hadoop spark 总结
yarn 由,资源管理器rm,应用管理器am appMaster,节点管理器nm 组成!
图侵删

yarn 的设计,是为了代替hadoop 1.x的jobtracker 集中式一对多的资源管理「资源管理,任务监控,任务调度」,而yarn是 分而治之 ,使全局资源管理器减轻压力。
rm 监控每一个applicationmaster就可以了,而每一个applicationmaster则监控 自己node节点的所有任务「跟踪作业状态,进度,故障处理」,所以下降了压力。
rm资源管理器由调度器和应用管理者appmanager 功能模块组成。以调度策略分容量调度器和公平调度器。前者是集群吞吐量利用率最大化,后者基于内存公平的调度。
而应用管理者负责接收提交作业,申请,负责作业容器失败时的重启。
hdfs
1 fsimgae,editlog 都是序列化文件,启动时会加载到内存
记录目录结构和crud等操作
2块的概念,让其支持大规模存储,数据备份和管理。
map reduce VS rdd 技术
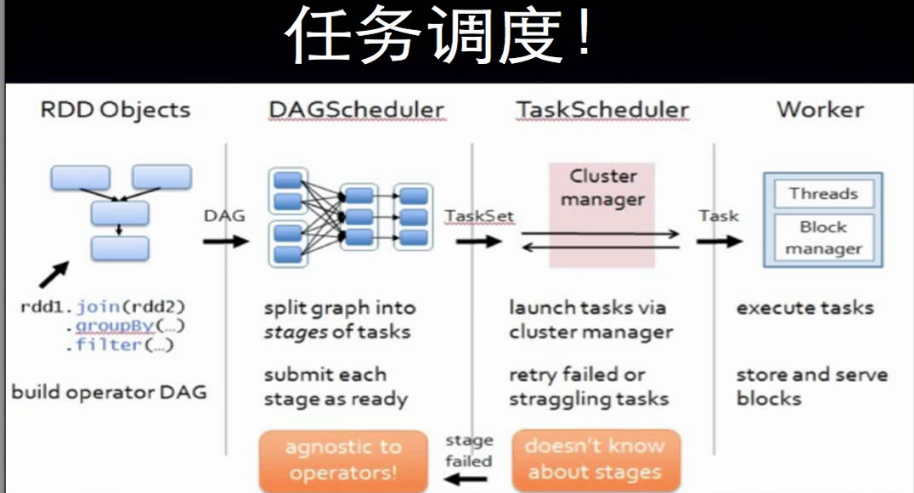
1 创建rdd对象;
2 sparkContext负责计算rdd之间的依赖关系,构建DAG;
3 DAGScheduler负责把DAG图分解成多个阶段,每个阶段包含多个任务,每个任务会被taskScheduler分发给各个工作节点worknode上的executor去执行。
「在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的rdd加入到当前的阶段中」
rdd的窄依赖与宽依赖, 以 父rdd只被一个子rdd依赖 一对一,多对一,区分是窄依赖,否则是宽依赖!
因为这是内存块,如果是窄依赖,则可以完全打包 分成一个线程并发执行! 而如果被其它多个子rdd依赖,即宽依赖,就可能rdd数据会变化,
等等,需要等待之前的阶段完成,才能继续执行!
这就是DAG的设计,比mapreduce快的原因。mapreduce,的reduce业务需要等map 执行完才能开始,而没有并发!这是依赖的!
还有一个原因是,一个是内存,一个是磁盘io。
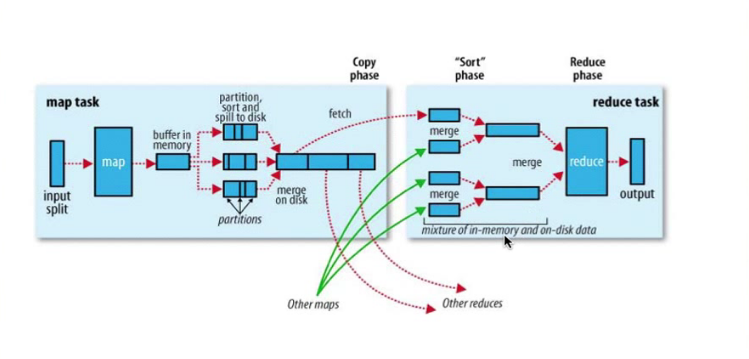
核心思想:分而治之! 把大的数据集分片而小多个 小数据集,对应多个map 并行处理。
结束后,以key value 中间结果,让reduce'减少' 整合,即具有相同的key 的结果分到同一个reduce任务!
整个过程,map输入文件,reduce任务处理结果都是保存到分布式文件系统中,而中间结果则保存到本地存储中,如磁盘。
只有当map处理全部结束后,reduce过程才能开始!
shuffle过程:map的结果,进行,分区,排序,合并等处理并交给reduce的过程,即上图。
map的shuffle:每个map把结果首先写入缓存,当满了就溢写到磁盘,并清空缓存。 为了让不同的reduce方便拿数据,会分好区,map结果会排序合并等操作处理。
reduce的shuffe: 从多个map中领回属于自己处理那部分数据,然后对数据合并merge后给reduce处理。
从学习hadoop和spark 过程,yarn代替jobstracker,spark代替mapreduce,明白,原来高手们写代码,做产品架构设计一开始的时候,也不是完善完美的,
需要先做出来,在实际环境去调优,修正,发现问题,然后解决问题,不断完善甚至改掉原来的架构或思想。
hadoop spark 总结的更多相关文章
- 大数据项目实践:基于hadoop+spark+mongodb+mysql+c#开发医院临床知识库系统
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- 哈,我自己翻译的小书,马上就完成了,是讲用python处理大数据框架hadoop,spark的
花了一些时间, 但感觉很值得. Big Data, MapReduce, Hadoop, and Spark with Python Master Big Data Analytics and Dat ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- 大数据平台搭建(hadoop+spark)
大数据平台搭建(hadoop+spark) 一.基本信息 1. 服务器基本信息 主机名 ip地址 安装服务 spark-master 172.16.200.81 jdk.hadoop.spark.sc ...
- java+hadoop+spark+hbase+scala+kafka+zookeeper配置环境变量记录备忘
java+hadoop+spark+hbase+scala 在/etc/profile 下面加上如下环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_102 expor ...
- hadoop+spark+mongodb+mysql+c#
一.前言 从20世纪90年代数字化医院概念提出到至今的20多年时间,数字化医院(Digital Hospital)在国内各大医院飞速的普及推广发展,并取得骄人成绩.不但有数字化医院管理信息系统(HIS ...
- Hadoop Spark 集群简便安装总结
本人实际安装经验,目的是为以后高速安装.仅供自己參考. 一.Hadoop 1.操作系统一如既往:①setup关掉防火墙.②vi /etc/sysconfig/selinux,改SELINUX=disa ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
随机推荐
- 虚拟机win7 自动休眠
1.问题描述:vmware 虚拟机,windows7系统.当一段时间不操作时,任务会休眠. 2.原因:win7系统自动休眠引起的. 3.解决方法:关闭win7系统的自动休眠. 依次打开“控制面板”-- ...
- [bzoj4385][POI2015]Wilcze doły_单调队列
Wilcze doły bzoj-4385 POI-2015 题目大意:给定一个n个数的序列,可以将连续的长度不超过d的区间内所有数变成0,求最长的一段区间,使得区间和不超过p. 注释:$1\le n ...
- Java下用Jackson进行JSON序列化和反序列化(转)
Java下常见的Json类库有Gson.JSON-lib和Jackson等,Jackson相对来说比较高效,在项目中主要使用Jackson进行JSON和Java对象转换,下面给出一些Jackson的J ...
- 2.4-EN_STP
2.4-EN_STP 增强型生成树协议(EN_STP): Spannig Tree port states: blocking 20s+listening 15s+learning 15s最后 ...
- Eclipse搭建maven开发环境
上一篇学习了maven开发环境的搭建,而且手动编写了一个mavenproject,可是这样子效率非常低下.今天带大家学习在eclipse下搭建maven开发环境. 经常使用的maven命令 mvn c ...
- Android eclipse导入项目后出现Unable to resolve target 'android-17'解决方法
eclipse导入项目后出现Unable to resolve target 'android-17'解决方法.在最后附带还有一种编译逻辑不成功情况解决方法. 一.问题情况 二.解决的方法 1.改动项 ...
- Codeforces Round #281 (Div. 2) C. Vasya and Basketball 排序
C. Vasya and Basketball Vasya follows a basketball game and marks the distances from which each te ...
- poi读写Excel
poi读写Excel 对于一个程序员来说,文件操作是经常遇到的,尤其是对Excel文件的操作. 在这里介绍一下我在项目中用到的一个操作Excel的工具——POI.关于POI的一些概念,网络上很多,详细 ...
- [SpringMVC]定义多个前缀映射的问题
转自:https://penciltim.iteye.com/blog/501073 我在web.xml里面定义多个dispatch-servlet的前缀映射,像下面这样 <!-- Servle ...
- 85.Ext.Window
转自:https://chenjumin.iteye.com/blog/668421 1.主要配置项: closable:是否允许关闭窗口,默认为true. closeActi ...