10.5ORM回顾(2)
2018-10-5 14:47:57
越努力越幸运!永远不要高估自己!
ORM的聚合和分组查询!!!
# #####################聚合和分组############################
#####################聚合
# 查询所有书籍的价格
from django.db.models import Sum, Count, Avg ret = models.Bool.objects.all().aggregate(price_sum=Sum("price"))
print(ret) # {'price_sum': 'Decimal('554.00')'}
# 查询所有作者的平均年龄
ret = models.Author.objects.all().aggregate(age_avg=Avg("age")) ####----------------------------------------分组
"""
单表分组 emp id name age dep
1 alex 22 保安部
2 egon 33 保安部
1 wenzhou 44 保洁部 sql
select Count(id) from emp group by dep; orm : 对象关系映射
models.emp.objects.values("dep").annotate(c=Count("id"))
# 哪个字段分组,就values谁,然候count 任意一个字段就好了 ######################################################## emp id name age dep_id
1 alex 22 1
2 egon 33 1
1 wenzhou 44 2 dep id name
1 保安部
2 保洁部 查询每一个部门的人数 sql:
select * from emp inner join dep on emp.dep_id= dep.id id name age dep_id dep.id dep.name
1 alex 22 1 1 保安部
2 egon 33 1 1 保安部
1 wenzhou 44 2 2 保洁部 select * from emp inner join dep on emp.dep_id= dep.id group by dep.id, dep.name ORM:
关键点:
1. query对象.annotate()
2. annotate进行分组统计,按照前面select的字段进行group by
3. annotate() 返回值依然是queryset对象, 增加了分组统计之后的键值对 # 先join 表 基表是dep ,然后得到emp里面拿到name数据,跨表 反向 写表名小写,,和queryset跨表查数据一样
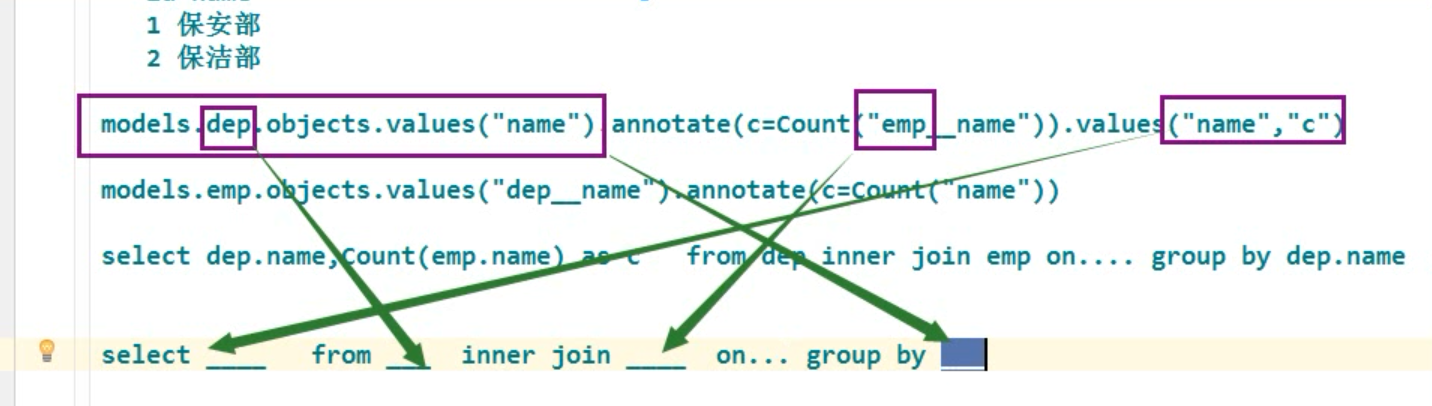
models.dep.objects.all().annotate(Count("emp__name")) models.dep.objects.values("name").annotate(c=Count("emp_name")).values("name", "c") # 反向查询 models.emp.objects.values("dep__name").annotate(c=Count("name")).values("dep_name", "c")) # 正向查询 sql
selcet dep.name, Count(emp.name) as c from dep inner join emp on .......... group by dep.name; 分组查询 先有个轮廓 select Count(emp.name) as c , dep.name from emp inner join dep on .... group by dep.name; select _____ from ____ inner join______ on ........ group by _______________ """ # 查询每一个作者的名字以及出版过的最高价格的书
from djang.db.models import Sum, Count, Max, Avg
ret = models.Author.objects.values("name").annotate(max_price=Max("book_price")).values("name",max_price) """
select Max(book.price) as max_price from author inner join book_authors on ....
inner join book on.....
group by author.name; """
# 查询每一个出版社出版过的书籍的平均价格 # 可以按字段.values("") 也可以直接 .all()
models.Publish.objects.all().annotate(avg_price=Avg("book__price")).values("name", "avg_price") # 查询每一本书籍的作者个数
modes.Book.values("title").annotate(c=Count("authors__name")).values("title","c") # 查询每一个分类的名称以及对应的文章数 models.Category.objects.all().annotate(c=Count("articles__title")).values("title", "c") # 统计不止一个作者的图书名称 """
sql:
# 先分组再统计
select book.title, Count(author.name) as c from book inner join book-authors on ....
inner join author on ....
group by book.id having c >1; """
# filter () 在这里翻译成 having 的意思,,以前的都翻译成 where
models.Book.objects.all().annotate(c=Count("authors__name")).filter(c__gt=1).values("title", "c")
10.5ORM回顾(2)的更多相关文章
- 10.4ORM回顾!
2018-10-4 17:41:52 继续优化一下我的博客项目!! 贴上orm参考连接:https://www.cnblogs.com/yuanchenqi/articles/8963244.html ...
- 数据库_11_1~10总结回顾+奇怪的NULL
校对集问题: 比较规则:_bin,_cs,_ci利用排序(order by) 另外两种登录方式: 奇怪的NULL: NULL的特殊性:
- IT168关于敏捷开发采访
1.我们知道敏捷开发是一套流程和方法的持续改进,通过快速迭代的方式交付产品,从而控制和降低成本.但是在实行敏捷初期,往往看不到很好的效果.这里面,您觉得问题主要出在哪?团队应如何去解决问题?金根:我认 ...
- 如何实现 C/C++ 与 Python 的通信?
属于混合编程的问题.较全面的介绍一下,不仅限于题主提出的问题.以下讨论中,Python指它的标准实现,即CPython(虽然不是很严格) 本文分4个部分 1. C/C++ 调用 Python (基础篇 ...
- "敏捷革命"读书笔记
最近看可一本书 书名叫<敏捷革命>外国著作中文翻译 本来想自己总结读后感但是本书后面都有本章的总结,所以下面都已摘抄为主,以备之后快速浏览 第一章 世界的运作方式已经打破 规划是有用的,而 ...
- C/C++ 与 Python 的通信
作者:Jerry Jho链接:https://www.zhihu.com/question/23003213/answer/56121859来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商 ...
- 《Redis设计与实现》
<Redis设计与实现> 基本信息 作者: 黄健宏 丛书名: 数据库技术丛书 出版社:机械工业出版社 ISBN:9787111464747 上架时间:2014-6-3 出版日期:2014 ...
- 关东升的《从零开始学Swift》3月9日已经上架
大家一直期盼的<从零开始学Swift>于3月9日已经上架,它是关东升老师历时8个月的呕心沥血所编著,全书600多页,此本书基于Swift 2.x,通过大量案例全面介绍苹果平台的应用开发.全 ...
- 关东升的《从零开始学Swift》即将出版
大家好: 苹果2015WWDC大会发布了Swift2.0,它较之前的版本Swift1.x有很大的变化,所以我即将出版<从零开始学Swift> <从零开始学Swift>将在< ...
随机推荐
- Android典型界面设计(5)——使用SlidingMenu和DrawerLayout分别实现左右侧边栏
一.问题描述 侧边栏是Android应用中十分常见的界面效果,可随主屏在左侧或右侧联动,是特别适应手机等小屏幕特性的典型界面设计方案之一,常用作应用的操作菜单,如图所示 实现侧边栏可以使用第三方组件s ...
- SQL Server连接错误1326
全新的SQL Server 2017,在2018年末才安装上,不过使用它来管理并不复杂的几张表,占用相对较多服务器资源,确实是有些大材小用. 无论如何,安装还是比较顺利.记得2012年第一次安装SQL ...
- Jquery计算时间戳之间的差值,可返回年,月,日,小时等
/** * 计算时间戳之间的差值 * @param startTime 开始时间戳 * @param endTime 结束时间戳 * @param type 返回指定类型差值(year, month, ...
- CentOS下防御或减轻DDoS攻击方法(转)
查看攻击IP 首先使用以下代码,找出攻击者IP netstat -ntu | awk '{print $5}' | cut -d: -f1 | sort | uniq -c | sort -n 将会得 ...
- Java Arrays.sort源代码解析
前提: 当用到scala的sortWith,发现: def sortWith(lt: (A, A) ⇒ Boolean): List[A] // A为列表元素类型 根据指定比较函数lt进行排序,且排序 ...
- CPP Note
hello.cpp -> 编译代码g++ hello.cpp -o a -> a.out 区分大小写的编程语言 内置类型 一些基本类型可以使用一个或多个类型修饰符进行修饰: signed: ...
- mysql 物理数据存放
报错误:1030 - Got error 28 from storage engine 3.在系统中查看/tmp是否已经满了: [root@localhost /]# df /tmp/ Filesys ...
- 使用vuejs做一个todolist
在输入框内输入一个list,回车,添加到list列表中,点击列表中的项样式改变 1.index.html <!DOCTYPE html> <html> <head> ...
- Android开发(十四)——SimpleAdapter与自定义控件
ListView中可以使用SimpleAdapter进行数据与视图的绑定,但都是对已有的系统控件的绑定,如果自定义空间直接使用SimpleAdapter绑定,则会报错. 如,使用CircleImage ...
- STM32 多通道ADC采样,采用Timer1进行采样率控制,利用DMA进行传输
http://blog.csdn.net/varding/article/details/17559399 http://www.51hei.com/stm32/3842.html https://w ...