Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货!
SparkSQL数据源:从各种数据源创建DataFrame
因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的代码优化,生成以及执行流程,所以 sql,dataframe,datasets 的入口都是 sqlContext。
可用于创建 spark dataframe 的数据源有很多:

SparkSQL数据源:RDD
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._ // Define the schema using a case class.
case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table.
val people = sc.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(), p().trim.toInt))
.toDF()
val people = sc
.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)) sqlContext.createDataFrame(people)
SparkSQL数据源:Hive
当从Hive 中读取数据时,Spark SQL 支持任何Hive 支持的存储格式(SerDe),包括文件、RCFiles、ORC、Parquet、Avro,以及Protocol Buffer(当然Spark SQL也可以直接读取这些文件)。
要连接已部署好的Hive,需要拷贝hive-site.xml、core-site.xml、hdfs-site.xml到Spark 的./conf/ 目录下即可
如果不想连接到已有的hive,可以什么都不做直接使用HiveContext:
Spark SQL 会在当前的工作目录中创建出自己的Hive 元数据仓库,叫作metastore_db
如果你尝试使用HiveQL 中的CREATE TABLE(并非CREATE EXTERNAL TABLE)语句来创建表,这些表会被放在你默认的文件系统中的/user/hive/warehouse 目录中(如果你的classpath 中有配好的hdfs-site.xml,默认的文件系统就是HDFS,否则就是本地文件系统)。
SparkSQL数据源:Hive读写
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
SparkSQL数据源:访问不同版本的metastore
从Spark1.4开始,Spark SQL可以通过修改配置去查询不同版本的?Hive metastores(不用重新编译)

SparkSQL数据源:Parquet
Parquet(http://parquet.apache.org/)是一种流行的列式存储格式,可以高效地存储具有嵌套字段的记录。
Parquet 格式经常在Hadoop 生态圈中被使用,它也支持Spark SQL 的全部数据类型。Spark SQL 提供了直接读取和存储Parquet 格式文件的方法。
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._ // Define the schema using a case class.
case class Person(name: String, age: Int) // Create an RDD of Person objects and register it as a table.
val people = sc
.textFile("examples/src/main/resources/people.txt")
.map(_.split(",")).map(p => Person(p(), p().trim.toInt))
.toDF() people.write.parquet("xxxx") val parquetFile = sqlContext.read.parquet("people.parquet") //Parquet files can also be registered as tables and then used in SQL statements.
parquetFile.registerTempTable("parquetFile")
val teenagers = sqlContext.sql("SELECT name FROM parquetFile WHERE age >= 13 AND age <= 19")
teenagers.map(t => "Name: " + t()).collect().foreach(println)
SparkSQL数据源:Parquet-- Partition Discovery
在Hive中通常会用分区表来优化性能,比如:
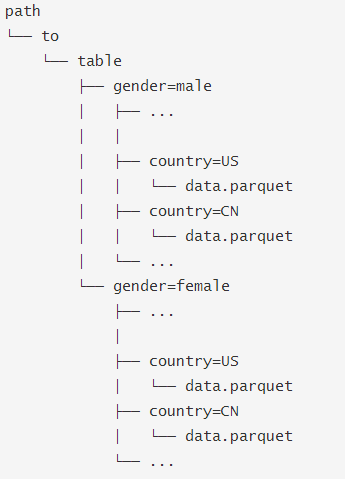
SQLContext.read.parquet或者SQLContext.read.load只需要指定path/to/table,SparkSQL会自动从路径中提取分区信息,返回的DataFrame 的schema 将是:

当然你可以使用Hive读取方式:
hiveContext.sql("FROM src SELECT key, value").
SparkSQL数据源:Json
SparkSQL支持从Json文件或者Json格式的RDD读取数据
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// 可以是目录或者文件夹
val path = "examples/src/main/resources/people.json"
val people = sqlContext.read.json(path) // The inferred schema can be visualized using the printSchema() method.
people.printSchema() // Register this DataFrame as a table.
people.registerTempTable("people") // SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 13 AND age <= 19") // Alternatively, a DataFrame can be created for a JSON dataset represented by
// an RDD[String] storing one JSON object per string.
val anotherPeopleRDD = sc.parallelize("""{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}""" :: Nil)
val anotherPeople = sqlContext.read.json(anotherPeopleRDD)
SparkSQL数据源:JDBC
val jdbcDF = sqlContext.read.format("jdbc")
.options(Map("url" -> "jdbc:postgresql:dbserver","dbtable" -> "schema.tablename"))
.load()
支持的参数:

Spark SQL 编程API入门系列之SparkSQL数据源的更多相关文章
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). VectorSlicer用于从原来的特征 ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- Fragment_动态加载
1.新建Fragment的XML布局文件. 2.在activity.xml中添加需要加载Fragment.列如: <?xml version="1.0" encoding=& ...
- 02--C编程细节整理(一)
用C语言比较多,这篇是平时攒下的.有些内容在工作后可能会很常见,但是不用容易忘,所以就写篇博客吧. 1. printf的用法 %*可以用来跳过字符,可以用于未知缩进.像下面一样. for ...
- (转)基于MVC4+EasyUI的Web开发框架形成之旅--MVC控制器的设计
http://www.cnblogs.com/wuhuacong/p/3284628.html 自从上篇<基于MVC4+EasyUI的Web开发框架形成之旅--总体介绍>总体性的概括,得到 ...
- The features of Swift
The features of Swift are designed to work together to create a language that is powerful, yet fun t ...
- ZBrush带你发掘脸部雕刻的秘诀(上)
骨骼,是一门基础艺术,几百年来一直为伟大的艺术大师所研究,它曾经,也将一直是创作现实且可信角色的关键,提高骨骼知识更将大大提高雕刻技能. 当然,这对于现实角色很重要,对卡通和风格化的角色也同样重要,底 ...
- Java中成员变量和局部变量区别
在类中的位置不同 重点 成员变量:类中,方法外 局部变量:方法中或者方法声明上(形式参数) 作用范围不一样 重点 成员变量:类中 局部变量:方法中 初始化值的不同 重点 成员变量:有默认值 局部变量: ...
- java 常用API 包装 数组的覆盖和遍历
package com.oracel.demo01; public class Sz { public static void main(String[] args) { // TODO Auto-g ...
- 计蒜客 阿里天池的新任务—简单( KMP水 )
链接:传送门 思路:KMP模板题,直接生成 S 串,然后匹配一下 P 串在 S 串出现的次数,注意处理嵌套的情况即可,嵌套的情况即 S = "aaaaaa" ,P = " ...
- Problem 4
Problem 4 # Problem_4 """ A palindromic number reads the same both ways. The largest ...
- 小学生都能学会的python(一)2018.9.3
一,小学生第一天 1,认识和了解python python的创始⼈为吉多·范罗苏姆(Guido van Rossum). python是一门解释性语言 弱类型语言 优点:(1).Python的定位是 ...