Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)
不多说,直接上干货!
特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择)。
VectorSlicer用于从原来的特征向量中切割一部分,形成新的特征向量,比如,原来的特征向量长度为10,我们希望切割其中的5~10作为新的特征向量,使用VectorSlicer可以快速实现。
理论,见
机器学习概念之特征选择(Feature selection)之VectorSlicer算法介绍
完整代码
VectorSlicer .scala
package zhouls.bigdata.DataFeatureSelection import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer//引入ml里的特征选择的VectorSlicer
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType /**
* By zhouls
*/
object VectorSlicer extends App {
val conf = new SparkConf().setMaster("local").setAppName("VectorSlicer")
val sc = new SparkContext(conf) val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._ //构造特征数组
val data = Array(Row(Vectors.dense(-2.0, 2.3, 0.0))) //为特征数组设置属性名(字段名),分别为f1 f2 f3
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]]) //构造DataFrame
val dataRDD = sc.parallelize(data)
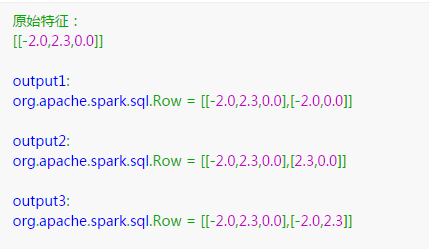
val dataset = sqlContext.createDataFrame(dataRDD, StructType(Array(attrGroup.toStructField()))) print("原始特征:")
dataset.take().foreach(println) //构造切割器
var slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features") //根据索引号,截取原始特征向量的第1列和第3列
slicer.setIndices(Array(,))
print("output1: ")
slicer.transform(dataset).select("userFeatures", "features").first() //根据字段名,截取原始特征向量的f2和f3
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setNames(Array("f2","f3"))
print("output2: ")
slicer.transform(dataset).select("userFeatures", "features").first() //索引号和字段名也可以组合使用,截取原始特征向量的第1列和f2
slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array()).setNames(Array("f2"))
print("output3: ")
slicer.transform(dataset).select("userFeatures", "features").first() }
输出结果是
python语言来编写
from pyspark.ml.feature import VectorSlicer
from pyspark.ml.linalg import Vectors
from pyspark.sql.types import Row df = spark.createDataFrame([
Row(userFeatures=Vectors.sparse(, {: -2.0, : 2.3}),),
Row(userFeatures=Vectors.dense([-2.0, 2.3, 0.0]),)]) slicer = VectorSlicer(inputCol="userFeatures", outputCol="features", indices=[]) output = slicer.transform(df) output.select("userFeatures", "features").show()
Spark MLlib编程API入门系列之特征选择之向量选择(VectorSlicer)的更多相关文章
- Spark MLlib编程API入门系列之特征选择之卡方特征选择(ChiSqSelector)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). ChiSqSelector用于使用卡方检 ...
- Spark MLlib编程API入门系列之特征选择之R模型公式(RFormula)
不多说,直接上干货! 特征选择里,常见的有:VectorSlicer(向量选择) RFormula(R模型公式) ChiSqSelector(卡方特征选择). RFormula用于将数据中的字段通过R ...
- Spark MLlib编程API入门系列之特征提取之主成分分析(PCA)
不多说,直接上干货! 主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法. 参考 http://blo ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- Spark SQL 编程API入门系列之Spark SQL支持的API
不多说,直接上干货! Spark SQL支持的API SQL DataFrame(推荐方式,也能执行SQL) Dataset(还在发展) SQL SQL 支持basic SQL syntax/Hive ...
- Spark SQL 编程API入门系列之SparkSQL数据源
不多说,直接上干货! SparkSQL数据源:从各种数据源创建DataFrame 因为 spark sql,dataframe,datasets 都是共用 spark sql 这个库的,三者共享同样的 ...
- Spark SQL 编程API入门系列之Spark SQL的作用与使用方式
不多说,直接上干货! Spark程序中使用SparkSQL 轻松读取数据并使用SQL 查询,同时还能把这一过程和普通的Python/Java/Scala 程序代码结合在一起. CLI---Spark ...
- Spark SQL 编程API入门系列之SparkSQL的入口
不多说,直接上干货! SparkSQL的入口:SQLContext SQLContext是SparkSQL的入口 val sc: SparkContext val sqlContext = new o ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
随机推荐
- 用 querySelectorAll 来查询 DOM 节点
用 querySelectorAll 来查询 DOM 节点 Document.querySelectorAll - Web API 接口 | MDN https://developer.mozilla ...
- Scaling with Microservices and Vertical Decomposition
Scaling with Microservices and Vertical Decomposition – dev.otto.de https://dev.otto.de/2014/07/29/s ...
- linux 解决 Device eth0 does not seem to be present
在虚拟机中安装cent os系统,然后配置网络 执行命令ifconfig 没有看到eth0的信息: 重启网卡报错: service network restart Shutting down loop ...
- UVA11270 Tiling Dominoes —— 插头DP
题目链接:https://vjudge.net/problem/UVA-11270 题意: 用2*1的骨牌填满n*m大小的棋盘,问有多少种放置方式. 题解: 骨牌类的插头DP. 1.由于只需要记录轮廓 ...
- MYSQL进阶学习笔记三:MySQL流程控制语句!(视频序号:进阶_7-10)
知识点四:MySQL流程控制语句(7-10) 选择语句: (IF ELSE ELSE IF CASE 分支)IFNULL函数 IF语法: 语法规则: IF search_condition THEN ...
- CentOS 7中ip命令将逐渐取代 ifconfig
首先看下图: 要安装ip,请点击这里下载iproute2套装工具 .不过,大多数Linux发行版已经预装了iproute2工具. 你也可以使用git命令来下载最新源代码来编译: $ git clone ...
- Android自动化测试环境搭建
Android自动化环境的搭建主要包括: 1. java jdk和jre的安装和环境的配置 2. appium服务器的安装和配置 3. eclipse开发工具,这里不必要用Android Studio ...
- 【hyddd驱动开发学习】DDK与WDK
最近尝试去了解WINDOWS下的驱动开发,现在总结一下最近看到的资料. 1.首先,先从基础的东西说起,开发WINDOWS下的驱动程序,需要一个专门的开发包,如:开发JAVA程序,我们可能需要一个JDK ...
- C - Woodcutters
Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Description Little ...
- Struts2基本使用
Struts2:本质servlet 1.接受页面参数 a.使用原生的ServletAPI接受(不推荐) request.getParameter(name) 获取元素request方式: --Http ...