但从谈论性能点SQL Server选择聚集索引键
简单介绍
在SQL Server中,数据是按页进行存放的。而为表加上聚集索引后,SQL Server对于数据的查找就是依照聚集索引的列作为keyword进行了。
因此对于聚集索引的选择对性能的影响就变得十分重要了。本文从旨在从性能的角度来谈聚集索引的选择,但这不过从性能方面考虑。对于有特殊业务要求的表,则须要按实际情况进行选择。
聚集索引所在的列或列的组合最好是唯一的
这个原因须要从数据的存放原理来谈。
在SQL Server中,数据的存放方式并非以行(Row)为单位。而是以页为单位。因此。在查找数据时。SQL Server查找的最小单位实际上是页。
也就是说即使你仅仅查找一行非常小的数据,SQL Server也会将整个页查找出来,放到缓冲池中。
每个页的大小是8K。每个页都会有一个对于SQL Server来说的物理地址。这个地址的写法是 文件号:页号(理解文件号须要你对文件和文件组有所了解).比方第一个文件的第50页。
则页号为1:50。当表没有聚集索引时。表中的数据页是以堆(Heap)进行存放的,在页的基础上,SQL
Server通过一个额外的行号来唯一确定每一行。这也就是传说中的RID。RID是文件号:页号:行号来进行表示的,如果这一行在前面所说的页中的第5行,则RID表示为1:50:5,如图1所看到的。
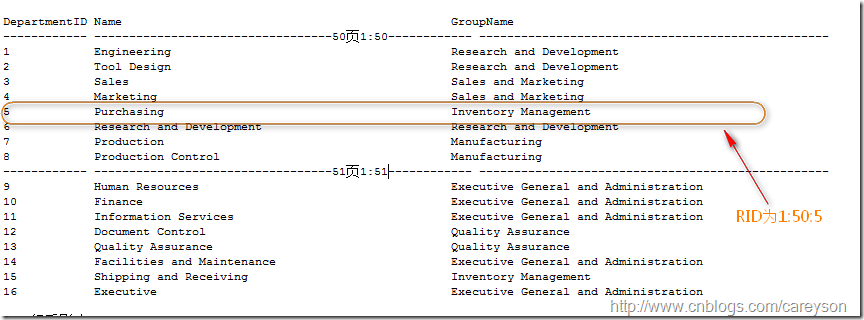
图1.RID的演示样例
从RID的概念来看,RID不不过SQL Server唯一确定每一行的根据,也是存放行的存放位置。当页通过堆(Heap)进行组织时。页非常少进行移动。
而当表上建立聚集索引时,表中的页依照B树进行组织。此时,SQL Server寻找行不再是按RID进行查找,转而使用了keyword,也就是聚集索引的列作为keyword进行查找。如果图1的表中,我们设置DepartmentID列作为聚集索引列。则B树的非叶子节点的行中仅仅包括了DepartmentID和指向下一层节点的书签(BookMark)。
而当我们创建的聚集索引的值不唯一时。SQL Server则无法只通过聚集索引列(也就是keyword)唯一确定一行。
此时。为了实现对每一行的唯一区分,则须要SQL Server为同样值的聚集索引列生成一个额外的标识信息进行区分。这也就是所谓的uniquifiers。
而使用了uniquifier后。对性能产生的影响分为例如以下两部分:
- SQL Server必须在插入或者更新时对如今数据进行推断是否和现有的键反复。假设反复。则须要生成uniquifier,这个是一笔额外开销。
- 由于须要对同样值的键加入额外的uniquifier来区分,因此键的大小被额外的添加了。因此不管是叶子节点和非叶子节点,都须要很多其它的页进行存储。从而还影响到了非聚集索引,使得非聚集索引的书签列变大,从而使得非聚集索引也须要很多其它的页进行存储。
以下我们进行測试,创建一个測试表,创建聚集索引。插入10万条測试数据。当中每2条一反复,如图2所看到的。
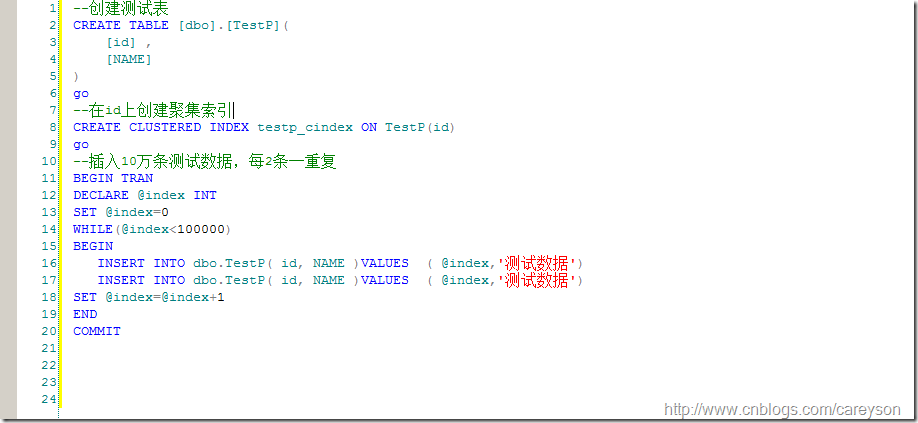
图2.插入数据的測试代码
此时,我们来查看这个表所占的页数,如图3所看到的。
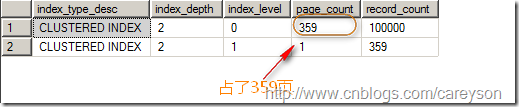
图3.插入反复键后10万数据占了359页
我们再次插入10万不反复的数据,如图4所看到的。

图4.插入10万不反复的建的代码
此时,所占页数缩减为335页,如图5所看到的。
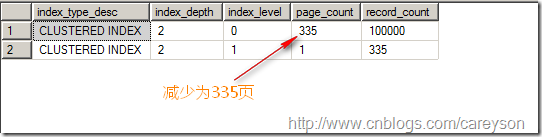
图5.插入不反复键后缩减为335页
因此,推荐聚集索引所在列使用唯一键。
最好使用窄列或窄列组合作为聚集索引列
这个道理和上面降低页的原理一样,窄列使得键的大小变小。
使得聚集索引的非叶子节点降低,而非聚集索引的书签变小,从而叶子节点页变得更少。终于提高了性能。
使用值非常少变动的列或列的组合作为聚集索引列
在前面我们知道。
当为表创建聚集索引后。SQL Server依照键查找行。
由于在B数中,数据是有序的,所以当聚集索引键发生改变时,不只须要改变值本身,还须要改变这个键所在行的位置(RID)。因此有可能使得行从一页移动到还有一页。
从而达到有序。因此会带来例如以下问题:
- 行从一页移动到还有一页,这个操作是须要开销的,不仅如此,这个操作还可能影响到其它行。使得其它行也须要移动位置,有可能产生分页
- 行在页之间的移动会产生索引碎片
- 键的改变会影响到非聚集索引,使得非聚集索引的书签也须要改变。这又是一笔额外的开销
这也就是为什么非常多表创建一列与数据本身无关的列作为主键比方AdventureWorks数据库中的Person.Address表,使用AddressID这个和数据本身无关的列作为聚集索引列,如图6所看到的。而使用AddressLine1作为主键的话,员工地址的变动则可能造成上面列表的问题。
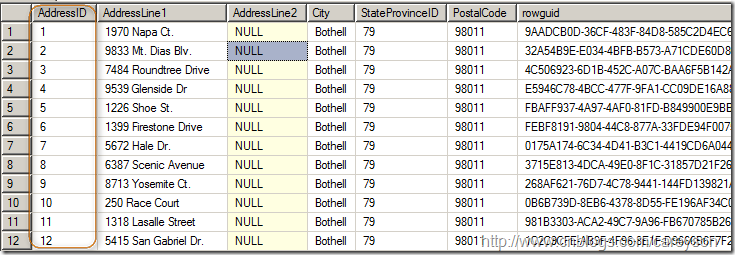
图6.创建和数据本身无关的一列作为聚集索引列
最好使用自增列作为聚集索引列
这个建议也相同推荐创建一个和数据本身无关的自增列作为聚集索引列。我们知道,假设新加入进来的数据假设聚集索引列须要插入当前有序的B树中,则须要移动其他的行来给新插入的行腾出位置。因此可能会造成分页和索引碎片。相同的。还会造成改动非聚集索引的额外负担。而使用自增列,新行的插入则会大大的降低分页和碎片。
近期我碰到过一个情况。一个表每隔几个月性能就奇慢无比。初步查看是因为有大量的索引碎片。但是每隔几个月重建一次索引让我无比厌烦。
终于我发现。问题是因为当时设计数据库的人员将聚集索引建在了GUID上,而GUID是随机生成的,则可能插入到表的不论什么位置,从而大大添加了碎片的数量。
因此造成上面这样的情况。
总结
本文简介了SQL Server存储的原理和应该规避的几种聚集索引建立情况,但这不过从性能的角度谈论一个聚集索引的选择。
对于聚集索引的选择,仍然需要充分考虑的决定。
版权声明:本文博客原创文章,博客,未经同意,不得转载。
但从谈论性能点SQL Server选择聚集索引键的更多相关文章
- SQL查询优化:详解SQL Server非聚集索引(转载)
本文是转载,原文地址 http://tech.it168.com/a2011/1228/1295/000001295176.shtml 在SQL SERVER中,非聚集索引其实可以看作是一个含有聚集索 ...
- T-SQL查询高级--理解SQL SERVER中非聚集索引的覆盖,连接,交叉和过滤
写在前面:这是第一篇T-SQL查询高级系列文章.但是T-SQL查询进阶系列还远远没有写完.这个主题放到高级我想是因为这个主题需要一些进阶的知识作为基础..如果文章中有错误的地方请不吝指正.本篇文章 ...
- SQL Server 非聚集索引的覆盖,连接,交叉和过滤 <第二篇>
在SQL Server中,非聚集索引其实可以看做是一个含有聚集索引的表,但相对实际的表来说,非聚集索引中所存储的表的列数要少得多,一般就是索引列,聚集键(或RID).非聚集索引仅仅包含源表中的非聚集索 ...
- SQL Server的聚集索引和非聚集索引
微软的SQL SERVER提供了两种索引:聚集索引(clustered index,也称聚类索引.簇集索引)和非聚集索引(nonclustered index,也称非聚类索引.非簇集索引)…… (一) ...
- SQL SERVER中非聚集索引的覆盖,连接,交叉,过滤
1.覆盖索引:select和where中包含的结果集中应存在“非聚集索引列”,这样就不用查找基表了,索引表即可搞定: 2.索引交叉:索引的交叉可以理解成建立多个非聚集索引之间的join,如表实体一 ...
- 图解SQL Server:聚集索引、唯一索引、主键
http://www.cnblogs.com/chenxizhang/archive/2010/01/14/1648042.html
- 从性能的角度谈SQL Server聚集索引键的选择
简介 在SQL Server中,数据是按页进行存放的.而为表加上聚集索引后,SQL Server对于数据的查找就是按照聚集索引的列作为关键字进行了.因此对于聚集索引的选择对性能的影响就变得十分重要 ...
- SQL Server性能优化(9)聚集索引的存储结构
一.索引的概念和分类 索引的概念大家都知道,日常开发中我们也会使用常见的聚集索引.非聚集索引.但是除了这两者以外,sqlserver中还提供其他的索引,如: a. 唯一索引:不包含重复键的索引,聚集索 ...
- SQL SERVER全面优化-------索引有多重要?
想了好久索引的重要性应该怎么写?讲原理结构?我估计大部分人不愿意看,也不愿意花那么多时间仔细研究.光写应用?感觉不明白原理一样不会用.举例说明?情况太多也写不全....到底该怎么写呢? 随便写吧,想到 ...
随机推荐
- PHP 文件操作类(创建文件并写入) 生成日志
<?php /** * 文件操作(生成日志)支持多条插入 * (假设插入多条语句并换行 用','逗号分开) * */ class log { public $path = './info.txt ...
- SQL SERVER IN参数化处理
方法一. CREATE TABLE [dbo].[Users] ( Id INTEGER IDENTITY(1, 1) PRIMARY KEY , Name NVARCHAR(50) NOT NULL ...
- java.lang.NoClassDefFoundError: org/apache/juli/logging/LogFactory
Myeclipse 8.6使用tomcat7时间.执行javaweb如报告了以下错误项: java.lang.NoClassDefFoundError: org/apache/juli/logging ...
- 【iOS】彩虹渐变色 的 Swift 实现
首先很感谢大家的支持与关注.<Web Color 的 Swfit 实现>一文一经公布.訪问量迅速攀升,让本人受宠若惊. 为表达感激之情,今天早上把彩虹渐变也顺手实现了. 最新代码& ...
- oracle存储过程的例子
oracle存储过程的例子 分类: 数据(仓)库及处理 2010-05-03 17:15 1055人阅读 评论(2)收藏 举报 认识存储过程和函数 存储过程和函数也是一种PL/SQL块,是存入数据库的 ...
- 【Web探索之旅】第三部分第二课:IP地址和域名
内容简介 1.第三部分第二课:IP地址和域名 2.第三部分第三课预告:协议 第三部分第二课:IP地址和域名 上一课我们说了在Web之中,全球各地有无数台机器,有些充当客户机,有些作为服务器. 那么这些 ...
- 乐在其中设计模式(C#) - 工厂方法模式(Factory Method Pattern)
原文:乐在其中设计模式(C#) - 工厂方法模式(Factory Method Pattern) [索引页][源码下载] 乐在其中设计模式(C#) - 工厂方法模式(Factory Method Pa ...
- [LeetCode66]Plus One
题目: Given a non-negative number represented as an array of digits, plus one to the number. The digit ...
- mybatis 并发问题解决,参考hibernate
时候操作同一账户就是典型的样例. 比方A.B操作员同一时候读取一剩余金额为1000元的账户,A操作员为该账户添加100元.B操作员同一时候为该账户减去 50元.A先提交.B后提交. 最后实际账户剩余金 ...
- zoj 1738 - Lagrange's Four-Square Theorem
称号:四方形定理.输出可以表示为一个数目不超过四个平方和表示的数. 分析:dp,完全背包.背包分割整数.可用一维分数计算,它也可以被写为一个二维团结. 状态:设f(i,j,k)为前i个数字,取j个数字 ...