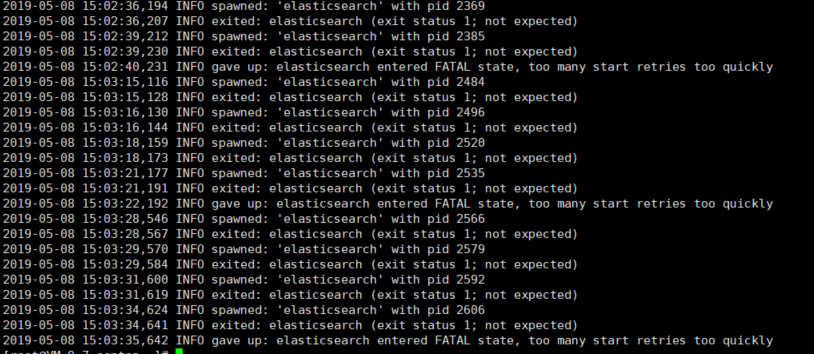
所以一直在查 exit status 1; not expected elasticsearch entered FATAL state, too many start retries too quickly 这个问题 ,然后 会发现管理很多其他的 进程 出错时也会 报这种错 也试了很多 搜到的 解决方法 ,但是结果肯定都不适用。
3、出坑
找解决方法找的 都眼疼了 。 偶然的契机我去 看了眼 elasticsearch.ini 配置文件中 指定的 输出日志 和 错误 输出日志 。惊奇的发现 人家已经默默滴 记录了好多日志啦(手动捂脸) 。
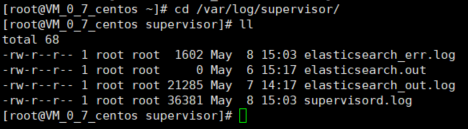
所以 直接打开 error 日志
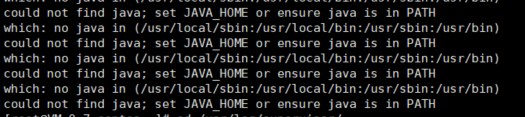
所以 真相浮出水面 直接去配置文件添加 JAVA_HOME 环境变量 再重新reload 、 start 终于运行了。

supervisor---elasticsearch 采坑回顾的更多相关文章
- java采坑之路
判断相等 字符串判断相等 String str1 = null; String str2 = "java金融"; // str1.eq ...
- Redis集群搭建采坑总结
背景 先澄清一下,整个过程问题都不是我解决的,我在里面就是起了个打酱油的角色.因为实际上我负责这个项目,整个过程也比较清楚.之前也跟具体负责的同事说过,等过段时间带他做做项目复盘.结果一直忙,之前做的 ...
- Cloudera Manager 5.9 和 CDH 5.9 离线安装指南及个人采坑填坑记
公司的CDH早就装好了,一直想自己装一个玩玩,最近组了台电脑,笔记本就淘汰下来了,加上之前的,一共3台,就在X宝上买了CPU和内存升级了下笔记本,就自己组了个集群. 话说,好想去捡垃圾,捡台8核16线 ...
- angular采坑记录
在angular中会遇到一些莫名的问题,导致不能完成想要的功能,可能是某项用法使用错误,或许是angular相对应不支持,或者是我们功力根本就没有达到.为了在每次采坑之后能有所收获,再遇到时能理解其根 ...
- 分布式改造剧集之Redis缓存采坑记
Redis缓存采坑记 前言 这个其实应该属于分布式改造剧集中的一集(第一集见前面博客:http://www.cnblogs.com/Kidezyq/p/8748961.html),本来按照顺序 ...
- 采坑:python base64
需求: 读取文本内容,对字符串进行base64加密 >>> str = 'aaaaaaaaaaaaaaaaaaa\nbbbbbbbbbbbbbbbbbbbbbbbbbbb\nccc ...
- Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)
系统:Centos 7,内核版本3.10 本文介绍如何从0利用Docker搭建Hadoop环境,制作的镜像文件已经分享,也可以直接使用制作好的镜像文件. 一.宿主机准备工作 0.宿主机(Centos7 ...
- Spring Cloud Config采坑记
1. Spring Cloud Config采坑记 1.1. 问题 在本地运行没问题,本地客户端服务能连上本地服务端服务,可一旦上线,发现本地连不上线上的服务 服务端添加security登录加密,客户 ...
- rabbitmq在ios中实战采坑
1. rabbitmq在ios中实战采坑 1.1. 问题 ios使用rabbitmq连接,没过多久就断开,并报错.且用android做相同的步骤并不会报错,错误如下 Received connecti ...
随机推荐
- javascript正則表達式
定义一个正則表達式 能够用字面量 var regex = /xyz/; var regex = /xyz/i; 也能够用构造函数 var regex = new RegExp('xyz'); var ...
- AOP代理分析
一:代理 代理类和目标类实现了同样的接口.同样的方法. 假设採用工厂模式和配置文件的方式进行管理,则不须要改动client程序.在配置文件里配置使用目标类还是代理类,这样以后就非常easy切换.(比如 ...
- swift 拼图小游戏
依据这位朋友的拼图小游戏改编 http://tangchaolizi.blog.51cto.com/3126463/1571616 改编主要地方是: 原本着我仁兄的代码时支持拖动小图块来移动的,我參照 ...
- 关于QT版本的安装配置的一些困惑
大概是之前安装和使用QT太顺利了,什么都没注意就开始使用了.在使用VS2012开发Qt5.31的程序一段时间以后,虽然好用,但是发现其编译的程序不能在XP上使用,要打补丁才行.不仅VS2012本身要打 ...
- 查看及改动Oracle编码格式方法
首先查看oracle数据库的编码 SQL> select * from nls_database_parameters where parameter ='NLS_CHARACTERSET ...
- HDU 2665(主席树,无修改第k小)
Kth number Time Limit: 15000/5000 MS (Java/Others) ...
- 删除项目中的版本控制(SVN)
使用svn进行版本控制,每个文件夹下都有.svn文件夹,有些项目在脱离svn版本控制之后,想删除项目中所有的.svn文件夹,可用下面的方法进行快速删除: 建立一个文本文件,取名为kill-svn-fo ...
- Ruby类扩张(extension)
创建: 2017/09/07 更新: 2017/09/16 修改标题字母大小写 ruby ---> Ruby 扩张类 class 类名 扩张的内容 end ...
- E20170826-hm
squash vt. 挤进; 将(某人[某物])压扁; 使沉默; 平定(叛乱等); meld vt. (使) 融合,合并,结合; n. 混合,合并; amend vt. 修订; 改良,修改; a ...
- Play on Words(欧拉路)
http://poj.org/problem?id=1386 题意:给定若干个单词,若前一个的尾字母和后一个单词的首字母相同,则这两个单词可以连接,问是否所有的单词都能连接起来. 思路:欧拉路的判断, ...