(七)Transformation和action详解-Java&Python版Spark
Transformation和action详解
视频教程:
1、优酷
2、YouTube
什么是算子
算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
算子分类:
具体:
1、Value数据类型的Transformation算子,这种变换并不触发提交作业,针对处理的数据项是Value型的数据。
2、Key-Value数据类型的Transfromation算子,这种变换并不触发提交作业,针对处理的数据项是Key-Value型的数据对。
3、Action算子,这类算子会触发SparkContext提交Job作业。
RDD有两种操作算子:
1、Transformation(转换)
2、Ation(执行)
作用
1、transformation是得到一个新的RDD,方式很多,比如从数据源生成一个新的RDD,从RDD生成一个新的RDD,Transformation属于延迟计算,当一个RDD转换成另一个RDD时并没有立即进行转换,仅仅是记住了数据集的逻辑操作。
2、action是得到一个值,或者一个结果(直接将RDDcache到内存中),触发Spark作业的运行,真正触发转换算子的计算。
所有的transformation都是采用的懒策略,如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。
下图描述了Spark在运行转换中通过算子对RDD进行转换:
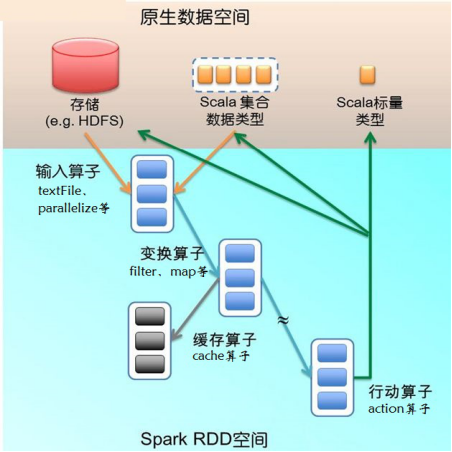
输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
运行:在Spark数据输入形成RDD后便可以通过变换算子,如filter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。 如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中(collect输出到Scala集合,count返回Scala int型数据)。
Transformation和Actions操作概况
Transformation具体内容
1、map(func) :返回一个新的分布式数据集,由每个原元素经过func函数转换后组成。
2、filter(func) : 返回一个新的数据集,由经过func函数后返回值为true的原元素组成 。
3、flatMap(func) : 类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素)。
4、sample(withReplacement, frac, seed) : 根据给定的随机种子seed,随机抽样出数量为frac的数据。
5、union(otherDataset) : 返回一个新的数据集,由原数据集和参数联合而成。
6、groupByKey([numTasks]) : 在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task。
7、reduceByKey(func, [numTasks]) : 在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的。
8、join(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集。
9、groupWith(otherDataset, [numTasks]) : 在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。
10、cartesian(otherDataset) : 笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积。
Actions具体内容
1、reduce(func) : 通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行。
2、collect() : 在Driver的程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让Driver程序OOM。
3、count() : 返回数据集的元素个数。
4、take(n) : 返回一个数组,由数据集的前n个元素组成。注意,这个操作目前并非在多个节点上,并行执行,而是Driver程序所在机器,单机计算所有的元素内存压力会增大,需要谨慎使用。
5、first() : 返回数据集的第一个元素(类似于take(1))。
6、saveAsTextFile(path) : 将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本。
7、saveAsSequenceFile(path) : 将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如Int,Double,String等等)。
8、foreach(func) : 在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互。
(七)Transformation和action详解-Java&Python版Spark的更多相关文章
- (八)map,filter,flatMap算子-Java&Python版Spark
map,filter,flatMap算子 视频教程: 1.优酷 2.YouTube 1.map map是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的J ...
- sparkStreaming的transformation和action详解
根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类 Transformations Window Operations J ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (二)Spark-Linux环境准备-Java&Python版Spark
Spark-Linux环境准备 视频教程: 1.优酷 2.YouTube 硬软件环境 1.虚拟机:VMware Workstation 12 2.虚拟机操作系统:RedHat5u4,单核,1G内存,2 ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- “全栈2019”Java第七十章:静态内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- Protocol Buffer技术详解(Java实例)
Protocol Buffer技术详解(Java实例) 该篇Blog和上一篇(C++实例)基本相同,只是面向于我们团队中的Java工程师,毕竟我们项目的前端部分是基于Android开发的,而且我们研发 ...
随机推荐
- Linux命令:ps,netstat,top
ps ps用于查看当前运行的进程.如果想查看动态的进程信息,可以使用top命令.查看详细命令帮助使用man ps. ps最常用的选项组合就是ps aux: # ps aux USER PID %CPU ...
- HTML5之应用缓存---manifest---缓存使用----Web前端manifest缓存
相信来查这一类问题的都是遇到问题或者是初学者吧! 没关系相信你认真看过之后就会知道明白的 这是HTML5新加的特性 HTML5 引入了应用程序缓存,这意味着 web 应用可进行缓存,并可在没有因特网连 ...
- openresty 前端开发入门六之调试篇
大多数情况下,调试信息,都可以通过ngx.say打印出来,但是有的时候,我们希望打印调试日志,不影响到返回数据,所以系统打印到其它地方,比如日志文件,或者控制台 这里主要用到一个方法就是ngx.log ...
- [原创]MYSQL中利用外键实现级联删除和更新
MySQL中利用外键实现级联删除.更新 MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,要求父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引.在创建索引的时候,可以指定 ...
- vue-router2.0 组件之间传参及获取动态参数
<li v-for=" el in hotLins" > <router-link :to="{path:'details',query: {id:el ...
- IIS访问共享文件详解
前言 公司同事做了一个报表系统,需要做集群部署,本来是一件挺容易的事,但是部署过程中却遇到啦种种蛋疼问题. 问题1.我们的报表使用的是微软的水晶报表,需要上传报表的配置文件,然后水晶报表提供的控件来读 ...
- 【Win 10应用开发】延迟共享
延迟共享是啥呢,这么说吧,就是在应用程序打开共享面板选择共享目标时,不会设置要共享的数据,而是等到共享目标请求数据时,才会发送数据,而且,延迟操作可以在后台进行. 这样说似乎过于抽象,最好的诠释方法, ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(38)-Easyui-accordion+tree漂亮的菜单导航
系列目录 本节主要知识点是easyui 的手风琴加树结构做菜单导航 有园友抱怨原来菜单非常难看,但是基于原有树形无限级别的设计,没有办法只能已树形展示 先来看原来的效果 改变后的效果,当然我已经做好了 ...
- ASP.NET MVC5+EF6+EasyUI 后台管理系统(48)-工作流设计-起草新申请
系列目录 创建新表单之后,我们就可以起草申请了,申请按照严格的表单步骤和分支执行. 起草的同时,我们分解流转的规则中的审批人并保存,具体流程如下 接下来创建DrafContoller控制器,此控制器只 ...
- Angular学习-指令入门
1.指令的定义 从用户的角度来看,指令就是在应用的模板中使用的自定义HTML标签.指令可以很简单,也可以很复杂.AngularJS的HTML编译器会解析指令,增强模板的功能.也是组件化未来的发展趋势, ...